天下苦DRAM久矣半导体行业观察
DRAM价格暴涨,已成AI算力部署关键瓶颈,根源在于HBM持续挤占产能。价格倒逼技术路线转向:AMD以AI调度冷数据至闪存,Apple将模型常驻NAND,Marvell以硬件压缩扩容,闪迪推HBF新架构。纯DRAM堆砌时代结束,AI推理转向多层内存架构,以分层策略平衡性能与成本。
当前,数据中心正面临一场新危机——不是算力不够,而是内存太贵。
近年来,随着大模型推理、内存数据库、高性能计算等AI业务的规模化快速扩张,正在将数据中心推向内存资源的临界点。曾经作为服务器标配组件的DRAM,如今已成了最昂贵、最稀缺的基础设施资源,价格暴涨与供给刚性,成为制约着AI算力部署节奏的关键因素。
根据Counterpoint Research的追踪数据显示,64GB DIMM内存的价格在2025年第三季度到2026年第一季度之间已上涨3.5倍,且涨势尚未见顶——预计到2026年第三季度,累计涨幅将达到5倍。
TrendForce的数据更加直观:2026年第一季度DRAM合约价季增幅度高达93%至98%,带动全球DRAM产业整体营收环比增长81%,达到970亿美元。进入第二季度,涨势仍未停歇,合约价预计再涨58%至63%。
现货市场的信号更为直观:当前服务器级DDR5 RDIMM的现货单价区间达每GB 27至37美元,仅搭建一个12TB的内存池,纯DRAM硬件采购成本就接近50万美元。
DRAM危机,全面爆发
这轮涨价风暴的根源,在于HBM对DRAM产能的持续蚕食。
据相关数据披露,随着AI训练与推理对高带宽内存的需求爆发,HBM在DRAM晶圆产能中的占比已从2020年的2%攀升至2026年预估的25%。三星、SK海力士、美光三大原厂纷纷将优质产能向高毛利的HBM倾斜,2025至2027年HBM投片量占整体DRAM投片量的比例分别为18%、22%和约30%。一片HBM晶圆要消耗约三片DDR5的产能,三大原厂主动削减手机、PC的低毛利订单,把产能全力倒向AI。再考虑到超大规模云厂商又以多年期长单提前锁定未来晶圆产出,进一步压缩了面向服务器领域的标准DRAM供给。
而供给端的刚性,决定了短缺难以在短期内缓解。
先进DRAM制程高度依赖EUV光刻机,单台设备售价高达约2亿美元,一座现代化晶圆厂的投资动辄数百亿美元,即便一切顺利,建设周期也长达数年。产能扩张的速度,远远追不上AI需求增长的脚步。
杰富瑞预计,若不计入国产厂商影响,2026年全球存储bit供给增长仅为7%至8%。DRAM与NAND合计可能出现约15万至20万片/月的供给缺口。美光科技在2026第三财季财报中表示,即使行业供应可能在2028年逐步改善,目前仍难以判断存储供给何时能够追上持续增长的需求。
此外,压力早已从数据中心蔓延至消费端。
Xbox首席执行官Asha Sharma公开表示,过去两年间内存成本上涨了约五倍,直接导致公司无法生产足够数量的游戏主机来满足市场需求。苹果也宣布相继对iPhone、Mac、iPad等产品进行涨价。
摩根士丹利分析师Shawn Kim团队更是直言,内存价格飙升与供应稀缺正演变为数字经济的全面风险,“从AI基础设施的瓶颈,蔓延至硬件利润率、设备可负担性、云成本、通胀乃至政策层面”。
在服务器物料清单中,DRAM的占比变化更能说明问题。2023年,DRAM约占服务器整机成本的50%;到2026年年中,这一比例已攀升至60%至90%,平均约75%。CPU的价格并没有下降,但在内存价格飞涨的映衬下,CPU的涨价幅度显得微不足道。
更讽刺的是,花了大价钱采购的内存,实际利用率并不高——Meta等超大规模厂商的实测数据显示,数据中心的内存普遍仅有约一半容量承载着活跃的“热数据”,大量冷数据长期占据着昂贵的DRAM资源。
面对DRAM的昂贵与稀缺,行业玩家开始另辟蹊径——不再单纯堆硬件,而是用技术手段减少对DRAM的依赖。
AMD:AI预测调度,让闪存“隐身”成内存
AMD选择了最轻量的软件切入路径。
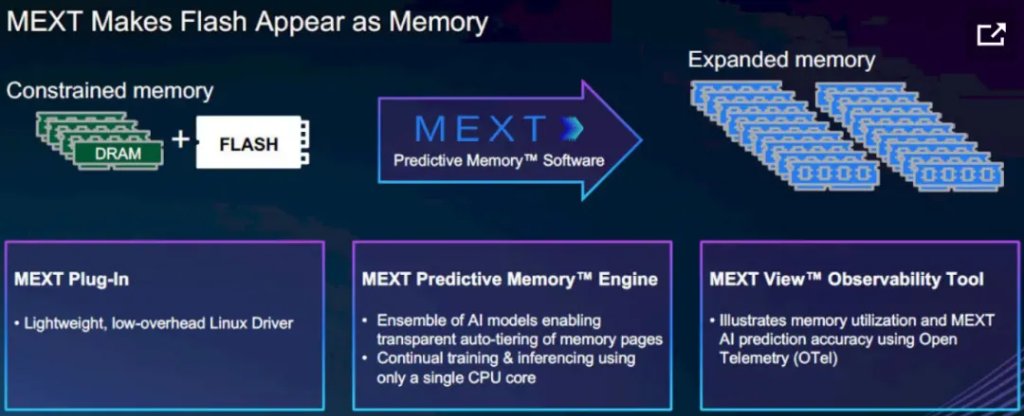
2026年6月,AMD宣布收购内存优化厂商MEXT,其核心目标就是引入通过AI驱动的内存分层技术,将冷数据从高价DRAM下沉到低成本NAND闪存,实现有效内存容量的低成本扩张。
据悉,MEXT成立于2023年,创始团队大有来头——联合创始人兼CEO Gary Smerdon曾是Fusion-io的首席战略和产品官,将闪存存储大规模商业化的先行者,十多年前,苹果和Meta Platforms都是其主要客户。
MEXT针对内存效率瓶颈,推出了一项基于AI的分层内存(memory tiering)技术。这项技术能将低频率访问的数据,从昂贵的DRAM移转至每单位容量成本远低的NAND型闪存,且不影响应用程序运作。
MEXT的核心产品是预测内存引擎(Predictive Memory Engine),一套完全基于软件的内存分层方案:它以内存页为粒度持续监测应用的访问模式,自动将低频访问的冷数据迁移到NAND闪存中——闪存每比特成本仅约为DRAM的1/55;同时通过AI模型学习工作负载的访问规律,预测即将被调用的数据页,在应用发起请求前就主动将其预取回到DRAM,让软件能够像直接访问主存储器般读取数据,进而确保效能不受影响。
图源:Nextplat
整套机制对操作系统和上层应用完全透明,无需修改任何业务代码,也不需要新增专用硬件,数分钟即可完成部署。
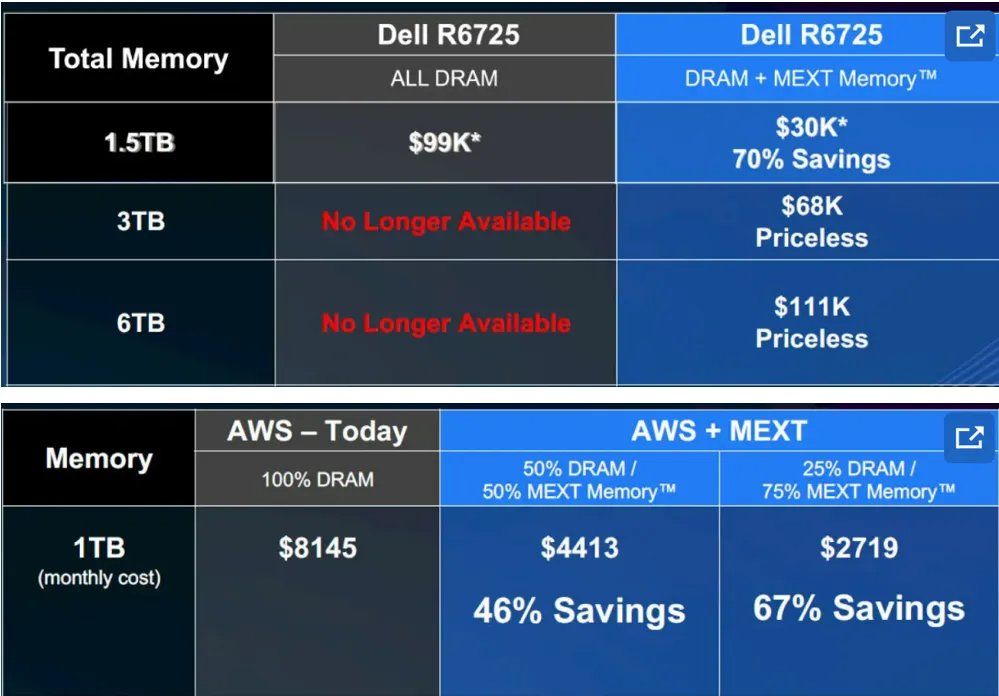
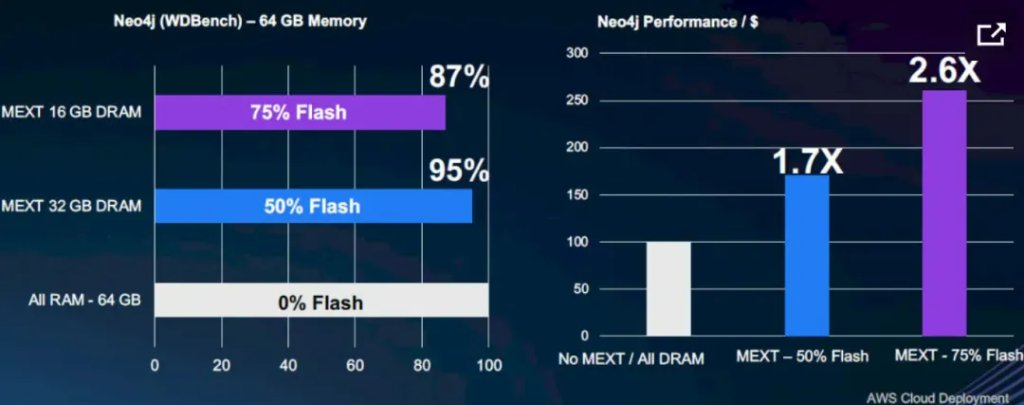
官方数据显示,该方案可将系统有效内存容量提升2至4倍,基础设施整体成本下降约50%。在Neo4j图数据库、EDA仿真、影视渲染等典型场景中,DRAM与闪存1:1配比的配置,可达到纯DRAM配置约95%的吞吐量,成本却大幅降低。
MEXT之前针对戴尔服务器以及AWS云实例进行了对比测试:
戴尔电脑/AWS配备和未配备MEXT扩展内存的对比图(图源:Nextplat)
已经在使用MEXT内存扩展时,内存和闪存比例为1:1和1:3时Neo4j图数据库的性能和性价比:
图源:Nextplat
MEXT的思路虽说不是革命性的——内存分层、把冷数据迁到更便宜的存储介质上,这些概念其实都已经存在了相当长的时间。但以往的技术没能在数据中心大规模落地,关键就在于预测算法的准确度不够。一旦预判失准,程序在需要数据时才从闪存搬回DRAM,延迟就会直接暴露,性能损失根本无法接受。
MEXT的突破在于用AI模型来干这件事。它的预测内存引擎持续分析内存访问模式,通过AI判断哪些数据页接下来最有可能被用到,然后在应用程序真正发起请求之前,就主动把数据从闪存迁回到DRAM。
对AMD而言,这笔收购补上了自身全栈能力的关键一块。在EPYC CPU、Instinct GPU与ROCm软件栈之外,MEXT带来的内存效率层,让AMD能够为客户提供从芯片到数据流调度的完整解决方案,既帮助客户降低总拥有成本、减少GPU“等数据”的闲置,也强化了自身在AI基础设施市场的竞争力。
收购消息公布当日,AMD股价盘中上涨近7%,市场用投票表达了对这一路径的认可。
当然也得说一句,MEXT的技术最终能在AMD的数据中心产品中落地到什么程度,还有待时间来检验。NAND闪存和DRAM在延迟上的物理差异是客观存在的,仅靠软件层面的AI预测能否真正弥合这道鸿沟,还需要看大规模部署后的实际表现。
Apple:端侧大模型,把模型“存进”闪存
当数据中心在为DRAM成本头疼,消费端也面临着同样的约束——手机等终端的DRAM容量极为有限,却要承载端侧大模型的推理需求。苹果给出的答案,是让大模型常驻闪存,按需加载到内存。
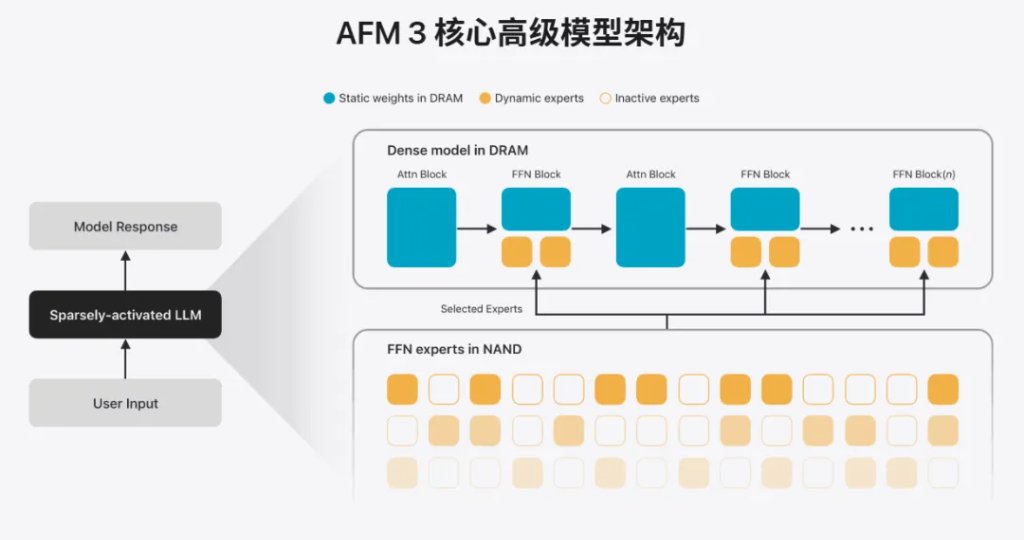
苹果最新的AFM 3 Core Advanced是一款200亿参数的端侧大模型,若按传统方式全部加载到DRAM,远超消费级设备的内存上限。苹果通过稀疏激活架构破解了这一难题:完整模型全部存放在NAND闪存中,推理时不加载全部权重,而是根据输入提示词一次性选定本次推理所需的专家模块,仅将10亿到40亿参数的工作集调入DRAM。
AFM 3 Core Advanced模型架构示意图
与传统MoE模型逐Token切换专家、导致频繁数据搬运不同,苹果采用按提示词粒度的路由机制,配合高比例常驻DRAM的共享专家,大幅减少了闪存与内存之间的交换次数,将加载延迟降到最低。再结合指令级剪枝(IFP)、Transformer层精简等优化,最终将200亿参数模型的DRAM峰值占用控制在2GB至8GB区间,进一步平衡了内存占用与计算效率,有效解决了MoE在端侧部署时DRAM占用过大的问题,使其能够在iPhone等终端设备上流畅运行,实现了“大模型小内存”的端侧推理。
这套架构并非临时攻关的产物。