梁文峰亲自改造,何恺明残差连接量子位
1/1/2026
2026年新年第一天,DeepSeek上传新论文。
给何恺明2016成名作ResNet中提出的深度学习基础组件“残差连接”来了一场新时代的升级。
DeepSeek梁文峰亲自署名论文,共同一作为Zhenda Xie , Yixuan Wei, Huanqi Cao。
残差连接十年未变,扩展之后却带来隐患
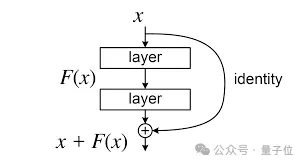
残差连接自2016年ResNet问世以来,一直是深度学习架构的基石。
其核心机制简洁明了,x𝑙+1 = x𝑙 + F (x𝑙 ,W𝑙),即下一层的输出等于当前层输入加上残差函数的输出。
这个设计之所以成功,关键在于“恒等映射”属性,信号可以从浅层直接传递到深层,不经任何修改。
随着Transformer架构的崛起,这一范式已成为GPT、LLaMA等大语言模型的标准配置。
这个设计之所以成功,关键在于“恒等映射”属性,信号可以从浅层直接传递到深层,不经任何修改。
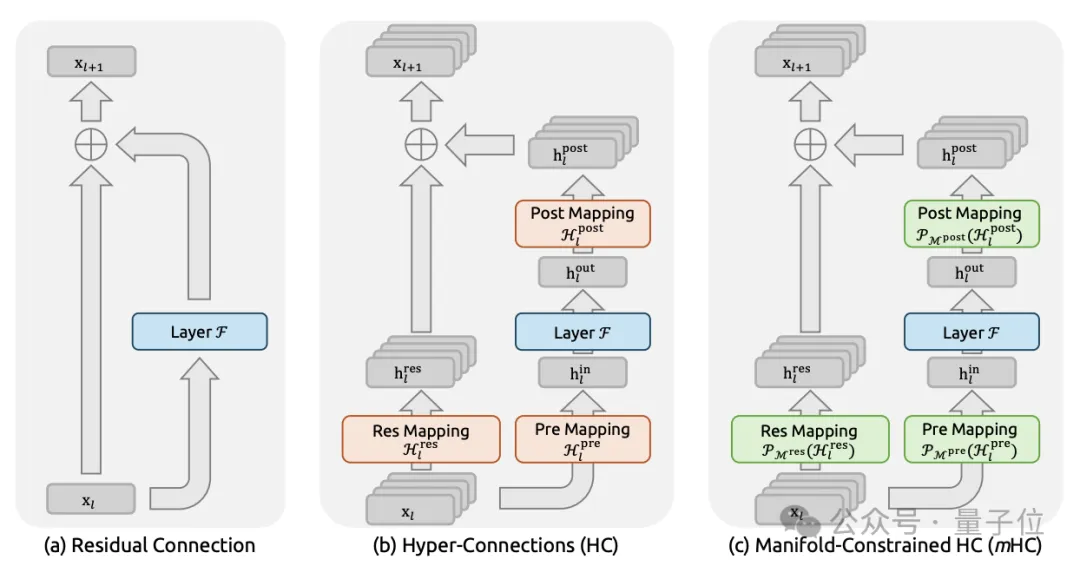
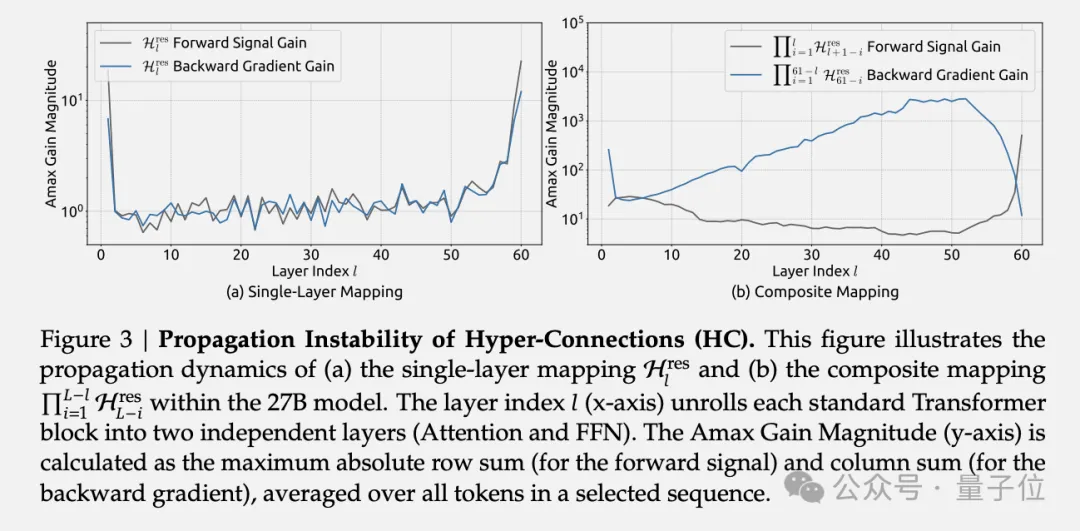
近期出现的Hyper-Connections(HC)试图打破这一格局。HC将残差流的宽度从C维扩展到n×C维,并引入三个可学习的映射矩阵来管理信息流动。
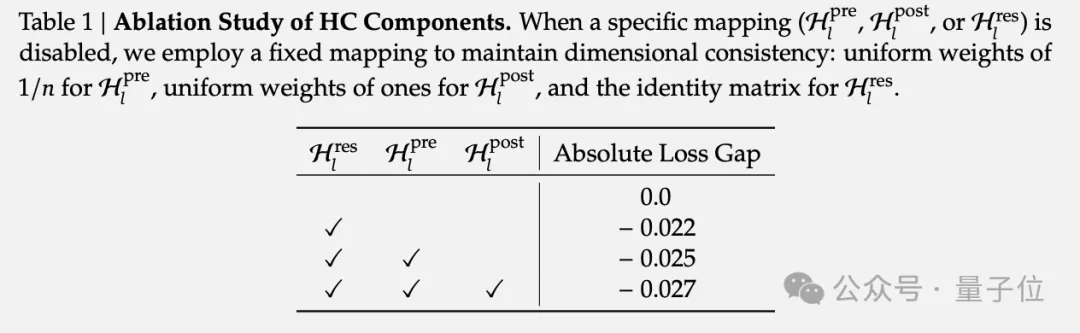
DeepSeek团队的实验表明,在这三个映射中,负责残差流内部信息交换的Hres矩阵贡献了最显著的性能提升。
但问题随之而来,当HC扩展到多层时,复合映射不再保持恒等性质。
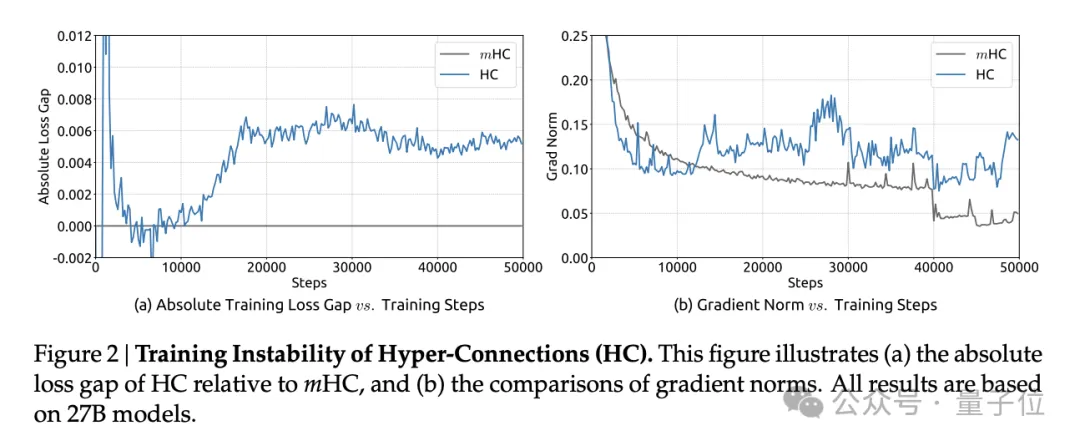
论文中展示的27B模型训练曲线显示,HC在约12000步时出现了突发的损失激增,梯度范数也表现出剧烈波动。
研究团队计算了复合映射对信号的放大倍数:在HC中,这个值的峰值达到了3000,意味着信号在层间传播时可能被放大数千倍,或者相应地被衰减至近乎消失。