国产视频模型干翻Gemini新智元
京东开源JoyAI-VL-Interaction,把视频AI从「你问我答」的轮次对话,推进到「持续在场、主动开口、按时机说话」的流式交互新范式。
世界杯决赛最后一秒,球进了。
你身边那个号称能「看懂视频」的AI,还在安静地等你开口问一句「刚才发生了什么?」。
这就是今天几乎所有视频AI的样子——不管包装得多酷炫,骨子里都是同一个逻辑:你问,它答。
可真实世界里最需要AI出声的那些瞬间,从来不会等人提问——解说员不会等导播发话才开口喊「Goal」。
这些场景要的不是「问答」,而是一双全程在线、自己拿主意什么时候该说话的眼睛。
现在,京东把这双「眼睛」开源了,它叫JoyAI-VL-Interaction。
JoyAI-VL-Interaction的重点不只是「看懂视频」,更是要让模型在连续的视频流里自己决定——何时回应、何时沉默、何时把复杂任务甩给后台。
一句话:它学会了什么时候该闭嘴,更学会了什么时候必须开口。
这套系统刚开源就拿到了生态层面的背书——JoyAI-VL-Interaction 获得了 vLLM-Omni 的 day-0 支持,已原生合入 vLLM-Omni 主线。
开发者可以在 vLLM-Omni 上一键拉起服务体验,也可以直接从京东的仓库一键启动。
代码:https://github.com/jd-opensource/JoyAI-VL-Interaction
模型:https://huggingface.co/jdopensource/JoyAI-VL-Interaction-Preview
数据集:https://huggingface.co/datasets/jdopensource/JoyAI-VL-Interaction
技术报告:https://huggingface.co/papers/2606.14777
主动、实时、还会「甩锅」
JoyAI-VL-Interaction拥有三项核心能力。
第一是自主交互(Proactive Interaction)。
这是整个模型最颠覆直觉的地方——它不等你开口,自己判断这一刻值不值得说话。
看护场景里,老人正常活动它一声不吭,一旦察觉异常立刻预警,而不是每隔十秒问你「需要帮忙吗?」。
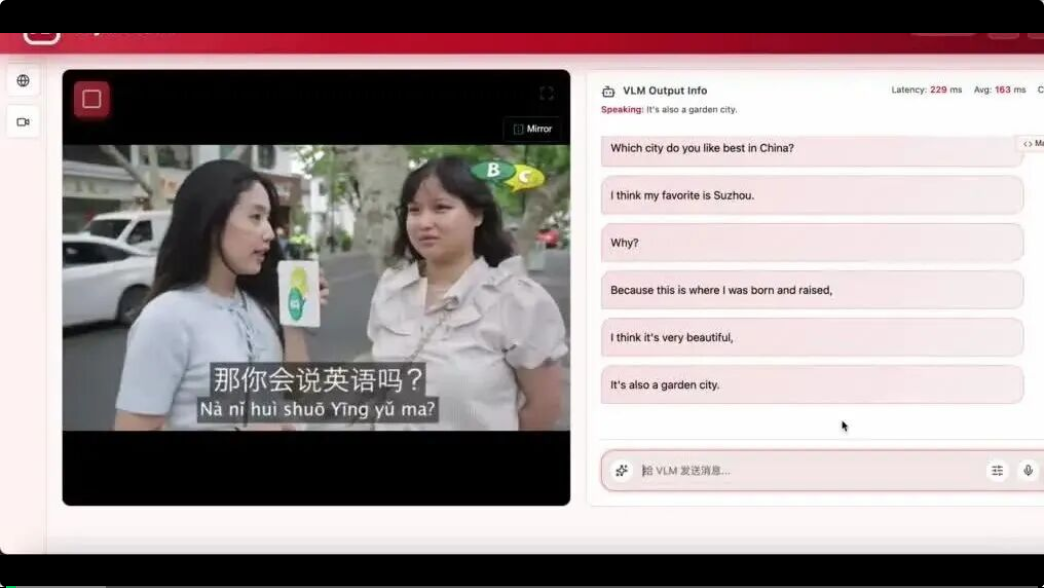
实时翻译场景更直观:你跟它说「把电影字幕翻译成中文」,它不会翻一句停下来等你发下一条指令,而是自己盯着画面,每出一行新字幕就主动翻译。
比如,JoyAI-VL-Interaction在街头采访视频上逐句翻译字幕,全程不落一句。
第二是实时响应(Real-time Response)。
能力有了,速度跟不上也白搭。
JoyAI-VL-Interaction靠三个关键设计把延迟压到了亚秒级:
一是JoyAI-VL-Interaction推理系统是vllm原生适配的,确保有较高的KV Cache复用率,获得了 vLLM-Omni 的 day-0 原生支持。
二是AdaCodec——它不给每一帧都花完整的ViT token,而是只在画面真正发生变化的「关键帧」上花全量token(约256个),中间的「可预测帧」只用大约16个轻量P-token就搞定。
这样一来,即使持续看几个小时的视频,token预算也只和画面变化量成正比,而不是随帧数线性爆炸。
三是长程记忆的分层缓存:短期记忆保留最近的原始视觉token,中期记忆存文本摘要,长期记忆做进一步压缩。
这三层加起来能覆盖大约12小时的上下文,而且压缩过程是异步运行的,完全不堵实时推理。
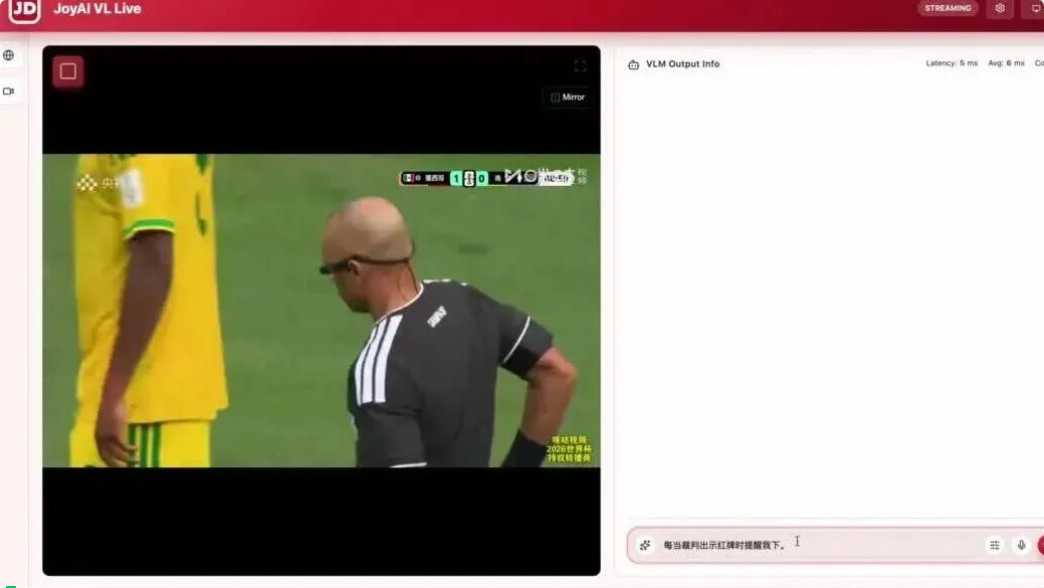
2026 世界杯墨西哥对南非的直播流里,用户只丢了一句「裁判出示红牌时提醒我」,JoyAI-VL-Interaction 就自己盯着画面,红牌亮出的一瞬间同步喊出「裁判出示红牌」——平均延迟 94 毫秒,比现场观众的反应还快。
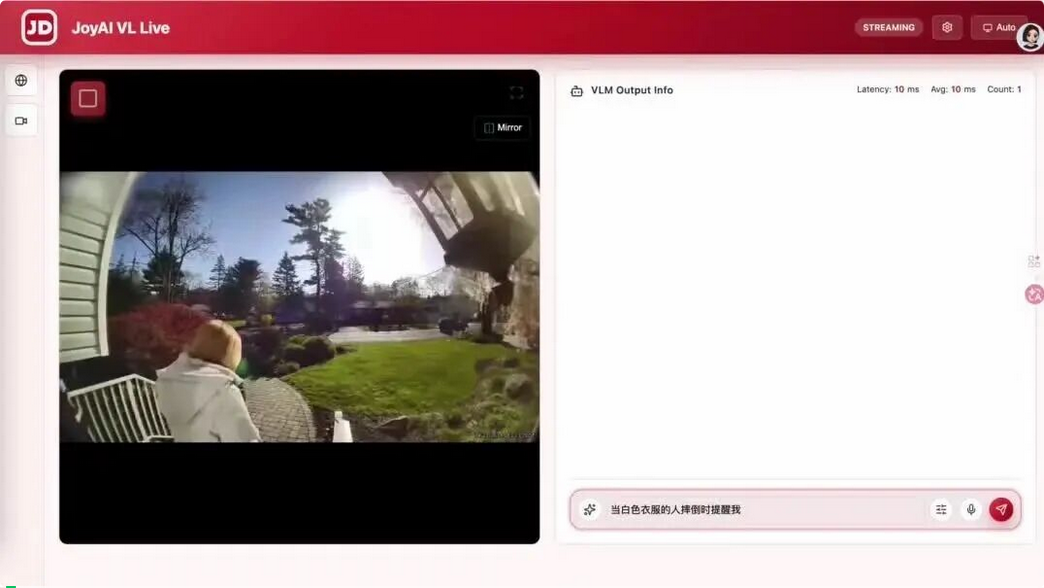
有人摔倒时,也能够及时提醒。而不是事后总结。
第三是任务委派(Delegation)。
这招最像人。
碰上超出实时推理能力的难题——比如你对着一道数学证明题说「帮我推导一下」,或者看着手机界面说「用HTML把这个APP页面复刻出来」——它不会硬答一通然后翻车。
JoyAI-VL-Interaction能主动把活儿甩给后台的大模型或Agent,自己继续盯着画面、陪着你,等后台结果回来再自然接回对话。
比如,它可以一边把「复刻手机界面」的任务交给后台,一边继续和用户聊天、回答其他问题,后台返回HTML代码后无缝衔接,全程不断线。
你这边还在跟它你问我答,后台已经默默把证明微分中值定理这种硬骨头啃完了。
而且这个「后台」是可替换的:JoyAI-VL-Interaction已经做好了到Claude Code、OpenClaw、Hermes Agent等各种Agent的桥接,任何API、模型都能接进来当「后台大脑」。
前台实时陪伴,后台默默干活——它不再只是个视频问答助手,更像一套「边看边说+后台执行」的协作系统。
这就像是在物理世界和数字世界之间自由穿梭。
听着有点玄,但拆开看就是:前台模型盯着摄像头里的真实世界(物理世界),后台Agent去完成搜索、写代码、下单之类的数字世界任务。
看到了,判断了,还能动手干活——一个8B的小模型,居然跑出了Agent的味道。
从「一问一答」到「边看边说」
能力清单看着热闹,可它到底比Gemini强在哪?得先看清老办法卡在哪。
今天的视频通话AI看着像实时交互,扒开看还是轮次对话:你抛一个问题,它回答,然后等你下一句。
本质和文字聊天没区别,只是把输入换成了画面。
豆包的视频通话还更主动一点,靠的是外部轮询触发器定时「打一枪」才看画面。Gemini的视频通话更直接,连这一枪都省了——你不问,它连一帧都不给你看。
同样是世界杯这个例子,不论是豆包还是Gemini都没能实时做出反应。
JoyAI-VL-Interaction改写的正是这套逻辑:从「轮次对话」走向「流式交互」。