OpenAI塌房!Scaling law原作曝bug 万亿算力白烧
DeepMind研究员深夜爆料:OpenAI的Scaling Law原始论文竟有致命bug!全球AI白白烧掉万亿算力,GPT-3其实严重「虚胖」。
OpenAI误导了整个AI圈好几年!
过去五年,整个AI行业都被Scaling Law推着往前冲。
奥特曼坚信AGI的底气就来自这条曲线。
现在,有人站出来说:这条曲线,一开始就错了。
不是事后诸葛。说这话的,是当年就在OpenAI做大模型优化的研究员Diogo Almeida。
刚刚,他发出一篇博客,标题冷得发指——《Scaling Laws, Honestly》。
开头一句直接把话说死:最初那版scaling law是错的,因为存在一个bug。
传送门:https://www.completeskeptic.com/p/scaling-laws-honestly
DeepMind那位以扩散模型封神的Sander Dieleman,转头就在推特上把它顶了上去,说这是一段有意思的LLM往事:
原始scaling law因为一个bug而错了,大概率害得业界在一堆「体量过大、训练不足」的模型上,白白烧掉了海量算力。
一个bug,烧掉两年。
当bug被撕开,我们看到的,不仅是算力的黑洞,更是一条被语言本身重塑的、远比想象中更深刻的智能边界。
Scaling Law竟是LLM版「地心说」
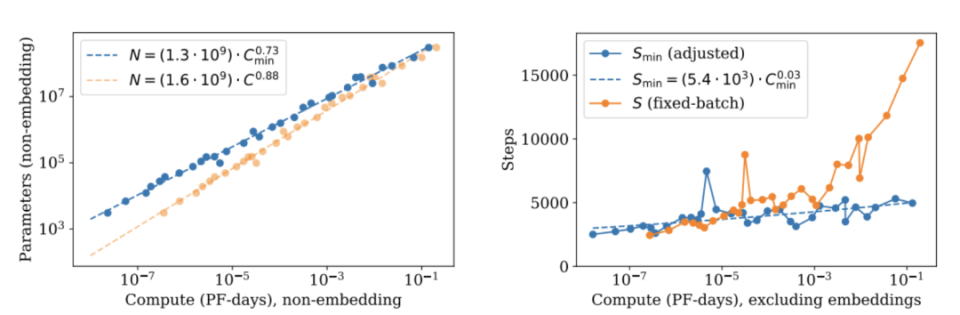
2020年,OpenAI给出结论:在固定的算力预算下,你应该优先把模型做大,而不是拿更多数据去喂它。
用公式说,最优参数量正比于算力的0.73次方——参数,是那个更该猛冲的变量。
这句话,直接定义了GPT-3那一代的长相。堆参数。往死里堆。1750亿。
它告诉全世界的开发者:别问,问就是堆参数;只要你把模型做得足够大,神迹就会发生。
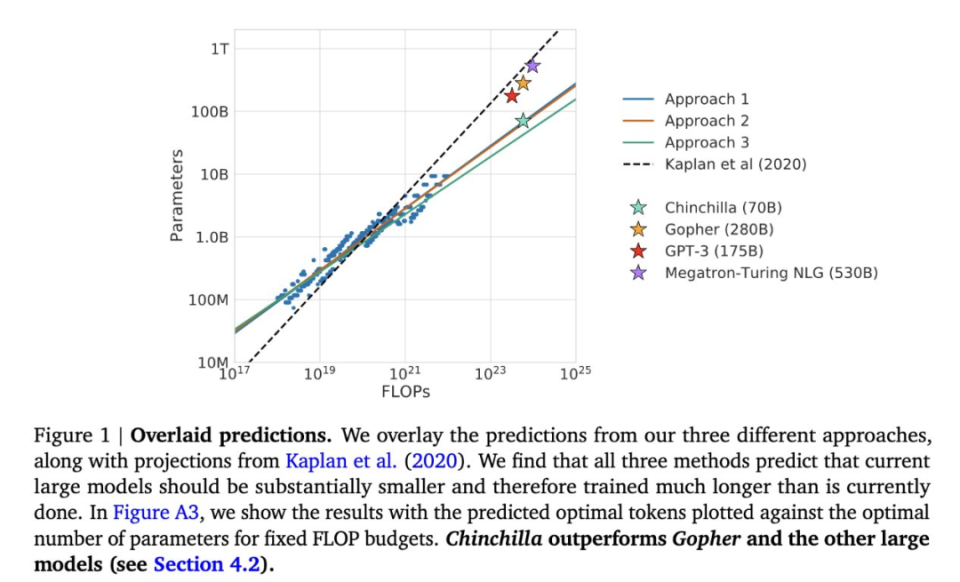
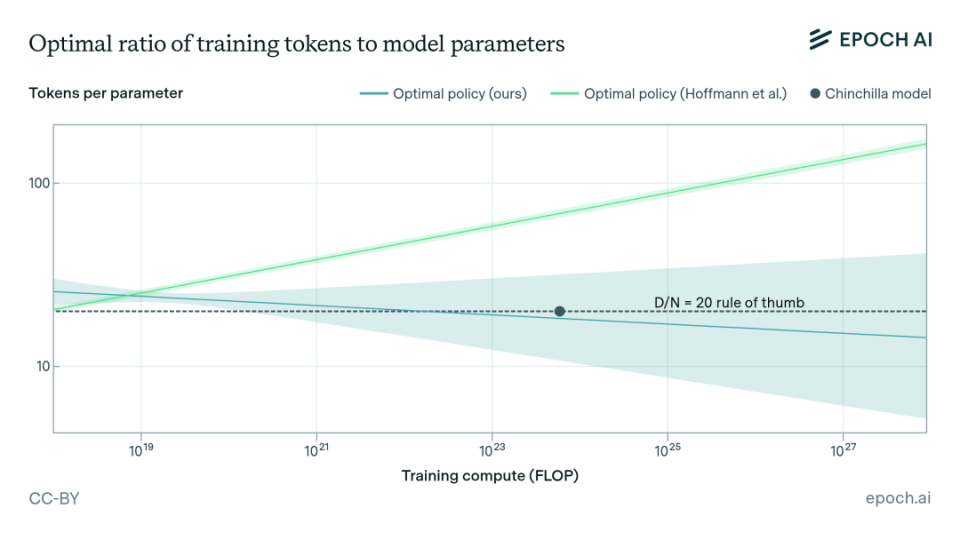
两年后,DeepMind甩出Chinchilla,把这个结论掀了个底朝天:模型和数据,应该差不多同等重要地一起放大,大约每个参数配20个token才划算。
他们训了一个700亿参数的Chinchilla,喂了1.4万亿token——体量不到GPT-3的一半,数据是它的四倍多。
结果,同样的算力预算,全面反超2800亿参数、却只喂了3000亿token的Gopher。
翻译成人话:同样一笔钱,一个把它养成了"虚胖"的壮汉,一个把它练成了精瘦的拳手。
拖更三年,北大校友翁荔深入探讨了后续研究中对两者差异的主流解释,即差异在于他们计算参数总数的方式。
而这还没完。就连「正确」的那个Chinchilla,自己也不干净。
2024年,Besiroglu等人把Chinchilla原文的数据点扒出来重跑,发现它自己那套拟合里也藏着bug:
优化器里的loss尺度设得过高,把Huber损失按样本求了平均、而不是求和,导致拟合过早终止。
纠正bug的论文,自己带着另一个bug。
到这儿,那句被无数人挂在嘴边的「第一性原理」,忽然有点站不住了。
所谓Scaling Law,从来就不是牛顿三定律那种铁打的物理规律,它只是一条经验拟合出来的曲线。
当Diogo Almeida认为真相并非如此,不是方法不一样,「是最初那版scaling law本身有个bug。」
OpenAI三招骗了全球AI同行?
要制造一个让全球AI集体相信的谎言,只需要三步。
第一步:囚禁数据。
OpenAI论文给所有模型——不管它是还在学习走路的孩子(小模型),还是已经长成巨人的模型,喂了完全相同的「饭量」。大约130B tokens数据。
小模型因此被「喂饱」甚至「撑到」,而真正需要海量数据来填满其容量的大模型,却在同一token预算下严重营养不良。
上下滑动查看
Chinchilla论文后来一针见血地指出:他们对所有模型使用了「对所有模型使用了固定的训练Token数和学习率调度方案。」(fixed number of training tokens and learning rate schedule)。
这就像让幼儿园小朋友和博士生用同一张试卷、同一时间考试,然后宣称「成绩只与天赋有关」。
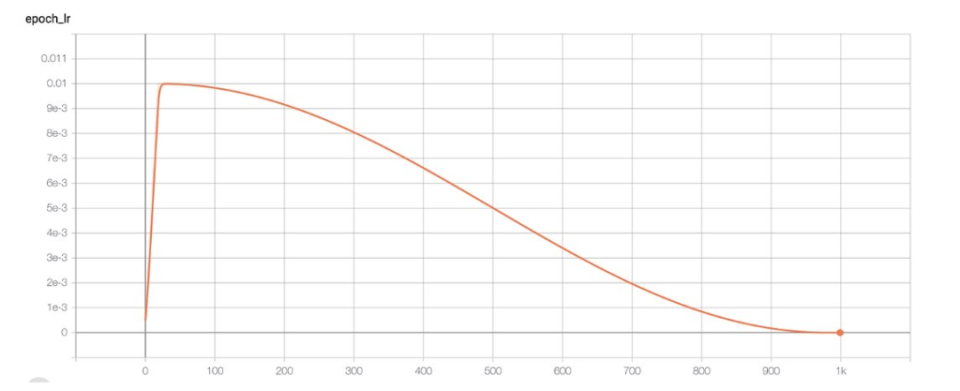
第二步:掩耳盗铃的LR衰减。
他们使用了余弦学习率衰减(Cosine Decay),让学习率在训练接近终点时平滑地趋近于零。
训练快到预设的终点时,学习率被人为地一点点摁到零,模型的进步自然就「平」下来了。
曲线一走平,看上去就像:这模型已经学到头了,再喂也没用了。
研究者们于是得出结论:「加数据没用了,模型已经饱和。」
这不是模型的极限,这是学习率把模型的成长之路人为掐断。它制造出一种完美的假象:性能已经到达天花板,再加数据也无用。
可我们现在知道,那些大模型根本没到头。
第三步:权威的傲慢。
第三步,也是最阴的一步:论文里写了一句,结果「基本不受学习率曲线影响」(largely independent of learning rate schedule)。
虽然包括当时在OpenAI的Diogo Almeida的不少人都隐约感觉到不对劲,但在固定token上限下,这个结论技术上正确。
可它偏偏不适用于scaling law真正想描述的那个「数据无限」的理想世界。
他们把有限条件下的局部真理,当成了普适的宇宙法则。
三步叠在一起,你就得到了一条既错、又极难debug的定律。
连Diogo自己都承认:当年他也在OpenAI做优化,也没看出这个bug——那条学习率曲线看着太像是「精心设定」的了,谁会去怀疑呢。
GPU被白白浪费
算力错配严重
受OpenAI错误公式的指引,AI行业进入了「大力出奇迹」的时代。
这意味着在过去的几年里,全球最聪明的头脑、最稀缺的算力,都浪费在了无效的规模扩张上。
这不仅仅是钱的问题,这是在通往AGI(通用人工智能)的生死时速中,人类因学习率设置,集体在错误的跑道上狂奔了数千公里。
如果说Bug的发现让人心痛,那么随后引出的深度反思则让人不寒而栗。
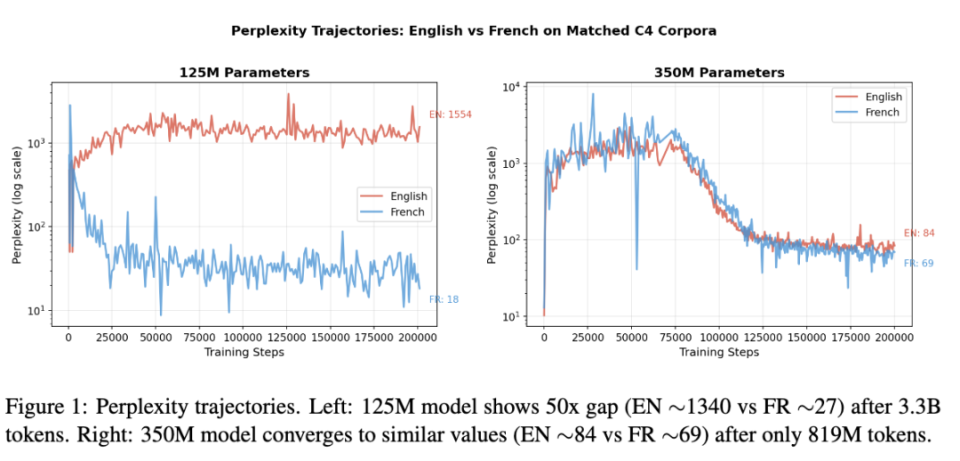
研究者Adam Zachary Wasserman指出了一个被所有人忽略的盲点:即便公式修正了,目前的Scaling Law也只是「英语Scaling Law」。
他做了一个反直觉的实验:用同样的架构、同样的算力训练模型。
结果发现,法语模型达到某种语法能力的效率,竟然比英语模型高出50到100倍。
为什么?因为英语是一种「形态贫乏」的语言。
它太依赖分布规律,需要模型在海量数据中去猜词义;而像法语、中文这种形态丰富或结构严密的语言,在词汇本身就带有大量明确信息。
这意味着,我们现在所有的算力配比方案,都是基于一种最「吃数据」、最低效的语言制定的。
当你以为你在探索「通用智能」的物理定律时,你其实只是在测量「英语这门语言有多浪费算力」。
这就像是你试图通过研究一头猪的胃口来制定全宇宙生物的营养标准——这不仅是偏见,更是认知的局限。
我们本可以用更小的模型、更多的优质数据,实现更强的性能。
我们本可以节省下数以万计的H100运行时的电力和热量。
我们本可以提前两年进入「高效AI」时代。