Karpathy刚进Anthropic,转头又投了它新智元
AI大神Karpathy重注!一家叫Engram公司出山,13个人团队,要让AI永久记住你。
13人公司,成立8个月,估值干到了6亿美金!
就在今天,一家名为Engram的AI初创公司结束隐身、正式亮相,一口气拿下了9800万美元融资。
这13个人,到底在做一件什么样的事,值这么多钱?
答案只有两个字:记忆!
最关键的是,仅用1%-10%的Token,Engram便能让大模型做到过目不忘。
而且,每一次对话,它都能实现不断自我改进。
投资人Karpathy第一时间送上了祝贺。
成立8个月,要让AI「永不失忆」
Engram这个词,本身就来自神经科学,指的是记忆在大脑中留下的「痕迹」。
一家做AI记忆的公司,名字就叫「记忆痕迹」,野心写在脸上。
团队将致力于解决的核心痛点,生动地概括为——「天才陌生人」(genius stranger)。
今天的AI,智商爆表,记性却烂得吓人。
它能处理海量信息、攻克复杂难题,但在面对具体业务时,认知水平甚至不如一名刚入职的实习生。
于是,荒谬的一幕反复上演:它不得不一遍遍重读相同的文档,一次次重新学习业务背景;
每面对一个新问题,都要把整个组织的知识库从头到尾「重新发现」一遍。
这不光蠢,还烧钱。随着上下文越来越大,模型越贵、越容易犯迷糊。
不卷大模型,专卷「记忆」
Engram的打法,跟其他实验室完全不在一个维度。
它的思路是,从一个强大的预训练模型起步,把训练算力死死砸在「上下文」上。
听起来很美,技术上凭什么落地?
答案就藏在CTO Sabri Eyuboglu 手里的王牌——Cartridges技术里。
这是近两年「把一大堆文档压成可复用记忆」的代表性方法之一,由斯坦福团队打造,背后的导师正是机器学习大牛、Engram联合创始人Chris Ré。
再来看一组具体的数字,就可以理解背后真相了——
当AI阅读一份7万字、约400KB的法律合同时,它在内部生成的记忆体积,会瞬间暴涨到100GB以上。
足足比原始文件大了25万倍,这正是AI变得又慢又贵的罪魁祸首。
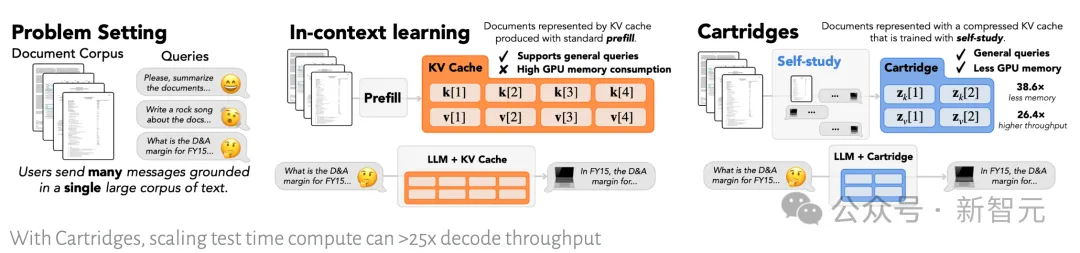
Cartridges的思路,堪称暴力美学——
与其每次临时把整篇文档塞进上下文窗口,不如提前花一大笔算力,离线把它「学」成一个小小的记忆模块。
团队管这个过程叫「self-study」:让模型先围绕语料自己生成大量合成对话,再把这些「学习痕迹」蒸馏进一个紧凑的缓存里。
最终,内存占用降到原来的约1/40,解码吞吐量飙升25倍以上。
更妙的是Engram的架构哲学:它把模型的「推理层」和「记忆层」彻底拆开。
推理负责思考,记忆负责「认得你」。
这样一来,AI就能在几秒到几小时内,实时吸收个人偏好、对话历史和新到的数据,而不用从头重训一遍。
一支「全明星」团队
Engram这支队,来头一个比一个大。
去年10月,Engram孵化于斯坦福AI实验室,CEO是以色列研究者Dan Biderman。
他曾获得了哥伦比亚大学计算神经科学博士学位,后来进了Stanford AI实验室做博士后。
更有意思的,是Biderman痴迷「记忆」的起点。