何恺明组新作:258M参数就够了量子位
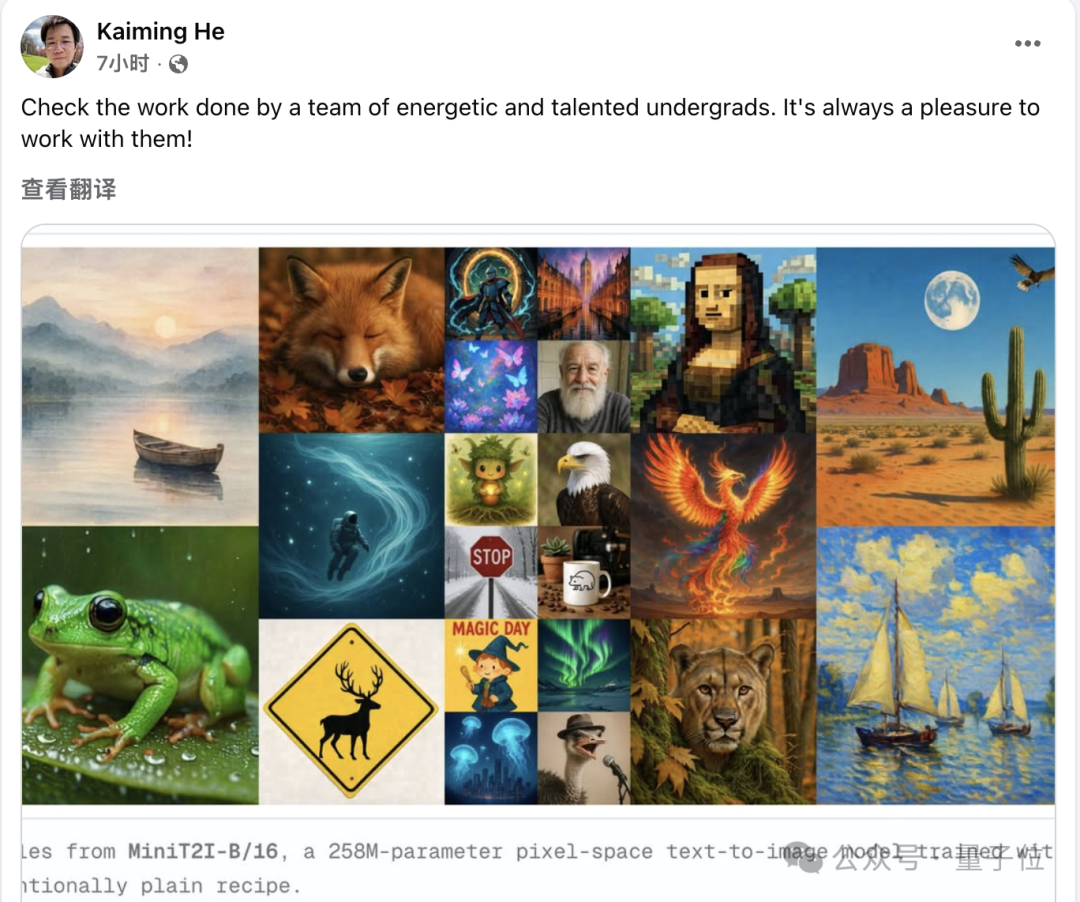
全员本科生!
刚刚,何恺明携本科生 “军团” 又放出一篇新论文。继去年探索直接从像素预测图像的 JiT 架构后,团队这次又把这套 “删繁就简” 的思路扩展到了文生图领域,推出全新工作:MiniT2I。
在今天动辄数十亿参数、海量图文数据训练文生图模型的背景下,MiniT2I 选择了另一条路。它基于全新的 MM-JiT 架构,直接在像素空间进行扩散生成,同时尽可能压缩模型复杂度和训练成本,最终,仅用 258M 参数,就实现了不错的文生图效果,更关键的是,整个训练成本只相当于一次标准 ImageNet 实验。
这是怎么做到的?
从 JiT 到 MM-JiT
整体看来,MM-JiT 是恺明组之前论文「Back to Basics」在 T2I(文本生成图像)方向上的延伸。
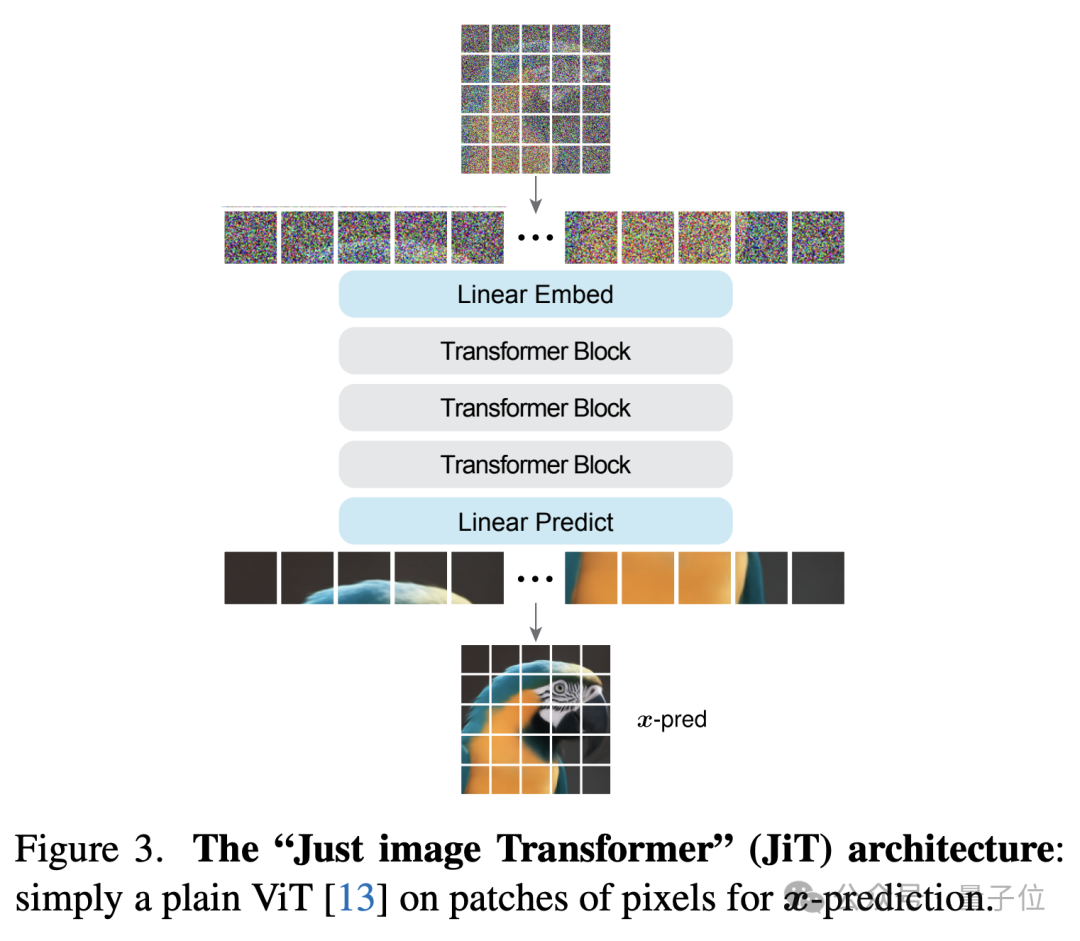
Back to Basics 中,恺明和他的博后黎天鸿提出了 JiT 架构,Just image Transformers。JiT 的核心主张是:抛开 VAE 编解码器,直接在像素空间预测干净图像(x-prediction),而不是像传统扩散模型那样预测噪声。这样做的好处是,整个生成流程更加直接,符合流形假设以及 “从像素出发” 的第一性原理。
不过,当时的 JiT 主要针对类别条件生成(class-conditional generation),任务范围相对有限,模型只能根据 ImageNet 的类别标签生成对应图像。然而,真实的图像生成任务往往不限于 ImageNet 的 1000 个固定类别,而是需要理解并遵循开放的文本 Prompt。
问题也随之而来,一旦从类别生成扩展到文生图,训练成本往往会迅速攀升。无论是 SD3、FLUX.1-dev 还是 DALL・E 3,背后都依赖多阶段训练流程、庞大的文本编码器以及海量数据资源。对于大多数学术团队而言,从零开始训练一个完整的文生图模型,几乎是一项难以承担的工程,于是,MiniT2I 应运而生。
它试图回答一个更现实的问题:如果只用接近 ImageNet 训练规模的计算资源,能不能也做出效果不错的文生图模型?答案是,可以。
研究发现,当文本首先被预训练语言模型编码为语义表示后,对于生成模型而言,文本条件本质上只是另一种形式的上下文条件。换句话说,文生图或许并没有想象中那么特殊,在模型架构、训练计算量,甚至所需数据规模上,它与类别条件生成的差距远没有业界普遍认为的那么大。
如果这个判断成立,那么一个很自然的问题就出现了:既然类别条件生成已经能用 JiT 这样的极简架构完成,那么文生图任务里那些复杂的模块,究竟哪些是真正必要的?MM-JiT 给出的答案是:把它们一个个删掉,再看模型还能不能工作。
MM-JiT:删繁就简
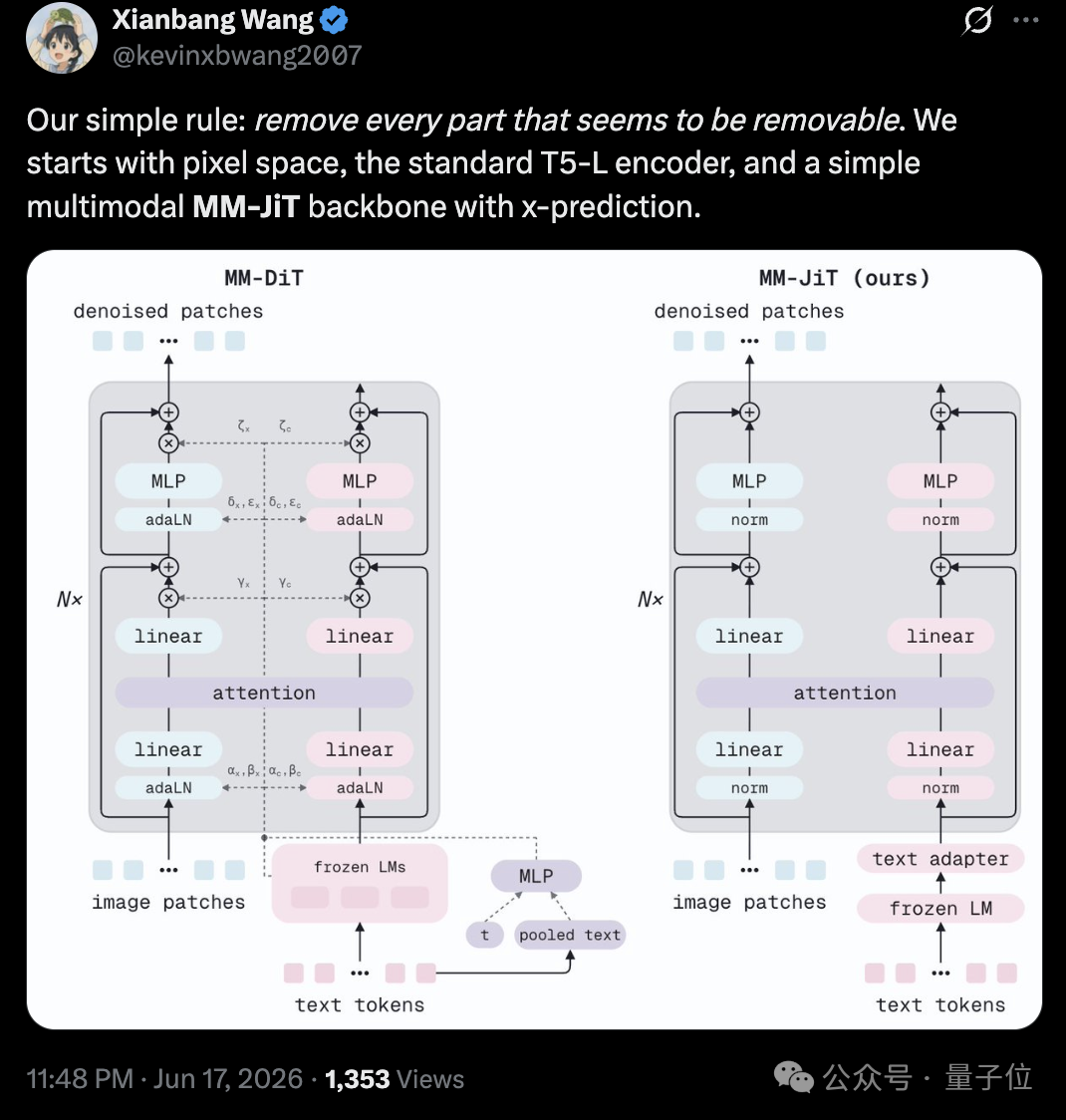
对于上面这个问题,MiniT2I 项目负责人王衔邦在 X 上的总结非常精炼:我们的原则很简单,能去掉的全去掉。起点是像素空间、标准的 T5-Large 编码器,以及一个采用 x-prediction 的简洁多模态骨干 MM-JiT。
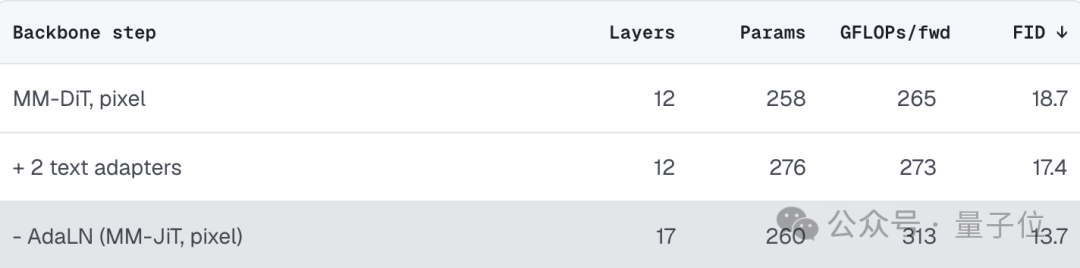
这套思路的第一刀,砍向了 VAE。众所周知,当前主流文生图模型大多采用潜在扩散(Latent Diffusion)路线:先通过 VAE 把图像压缩到低维潜空间,再在潜空间里完成扩散生成,最后解码回像素。这样做的好处是显著降低计算量,但代价也很明显,VAE 会带来重建误差和伪影,同时还额外增加了一套编解码器的训练流程。
针对这一问题,在前作 JiT 中,团队已经证明,至少在 ImageNet 任务上,直接在像素空间建模并不存在所谓的 “不可逾越瓶颈”。那么在文生图任务里,VAE 是否真的不可替代?团队决定直接把它删掉试试。
MiniT2I 将扩散过程重新搬回像素空间,希望验证一个看似反常识的判断:直接在像素空间扩散,不仅完全可行,而且未必比潜空间路线更贵。
实验表明,传统潜空间模型单次前向传播需要 1379 GFLOPs,而彻底摆脱 VAE 之后,MiniT2I 的计算开销仅为 265 GFLOPs,直接降低了约 80%。