把死鲑鱼放进fMRI,它的大脑还在转环球科学
2005年一个周六的清晨,克雷格·贝内特(Craig Bennett)早早地跑去当地超市,买了一条完整的北大西洋鲑鱼(Atlantic salmon,也就是我们常说的三文鱼),并用塑料膜包裹好。和店员所想的不同,贝内特并不是一位急于享受美食的老饕,而是美国达特茅斯学院(Dartmouth College)的一年级研究生。
图片来源:Unsplash
他带着包好的鲑鱼来到校内的影像中心,然后将整条鱼牢牢固定住,把它送入功能核磁共振成像(fMRI)仪器中,测试他所在研究团队新开发的整套扫描方案。为了不将宝贵的扫描时间都花在反复拍摄标准MRI体模上,他和同伴玩笑式地决定,不如扫描一些超市里能买到的最奇怪的东西,比如南瓜,比如母鸡的头,也比如一整条完整的鲑鱼。
图片来源:Unsplash
扫描生成的高分辨率图像相当漂亮。从不同方向观察,能看到清晰的鱼身截面,也能看到一片片整齐的三文鱼排。在满足过好奇心后,贝内特将这组数据保存起来,一放就是三年。
2008年,已经加入美国加利福尼亚大学圣芭芭拉分校(University of California Santa Barbara)的贝内特,在和导师乔治·沃尔福德(George Wolford)准备一场关于fMRI中多重比较问题的报告时,又重新想起了这条鱼。
很有趣的是,这次他们将死鱼数据导入分析流程后,真的发现了一些异常信号:有三个显著体素聚成一小簇,恰好出现在鲑鱼大脑中线附近。按照这套分析流程的解释,这意味着实验对象在被要求识别人类照片中的情绪时,表现出了“大脑活动”。
鱼死不能复生
fMRI监测大脑活动的原理,并非直接拍摄神经元放电,而是依赖一种叫做血氧水平依赖信号(BOLD)的间接指标。当某个脑区更活跃时,局部血流和血氧供应会发生变化,进而改变磁共振信号。
研究者会把大脑图像分成许多细小的三维单位,也就是体素,再逐一分析每个体素的信号变化是否与实验任务相关。如果某些体素的变化模式与任务时间安排相吻合,它们就可能在统计分析中被标记为“显著活动”。
因此,fMRI图像那些亮起来的斑块,并不是仪器直接看见大脑活动,而是研究者在大量体素中寻找与实验任务同步变化的信号后,经过统计处理得到的结果。
死鱼能思考吗?答案显然是否定的。它不可能复活,更不可能躺在仪器里判断照片中人物的喜怒哀乐。但影像结果却仿佛一本正经地告诉研究者,这条死透了的鲑鱼,大脑“亮”了起来。
贝内特和导师在会议上展示了死鲑鱼海报。图片来源:prefrontal.org
这简直离谱又荒诞,但这也正是贝内特和导师想要展示的关键:如果一条死鱼都能在神经影像中表现出看似有意义的活动,那么面对更复杂的人类大脑图像中那些明亮的彩色斑块,我们又该如何判断它们究竟是否是真实信号?
这条死鲑鱼最终成为说明fMRI假阳性问题的经典案例。当一幅图像包含成千上万个体素时,只要研究者在每个位置都寻找“显著”活动,总会有一些地方看起来不同寻常。而对于高精度fMRI扫描数据的解读,更需要格外谨慎。毕竟,一个不留神,连死鱼都能“复活”。
2009年,贝内特与合作者将这项研究以会议摘要的形式发表在《神经影像学》(NeuroImage)上,至今仍被广泛引用。后来,他们还因“证明通过使用复杂仪器和简单统计方法,可以在任何地方看到有意义的脑活动——即便是在一条死鲑鱼身上”,获得了2012年搞笑诺贝尔奖。
尽管不算正经,但搞笑诺奖的的宗旨其实是奖励那些“让人捧腹大笑,同时也引人深思”的研究。而这条死鲑鱼带来的思考,正指向现代科学中一个重要的问题:多重比较问题。
看得多会更准确吗?
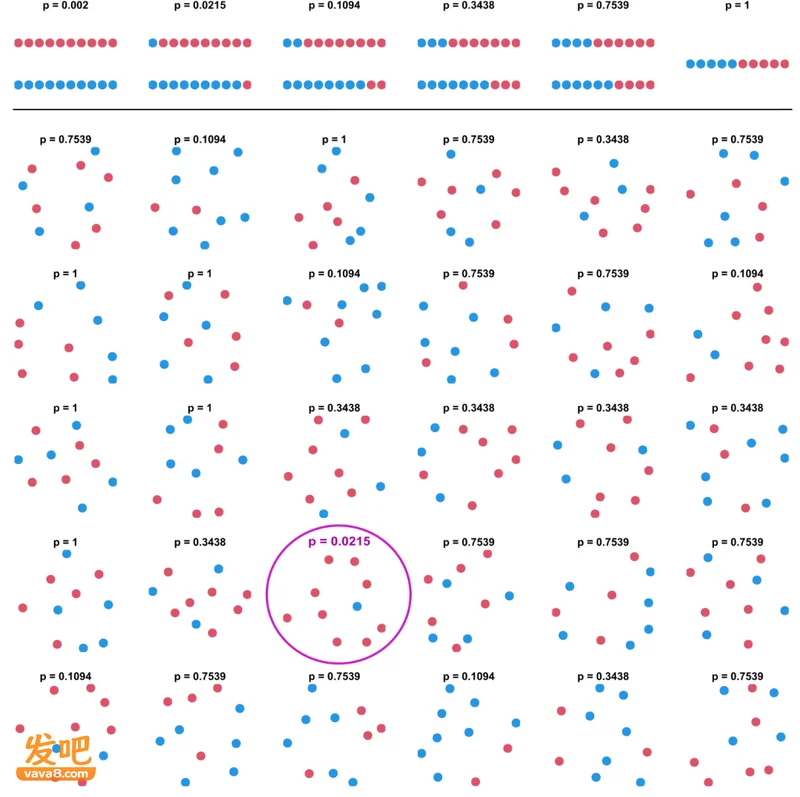
在fMRI中,一次看似简单的脑成像分析,背后其实包含了成千上万次统计比较,这也是多重比较问题的来源。它对应了一个非常朴素的风险:看得越多,越容易把偶然当成新发现。
这似乎有些反直觉。毕竟,从现代科学的发展来看,样本越大、仪器越精密、图像越漂亮,结果应该越可靠才对。但问题在于,数据越多,发现真实信号的机会确实越多,但与此同时,噪声伪装成信号的机会也越来越多。
不放想象一下,你正在观察一张巨大的照片,试图在其中寻找异常的斑点。如果你快速扫过整幅画,可能不会发现什么异常。但如果你观察得足够细、足够久,总会有一些地方显得不太寻常。统计检验也是如此。在单次检验中,随机噪声偶然越过显著性门槛的概率可能并不高。但如果同样的检验被重复成千上万次,误报就会迅速累积。死鲑鱼脑中的那几个活跃体素,正是随机噪声在大量比较中制造出来的幻象。
多重检验导致p值偏小。图片来源:By GrandEscogriffe - Own work, CC BY-SA 4.0
当然,多重比较问题并不仅仅出现在神经影像学中。在基因组学中,研究者需要同时检验几万个基因或遗传位点与某种疾病是否相关,而其中一小部分所谓“显著”基因,也可能只是偶然浮现。在药物试验中,如果一项研究需要同时观察几十种症状、多个剂量和不同人群亚组,研究者也可能找到某个看似有效的结果。而在心理学和社会科学中,当一份研究同时调查分析大量人格维度、行为指标和人口学等变量,变量之间偶然相关的概率也会迅速增加。
甚至在更大尺度的数据科学中,也同样如此。天文学家在海量巡天数据中寻找罕见天体或异常信号,粒子物理学家在无数碰撞事件中寻找新粒子的迹象,人工智能研究者也会在大量数据集、上百个任务乃至众多指标上评测模型表现。事实上,只要比较得足够多,噪声总有机会伪装成突破。特别是当研究者有意无意地挑选其中漂亮的结果时,显著性很容易被人为放大。
而所谓多重比较校正,就是在发现这些“漂亮结果”后,进一步追问:考虑到我们已经检查了如此多位置、变量或关系后,这个发现是否依然足够罕见?它是否真的超出了随机噪声可能造成的范围?如果没有这一步校正,研究者就很容易把偶然出现的异常结果,当成真实的科学发现。
科学如何自我约束
为了应对这种风险,不同领域都发展出了自己的“防误报”办法。神经影像学要校正成千上万个体素,避免把噪声看成大脑活动;而基因组学面对的是数百万个位点,因此选择设置更严格的显著性门槛;粒子物理学则采用更严苛的标准,尽量排除随机涨落的可能。
不过,假阳性并不只来自数据本身,也来自人类如何处理数据。精密仪器当然不会主动说谎,但复杂流程会给人类留下太多“无意中挑选真相”的空间。同一批数据,可以有许多看似合理的处理方式:排除哪些样本,采用哪种预处理流程,比较哪些变量,选择什么理论模型,等等。每一个选择单独看都未必有问题,但如果研究者在看过结果后不断调整这些选择,直到找到漂亮的结论,偶然就很容易被包装成新发现。
这也是为什么现代科学不能只依赖更精密的仪器,还需要更严格的自我约束。多重比较校正是一道防线,预注册和注册报告也是一道防线。前者要求研究者在统计这一步上考虑自己究竟找了多少次,后者则要求研究者在看到结果前先说清楚,自己检验的目标,以及计划如何分析。除此之外,开放数据和代码、独立重复、盲分析、外部验证集,也都是一道道保险,尽量减少研究者在海量数据中无意挑选“新发现”的机会。
回到那条死鲑鱼,它当然没有复活,也没有在仪器里识别人类情绪。但那几个虚假的活跃体素,却照亮了现代科学中的一个关键问题:当我们面对越来越复杂的数据和越来越精美的图像时,最需要警惕的往往不是看不见信号,而是太容易看见那些像信号的噪声。毕竟,科学的可信之处,并不来自它永远不会出错,而源于它不断开发新的方法,来识别自己可能在哪里出错。