让AI像人类画家一样边画边想量子位
12/22/2025
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。
但当你要求模型处理复杂的空间关系、多物体交互或精准的数量控制时,它们往往会“露怯”:不是把猫画到了窗户外面,就是把三个苹果画成了四个。
为了解决这个问题,学术界此前主要有两条路:
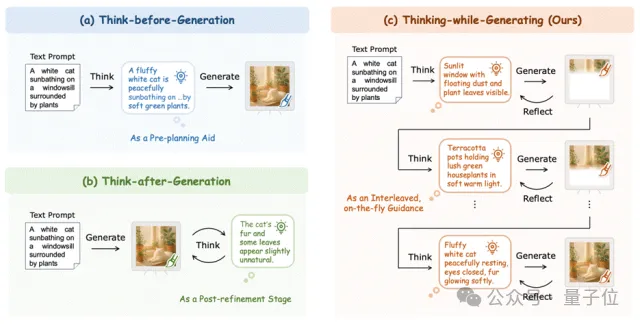
一条是“谋定而后动”(Think-before-Generation),即在画第一笔之前,先写好详细的布局计划。但这就像让画家在动笔前必须把每一笔都想得清清楚楚,一旦开画就无法更改,缺乏灵活性。
另一条是“亡羊补牢”(Think-after-Generation),即先把图画完,再通过多轮对话来挑错、修改。这虽然有效,但往往意味着巨大的推理开销和漫长的等待时间。
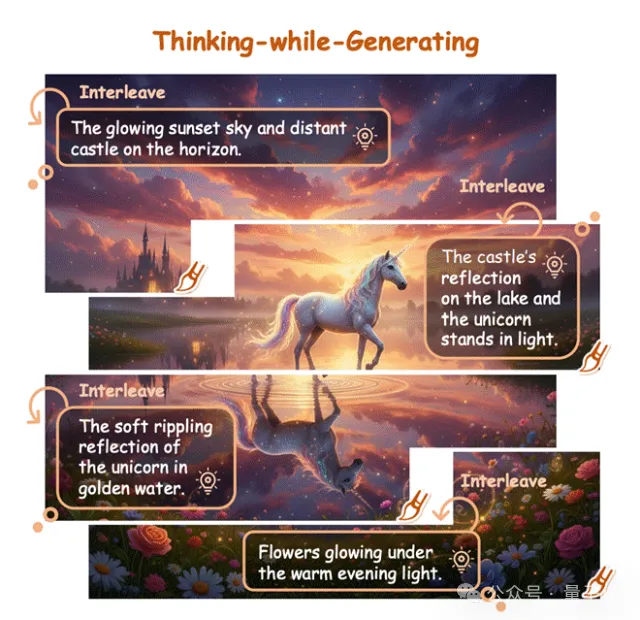
那么,有没有一种方法,能让模型像人类画家一样,在作画的过程中停下来看一眼,既能审视刚才画得对不对,又能为下一笔做好规划?
近日,来自香港中文大学、美团等机构的研究团队提出了一种全新的范式——Thinking-while-Generating(TwiG)。这是首个在单一生成轨迹中、以局部区域为粒度,将文本推理与视觉生成深度交织(Interleave)的框架。
什么是Thinking-while-Generating?