新评测泼冷水:别再吹AI搞科研了量子位
12/27/2025
如今,大模型在理解、推理、编程等方面表现突出,但AI的“科学通用能力”(SGI)尚无统一标准。
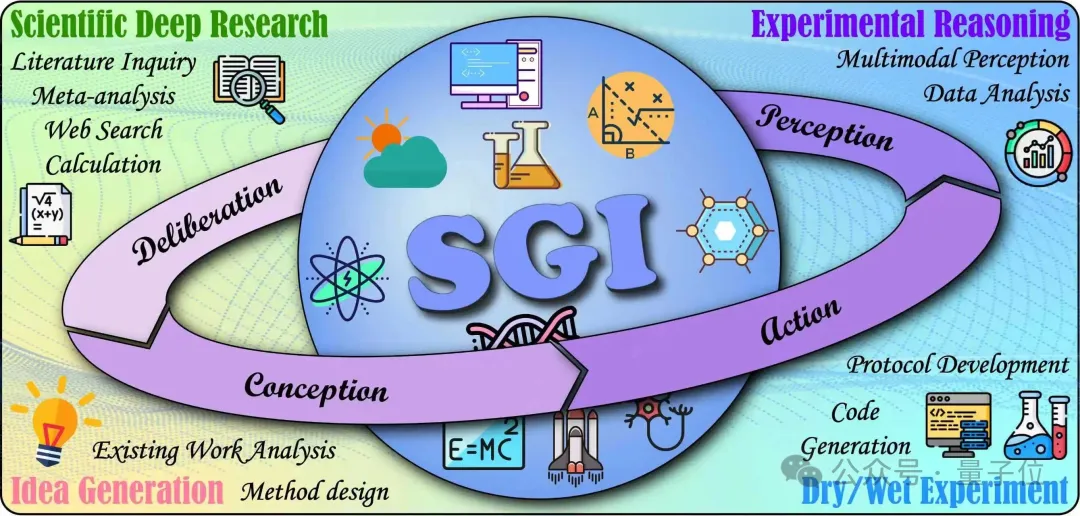
SGI强调多学科、长链路、跨模态与严谨可验证性,而现有基准仅覆盖碎片能力(如学科问答、单步工具操作),难以反映真实科研中的循环与自纠错。为此,上海人工智能实验室通过引入实践探究模型(PIM),将科学探究拆解为四个循环阶段,并与AI能力维度对应:
审思/深度研究(Deliberation):复杂问题下的检索、证据综合与批判评估;
构思/创意生成(Conception):提出新假说与可执行研究方法;
行动/实验执行(Action):将想法转化为计算代码(干实验)与实验室流程(湿实验);
感知/结果解读(Perception):整合多模态证据并进行因果、比较等分析推理。
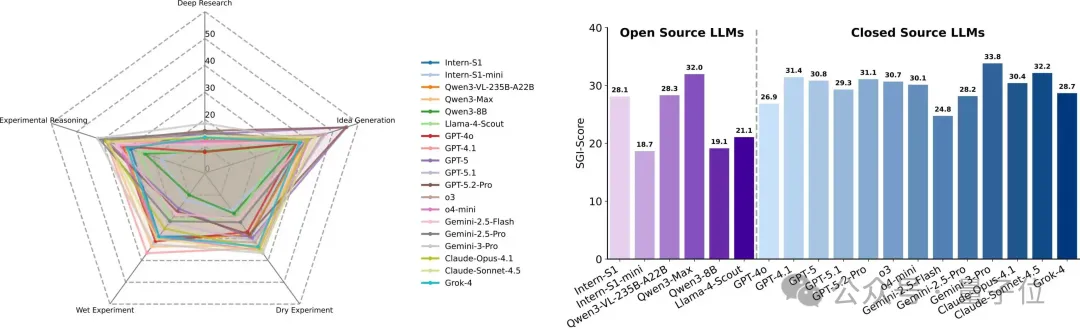
团队将上述四维能力的综合定义为SGI,并发布覆盖全流程的SGI‑Bench。首轮结果:闭源模型Gemini‑3‑Pro以SGI‑Score 33.83/100取得SOTA,但距离“会做研究”的门槛仍显著不足。
SGI-Bench:以科学家工作流对齐的全流程评测