贝叶斯先验提炼:快速语言学习CreateAMind
贝叶斯先验提炼:快速语言学习
Modeling rapid language learning bydistilling Bayesian priors into artificial neuralnetworks
贝叶斯先验提炼到人工神经网络中建模快速语言学习
人类能够从极其有限的经验中学习语言。在认知科学中,开发能够解释这种能力的计算模型一直是一项重大挑战。现有方法在解释人类如何在受控环境中快速泛化方面取得了成功,但通常过于受限,难以有效处理自然主义(真实世界)的数据。我们表明,通过一种弥合两种主流建模传统之间鸿沟的方法,可以从有限的自然主义数据中进行学习:即贝叶斯模型与神经网络。该方法将贝叶斯模型的归纳偏置(即指导泛化的因素)提炼到一个具有灵活表征能力的神经网络中。与贝叶斯模型类似,该系统能够从有限数据中学习形式化的语言模式;与神经网络类似,它也能从自然出现的句子中学习英语句法的某些方面。因此,该模型提供了一个统一的系统,既能快速学习,又能处理自然主义数据。
在极其广泛的情境中,人们能够从有限的经验中做出丰富的泛化。这种能力在语言领域尤为明显,使语言成为关于学习机制争论的经典场景。仅凭少量例子,人们就能学习新词的含义¹⁻³、新的句法结构⁴⁻⁷以及新的音系规则⁸⁻¹¹。认知科学的一个核心挑战,就是理解人们如何能从如此稀少的证据中推断出如此丰富的语言知识¹²,¹³。这一难题已被广泛讨论,因而积累了多个不同的名称,包括“刺激贫乏论”(poverty of the stimulus)¹⁴、“柏拉图问题”(Plato’s problem)¹⁵,以及“语言习得的逻辑问题”(the logical problem of language acquisition)¹⁶。
解释快速学习的一种流行方法是使用基于贝叶斯推理的概率模型¹⁷⁻²¹。这些模型对假设如何被表征和选择做出了明确的假设,从而产生强烈的归纳偏置(inductive biases)——即决定学习者如何超越自身经验进行泛化的因素²²。因此,贝叶斯模型特别适合刻画“从少量样本中学习”的能力。例如,Yang 和 Piantadosi 最近提出的一个贝叶斯模型²³表明,仅凭 10 个或更少的例子,就有可能学会句法的许多重要方面。然而,当贝叶斯模型被应用于更大规模的数据集时,它们在假设的设定上面临重大挑战:这些假设既要足够灵活以捕捉数据,又要保持计算上的可处理性。
另一种有影响力的建模方法是使用神经网络²⁴⁻²⁶。这类方法很少对高层结构做出预设,从而具备捕捉现实数据细微差别所需的灵活性。这些系统用数值连接权重的矩阵来表示假设,并通过数据驱动的学习过程,找到最适合当前任务的连接权重。当数据充足时,这种方法极为成功,产生了诸如近期语言模型 ChatGPT²⁷ 等最先进的系统。然而,神经网络的这种灵活性伴随着较弱的归纳偏置,使其在数据稀缺的情境中表现不佳。
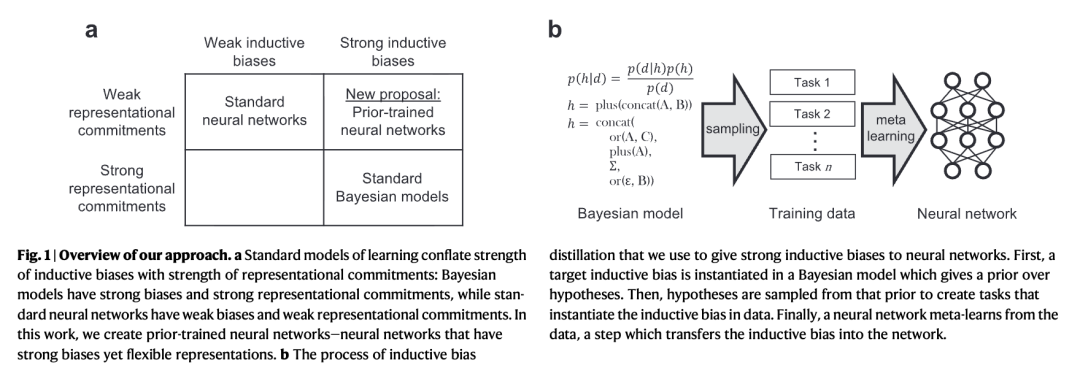
我们认为,要解释从自然主义(真实世界)数据中进行快速学习的能力,需要将表征(representations)与归纳偏置(inductive biases)解耦。原则上,这两个因素是相互独立的,但在历史上,特定类型的归纳偏置总是与特定类型的表征捆绑在一起(见图 1a):适用于快速学习的强归纳偏置,历来伴随着对表征形式的强约束(如贝叶斯模型);而弱表征约束(即能灵活处理复杂的自然主义数据)则历来伴随着弱归纳偏置(如神经网络)。原则上,将这两个因素解耦,就有可能构建一个兼具强归纳偏置和弱表征约束的系统,使其像人类一样,在不牺牲构建更复杂假设能力的前提下实现快速学习。然而在实践中,究竟什么样的系统能同时具备这两种特性,目前仍远非显而易见。
在本研究中,我们展示了如何将贝叶斯模型的归纳偏置“蒸馏”(distill)到神经网络中。我们的方法利用了元学习(meta-learning)领域近期²⁸,²⁹的技术进展。元学习是一种机器学习技术,系统通过接触多种任务,自动发现一种归纳偏置,从而更轻松地学习新任务³⁰,³¹。在我们的元学习应用中,这些任务是从一个贝叶斯模型中采样的,从而将该贝叶斯模型的归纳偏置蒸馏到神经网络中。我们将这一过程称为“归纳偏置蒸馏”(inductive bias distillation),其结果是一个兼具贝叶斯模型强归纳偏置和神经网络灵活性的系统。
我们使用这种方法构建了一个语言学习模型。之所以选择这一案例,是因为语言学习是一个经典问题,长期以来被认为需要结构化的符号表征,因此对基于神经网络的方法构成了严峻的考验。在数据有限的情境下(例如从小量例子中学习人工形式语言),我们模型的表现接近 Yang & Piantadosi 的贝叶斯学习器——该模型是首个被证明能在未针对特定语言现象进行大量定制的情况下,仅凭有限数据学会此类语言的模型。因此,尽管我们的模型是一个神经网络,但其蒸馏而来的归纳偏置使其在神经网络通常难以胜任的环境中取得了成功,达到了此前只有使用符号表征的模型才能实现的性能水平。此外,由于我们的模型本质上是神经网络,它还足够灵活,能够处理贝叶斯模型难以应对的情境:从一个包含 860 万词的语料库中学习英语句法的某些方面。我们的结果表明,融合贝叶斯模型与神经网络各自优势不仅是可能的,而且具有显著益处。
模型:归纳偏置蒸馏
如图 1b 所示,归纳偏置蒸馏通过三个步骤将一种归纳偏置(称为“目标偏置”)蒸馏到一个模型(称为“学生模型”)中。
第一步,用一个贝叶斯模型来定义目标偏置,该模型的先验分布(prior)给出一个任务分布。
第二步,从该分布中采样大量任务。
第三步,学生模型通过元学习(meta-learning)从这些采样任务中学习,从而获得有助于更轻松学习新任务的归纳偏置。
通过控制贝叶斯模型,我们就能控制学生模型通过元学习所获得的归纳偏置。
这种方法具有高度通用性:目标偏置可以由任何可采样的分布来刻画,而学生模型可以是任何能够进行元学习的系统。在我们的具体案例中,每个任务都是一种语言,因此被蒸馏的归纳偏置是在语言空间上的一个先验分布³²。我们的学生模型是一个神经网络,这意味着我们将贝叶斯模型中的语言先验蒸馏到了神经网络中。该方法扩展了我们此前的概念验证工作³³:此处我们使用一个结构化的概率模型来定义归纳偏置,并在人工语言和自然主义语言两种情境下对模型进行了测试。在本节余下部分,我们将详细描述在语言学习案例中所采用的具体形式的归纳偏置蒸馏方法。
步骤 1:刻画归纳偏置
我们的起点是 Yang 和 Piantadosi 提出的用于在形式语言(formal languages)上构建先验的模型²³。形式语言³⁴⁻³⁷ 是由抽象规则定义的一组字符串。例如,集合 {AB, ABAB, ABABAB, …} 就是一个形式语言,由表达式 (AB)+ 定义,表示一个或多个 AB 的重复。用于定义形式语言的机制受到自然语言结构的启发。(AB)+ 的情形类似于英语中嵌套介词短语所体现的尾递归(tail recursion):如果我们将 A 视为一个介词,B 视为一个名词短语,那么 (AB)+ 就能捕捉介词与名词短语交替出现的字符串,例如 “under the vase on the table in the library”(在图书馆桌子上的花瓶下)。通过将语言结构转化为精确的抽象形式,形式语言长期以来为语言的数学分析提供了便利³⁸⁻⁴¹。
在我们的研究中,形式语言的数学特性使其非常适合用于定义语言上的分布。遵循 Yang 和 Piantadosi 所采用的一般方法,我们指定了一个形式化的基本元素(primitives)集合,并构建了一个模型,该模型以概率方式组合这些基本元素,从而生成语言的定义。我们所使用的基本元素主要取自正则表达式(regular expressions)⁴² 中的标准组件——正则表达式是一种特定的形式语言表示法。这些基本元素的例子包括“拼接”(concatenation)和前述的“递归”基本元素“plus”(表示一个或多个重复)。例如,由我们基本元素定义的一种语言是 concat(A, plus(C), or(F,B)),它表示由一个 A 开头,后接一个或多个 C,再接 F 或 B 的字符串集合:{ACF, ACB, ACCF, ACCB, ACCCF, …}。正则表达式的表达能力是有限的:已有证明表明,它们无法捕捉自然语言句法的某些方面⁴³。为克服这些限制,我们以增强系统表达能力的方式对基本正则表达式基本元素进行了扩充。有关我们所用基本元素的完整描述,请参见“方法”部分和补充方法(Supplementary Methods)。
我们对语言的完整分布是通过一个概率模型(其结构类似于概率上下文无关文法)来指定的,该模型定义了对我们所有可能的基本元素组合的概率分布。这种方法为使用较少基本元素定义的语言分配较高的概率,而为描述更复杂的语言分配较低的概率。因此,我们希望通过该模型蒸馏的归纳偏置,是倾向于那些能用我们选定的基本元素简洁表达的语言。通过使用概率模型来指定目标偏置,我们使该偏置具备了可解释性和可控性——如果像 Abnar 等人⁴⁴所做的那样,用神经网络来定义目标偏置(即在不同类型神经网络之间迁移归纳偏置),这些性质将无法保证。
步骤 2:采样数据
既然我们已将归纳偏置刻画为一个语言上的分布,下一步就是从该分布中采样语言,以便学生模型能够从这些语言中进行元学习。这一步是直接的,因为该分布是作为一个生成模型定义的,这自然允许我们从中采样语言,然后从每种语言中进一步采样具体的字符串。尽管操作简单,但这一步在概念上至关重要:它通过将目标偏置具体化为数据,弥合了我们的概率模型与神经网络之间的鸿沟——数据成为两种本截然不同的模型之间的共同基础。
步骤 3:应用元学习
归纳偏置蒸馏的最后一步是让学生模型从我们采样的数据中进行元学习,从而赋予其目标偏置。我们所使用的学生模型是一种长短期记忆神经网络(LSTM;参考文献 45)。已有形式化研究证明,LSTM 能够处理多种类型的形式语言⁴⁶,并且在自然语言处理任务中也取得了显著的实证成功⁴⁷⁻⁴⁹。我们也尝试使用 Transformer⁵⁰——另一种在语言任务中表现优异的神经网络——但我们发现,对于 Transformer,蒸馏效果不如 LSTM 显著,很可能是因为在捕捉我们基本元素所依赖的某些形式语言机制方面,LSTM 的表现优于 Transformer⁵¹。