GPT-5.5-Cyber出世,Codex被扒史诗级bug新智元
今天,OpenAI祭出满血GPT-5.5-Cyber,要给全世界的开源代码修漏洞。结果话音刚落,Codex被扒出史诗级bug:一年狂写640TB,能把SSD直接写废。
刚刚,OpenAI重磅发布「满血版」GPT-5.5-Cyber!
这是迄今为止,最强大的网络安全模型,专为经授权的高级防御任务量身定制。
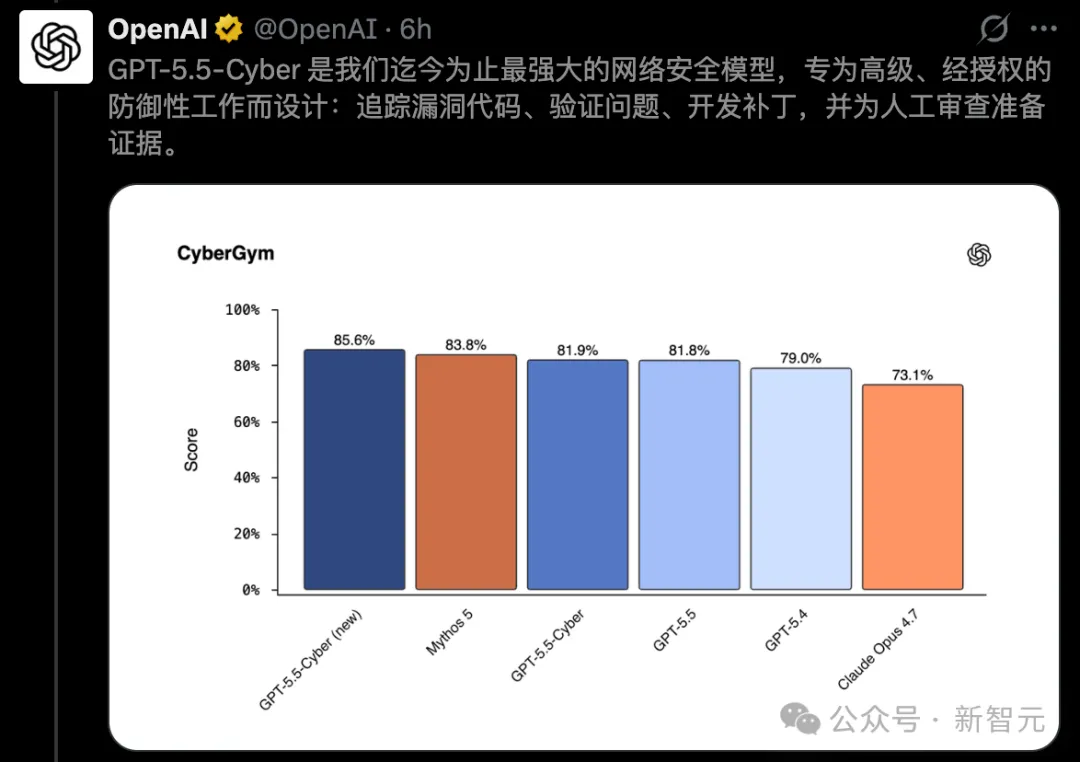
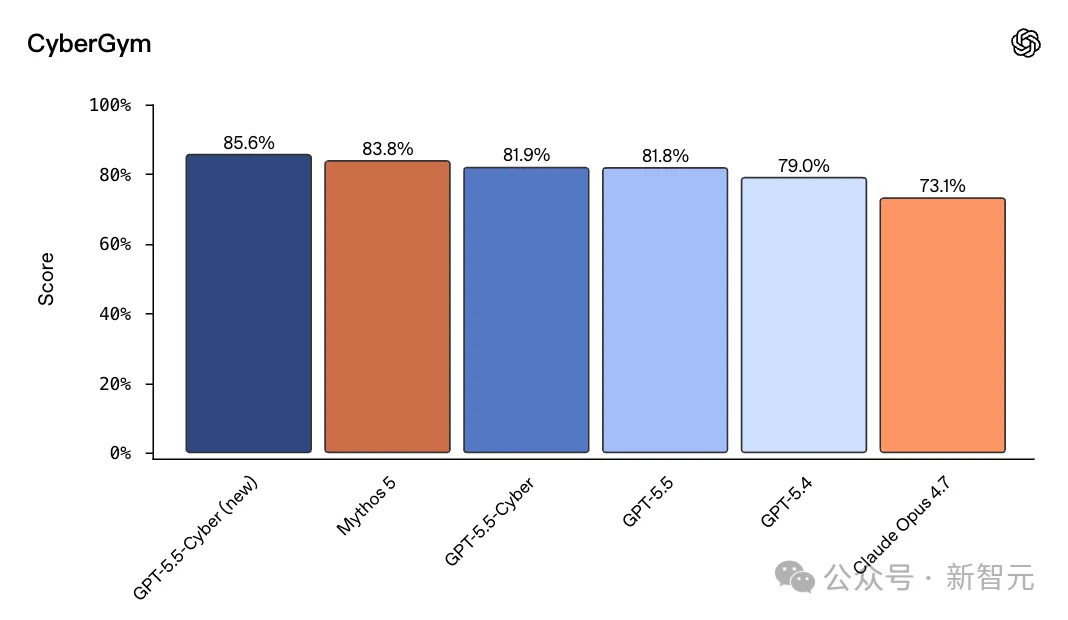
在权威CyberGym基准测试中,它一举拿下85.6%高分,强势击败Mythos 5。
其核心能力涵盖:踪漏洞代码、验证安全隐患、生成补丁,并为人工审查提供证据。
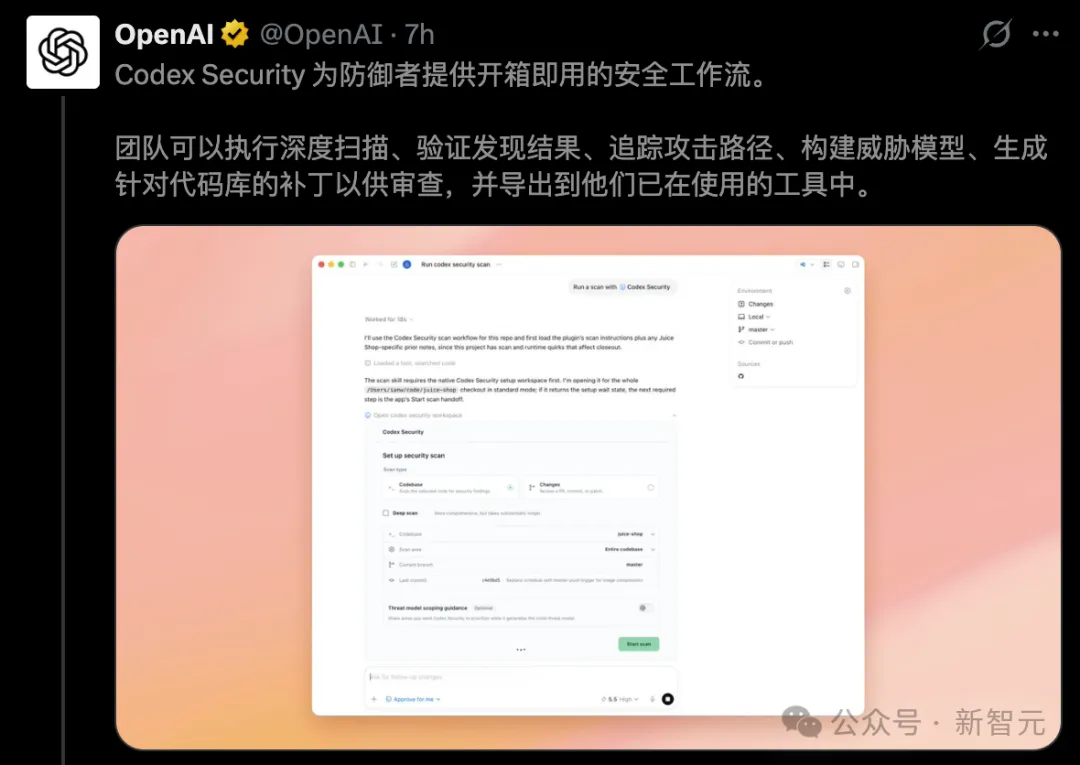
同在今天,Codex Security插件同步首发——
不仅能修复现有系统中的漏洞,还能自动防止新漏洞进入生产环境。
谁曾想,几乎同一时间,Codex竟被曝出了「史诗级」漏洞。
不少开发者反馈,Codex 在执行流式任务和长时间运行时,会以极高的频率向本地SQLite日志疯狂写入数据。
一年预估写入640TB,这足以在一年内写废一块消费级SSD。
OpenAI一边抛出「修补地球」的安全神话,另一边就爆出「烧穿硬盘」的致命 Bug。
现实版的冰与火之歌,同框上演了!
「满血」GPT-5.5-Cyber登场
强压Mythos 5
不得不说,OpenAI这次是真的下了血本。
它一口气甩出了网安计划Daybreak(破晓)的三大核心战略,核心叙事只有一句话——
AI已经改变了网络安全的「物理定律」。
这次发布的核心,是GPT-5.5-Cyber的完整版。
这是OpenAI迄今最强的「网络安全专用模型」,专门给「经过验证的防御者」准备的最强网安工具。
在CyberGym基准上,它拿到了85.6%,单模型最高分。
作为对比,普通版GPT-5.5是81.8%,而Claude Opus 4.7,停在了73.1%。
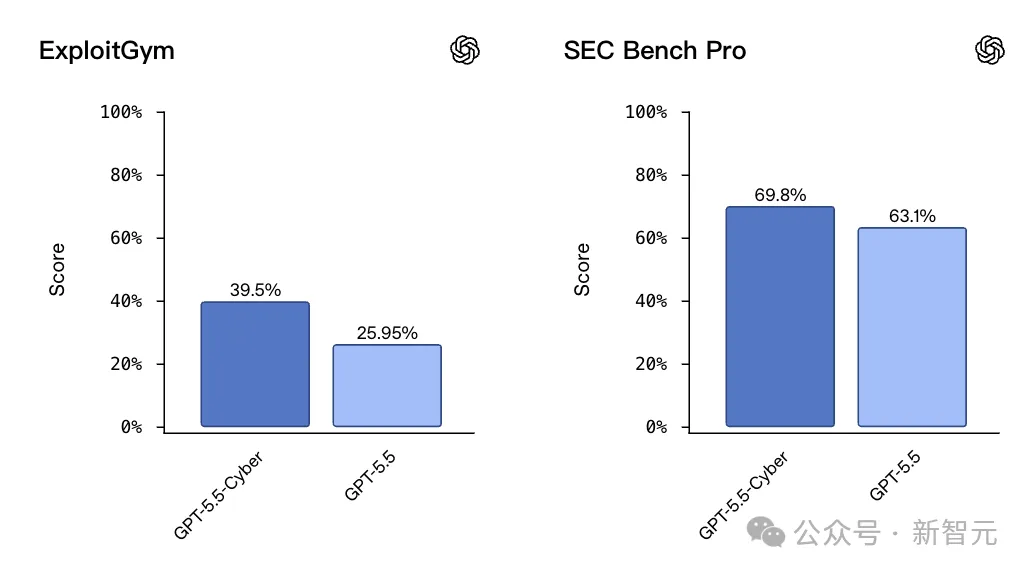
在考核「能不能把漏洞变成真实攻击代码」的ExploitGym上,Cyber版39.5% VS 普通版25.95%;
在考核长链条漏洞挖掘的SEC-bench Pro上,Cyber版69.8% VS 普通版63.1%。
三个基准,满血Cyber版,全面碾压GPT-5.5。
Codex塞进「AI安全工程师」
亮出「破晓」之刃
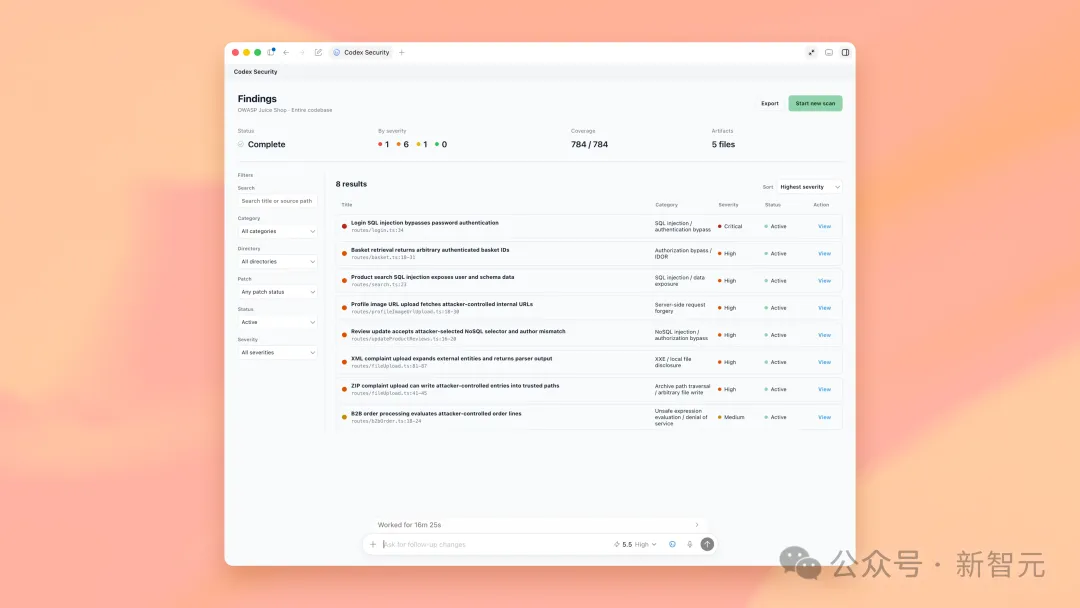
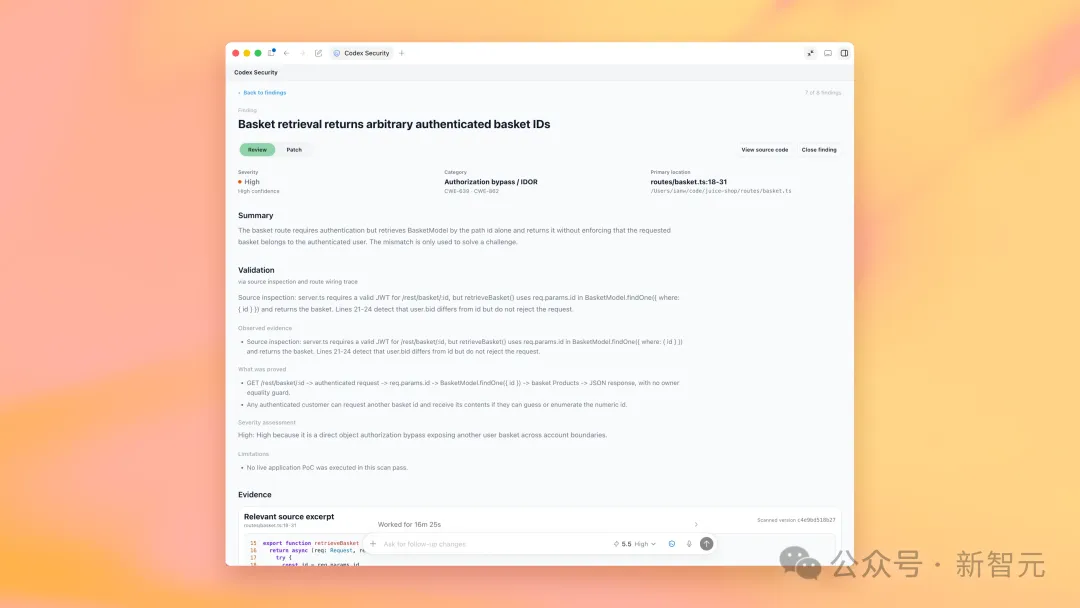
如果说GPT-5.5-Cyber是矛,那Codex Security就是那把递到每个开发者手边的盾。
OpenAI更新了Codex Security插件,把它直接焊进了Codex的工作流里——
开箱即用的漏洞扫描、威胁建模、攻击路径追踪、补丁自动生成,一条龙。