Scaling law原作曝bug,万亿算力全白烧新智元
DeepMind研究员指出,OpenAI最初的Scaling Law错误引导 AI 行业长期“重参数、轻数据”,让大量模型训练不足、算力配置失衡,全球或因此浪费了数年研发时间和海量 GPU 资源。后续研究证实,模型与数据应同步放大,此前方向可能浪费了海量算力。
OpenAI误导了整个AI圈好几年!
过去五年,整个AI行业都被Scaling Law推着往前冲。
奥特曼坚信AGI的底气就来自这条曲线。
现在,有人站出来说:这条曲线,一开始就错了。
不是事后诸葛。说这话的,是当年就在OpenAI做大模型优化的研究员Diogo Almeida。
刚刚,他发出一篇博客,标题冷得发指——《Scaling Laws, Honestly》。
开头一句直接把话说死:最初那版scaling law是错的,因为存在一个bug。
传送门:https://www.completeskeptic.com/p/scaling-laws-honestly
DeepMind那位以扩散模型封神的Sander Dieleman,转头就在推特上把它顶了上去,说这是一段有意思的LLM往事:
原始scaling law因为一个bug而错了,大概率害得业界在一堆「体量过大、训练不足」的模型上,白白烧掉了海量算力。
一个bug,烧掉两年。
当bug被撕开,我们看到的,不仅是算力的黑洞,更是一条被语言本身重塑的、远比想象中更深刻的智能边界。
Scaling Law竟是LLM版「地心说」
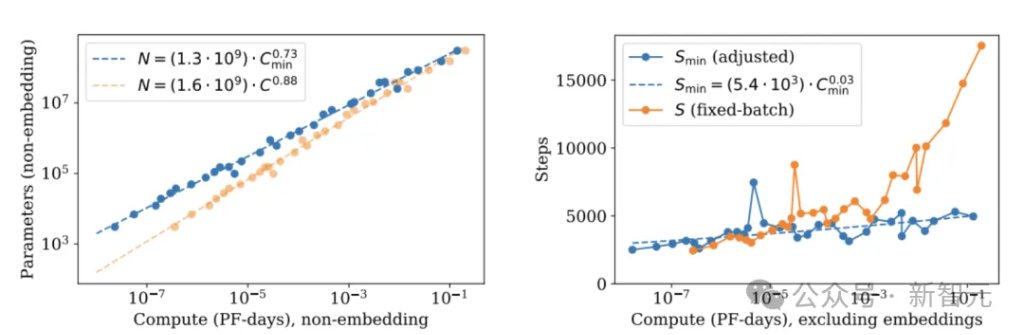
2020年,OpenAI给出结论:在固定的算力预算下,你应该优先把模型做大,而不是拿更多数据去喂它。
用公式说,最优参数量正比于算力的0.73次方——参数,是那个更该猛冲的变量。
这句话,直接定义了GPT-3那一代的长相。堆参数。往死里堆。1750亿。
它告诉全世界的开发者:别问,问就是堆参数;只要你把模型做得足够大,神迹就会发生。
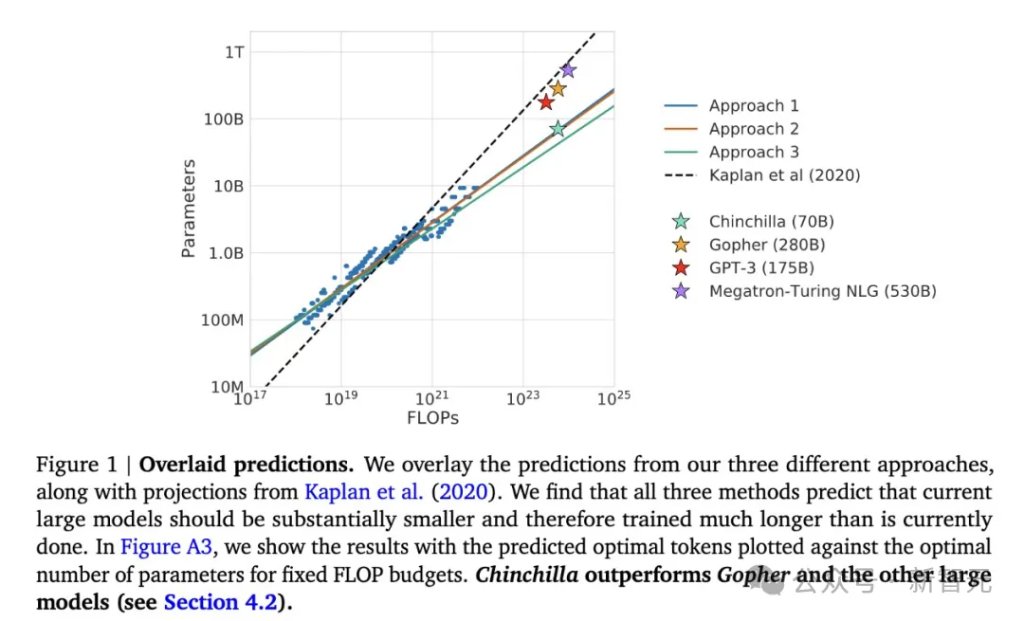
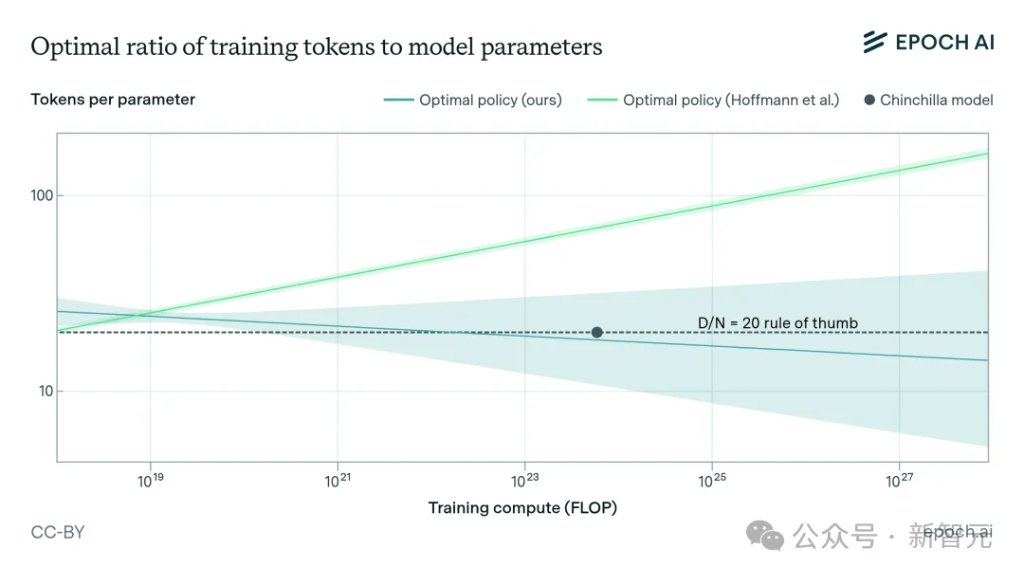
两年后,DeepMind甩出Chinchilla,把这个结论掀了个底朝天:模型和数据,应该差不多同等重要地一起放大,大约每个参数配20个token才划算。
他们训了一个700亿参数的Chinchilla,喂了1.4万亿token——体量不到GPT-3的一半,数据是它的四倍多。
结果,同样的算力预算,全面反超2800亿参数、却只喂了3000亿token的Gopher。
翻译成人话:同样一笔钱,一个把它养成了"虚胖"的壮汉,一个把它练成了精瘦的拳手。
拖更三年,北大校友翁荔深入探讨了后续研究中对两者差异的主流解释,即差异在于他们计算参数总数的方式。
而这还没完。就连「正确」的那个Chinchilla,自己也不干净。
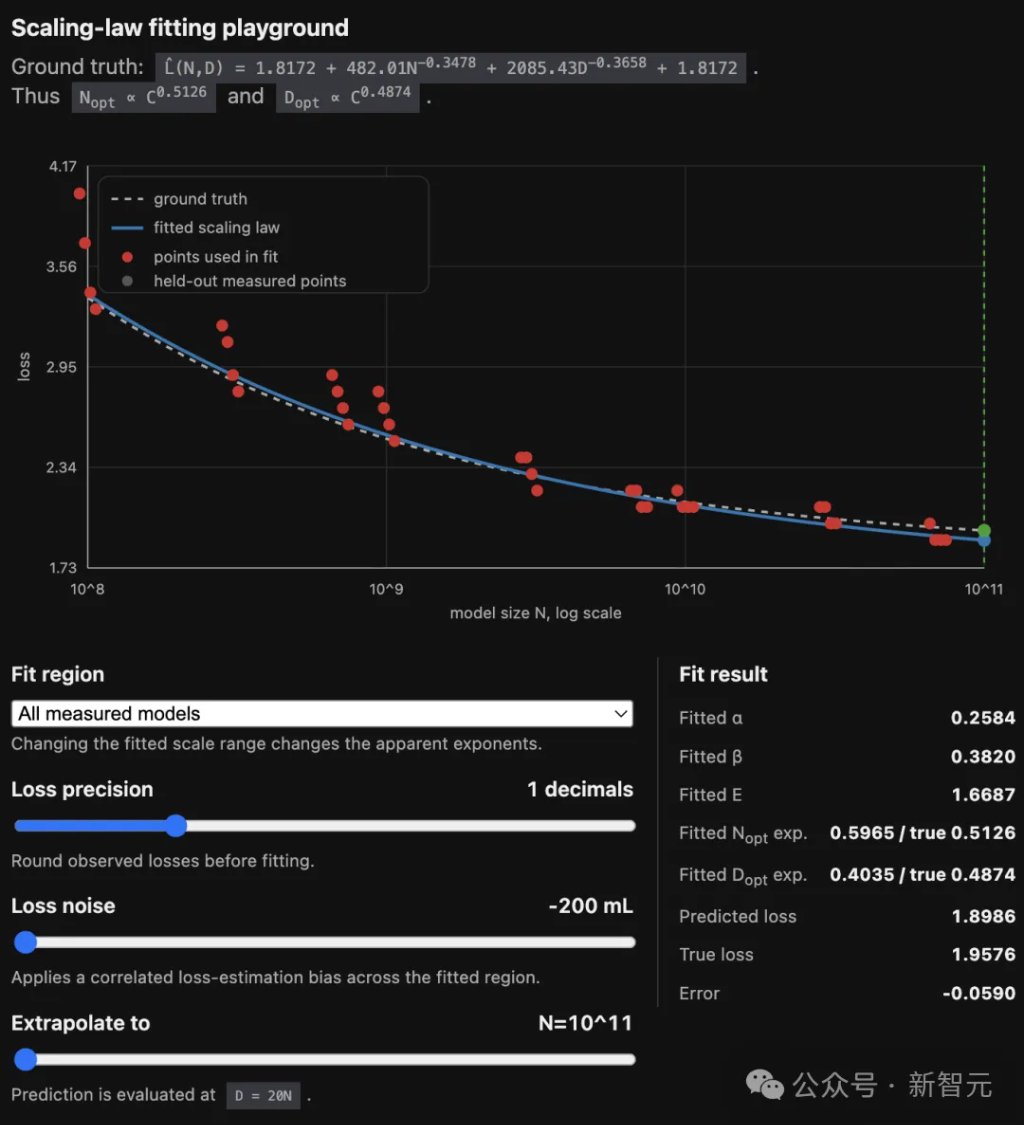
2024年,Besiroglu等人把Chinchilla原文的数据点扒出来重跑,发现它自己那套拟合里也藏着bug:
优化器里的loss尺度设得过高,把Huber损失按样本求了平均、而不是求和,导致拟合过早终止。
纠正bug的论文,自己带着另一个bug。
到这儿,那句被无数人挂在嘴边的「第一性原理」,忽然有点站不住了。
所谓Scaling Law,从来就不是牛顿三定律那种铁打的物理规律,它只是一条经验拟合出来的曲线。
当Diogo Almeida认为真相并非如此,不是方法不一样,「是最初那版scaling law本身有个bug。」
OpenAI三招骗了全球AI同行?
要制造一个让全球AI集体相信的谎言,只需要三步。
第一步:囚禁数据。
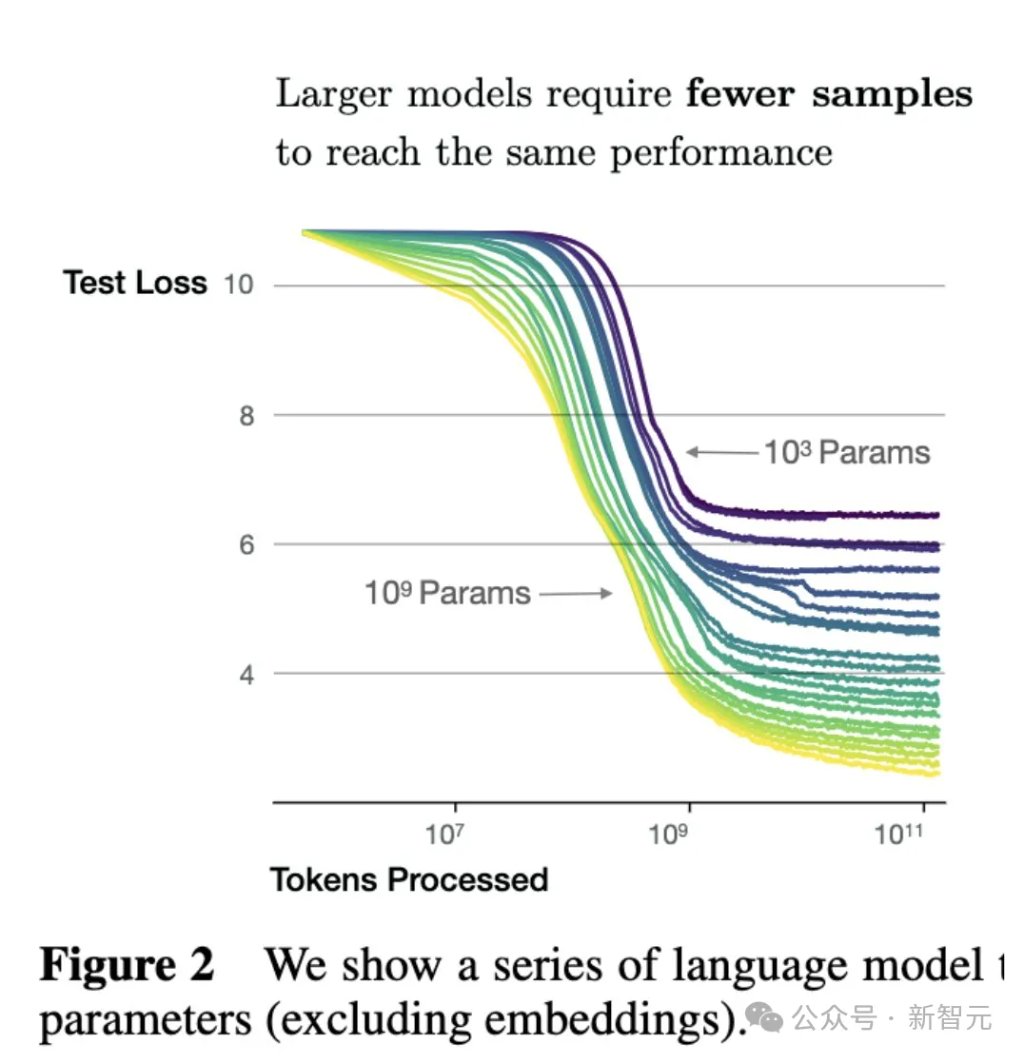
OpenAI论文给所有模型——不管它是还在学习走路的孩子(小模型),还是已经长成巨人的模型,喂了完全相同的「饭量」。大约130B tokens数据。
小模型因此被「喂饱」甚至「撑到」,而真正需要海量数据来填满其容量的大模型,却在同一token预算下严重营养不良。