LeCun开炮:一个4岁孩子早就证明了The AI Frontier
图灵奖得主 LeCun 开炮:大模型走不到 AGI,
一个 4 岁孩子早就证明了
刚带着 10 亿美元离开 Meta 创业的他,为什么说“机器学习很烂”、“别再搞视频生成”?
一个 4 岁孩子看过的数据,约等于人类 40 万年的全部文字
“在座有不少做机器学习的人吧?我有个坏消息要告诉你们——机器学习,很烂。”
—— Yann LeCun|图灵奖得主、AMI Labs 创始人、前 Meta 首席 AI 科学家
一个刚刚带着 10 亿美元离开 Meta、自立门户的图灵奖得主,站上讲台,开口第一句话不是“感谢邀请”,而是当着一屋子同行的面说:你们干的这行,很烂。
这就是 Yann LeCun。在硅谷一窝蜂喊着“大模型再 scale 几轮就到 AGI”的时候,他偏偏唱反调:靠把大模型做大,永远到不了人类那种智能。而他用来“证明”这一点的,不是什么复杂的数学,而是一个 4 岁的小孩。
这篇文章,我们就把 LeCun 这场关于“世界模型”的演讲,从头到尾给你讲明白:他为什么看不上大模型,他押注的下一代 AI 长什么样,以及——这事跟正在看文章的你,到底有没有关系。
智能不是“你知道多少”,而是“当你不知道时,你会怎么做”。
一|“机器学习很烂”:一句开场暴论背后的尴尬
LeCun 的逻辑很简单:把机器的学习能力,和人、和动物比一比,差距大得离谱。人和动物能用极少的样本、极快地学会新任务,而且天生带着“物理常识”——很多事情我们从没见过,第一次也能凑合做对(zero-shot)。机器呢?我们手里那些“强大”的 AI,其实根本搞不定真实世界里那种连续、高维、嘈杂的数据。
这里他点了一个经典悖论——莫拉维克悖论(Moravec's Paradox):那些对人类来说“难”的事,比如下棋、求积分、证明数学定理,计算机做起来反而轻松;而那些人类觉得“简单”到不值一提的事,对计算机却难如登天。
最扎心的例子,就是开车。
一个少年练几十小时就能上路,自驾系统喂了数百万小时数据还是 L2/L3
任何一个十六七岁的少年,练个 20 来个小时就能把车开得有模有样,遇到没见过的路况也能临场应付。可自动驾驶公司手里攥着数百万小时的训练数据,砸了那么多钱,到现在也没能靠“模仿人类”把车开到同等可靠的程度。否则我们早就有 L5 全自动驾驶了——可现实是,量产车顶多 L2、L3,所谓 Robotaxi 还得靠一堆昂贵的传感器硬撑。
那人和动物,到底是怎么学会这一切的?LeCun 的答案是:靠观察。一个两个月大的婴儿还没法移动物体,却已经能从被抱着移动、视角不断变化中,悟出一件大事——这个世界是三维的。再往后,物体恒存、稳定性、刚性这些概念很快就有了;而像重力、惯性这类“直觉物理”,则要到 9 个月左右才长出来。
你把一个八九个月大的孩子放进餐椅,给他一堆玩具,他多半会一件件地往地上扔,然后目不转睛地看结果——这其实就是在做实验,验证“重力对所有东西都管用”。心理学家测一个婴儿有没有学会某个概念,靠的就是“违反预期”:给六个月的孩子看一辆小车被推下平台却悬空不掉,他毫无反应;给十个月的孩子看同样的画面,他会瞪大眼睛——因为这违背了他刚学会的常识。
🌟AGI 这个词,本身就是无稽之谈。人类的智能其实是“专用”的——它的特征不是“什么都会”,而是“能极快地学会任何新东西”。智能不是知识的堆积,而是适应力。
二|40 万年 vs 4 年:算给“大模型信徒”的一道数学题
很多人——尤其是美国西海岸那拨人——坚信只要把大模型继续做大、喂点合成数据、在后训练里加点强化学习的小技巧,就能通向 AGI。LeCun 说:不可能。然后,他当场算了一笔账。
同样是 10¹⁴ 字节的数据,文字花了 40 万年,视觉只用了 4 年
大模型这边 训练数据约 20 万亿词 ≈ 30 万亿 token
换算成字节 约 10¹⁴ 字节(整个互联网的公开文本)
人类要读完 得花上 大约 40 万年
一个 4 岁小孩 醒着的时间约 1.6 万小时
通过视觉摄入 约 200 万根视神经、每根每秒约 1 字节 → 也是 10¹⁴ 字节
结论一目了然:一个 4 岁孩子通过眼睛看到的数据量,和人类有史以来全部文字、要读 40 万年才能读完的量,是一个量级。而孩子只用了 4 年。换句话说,光靠“读字”这条路,根本喂不出人类水平的智能。
“那视频不是比文字冗余多了吗?”有人会这么反驳。LeCun 的回答很妙:冗余是特性,不是 bug。要做自监督学习,数据里恰恰需要冗余——没有冗余,你什么都学不到。当然,冗余也别太多就是了。
🌟光靠在文本上训练,我们永远不会得到任何接近人类的智能。这事不会发生。真实世界是混乱的,相比之下,语言反而简单得多。
三|LLM 的死穴:它只会“往前推”,不会“想”
就算抛开数据量,LeCun 认为大模型的“思考方式”本身也有结构性缺陷。一个聪明的系统,关键看它怎么“推理”。
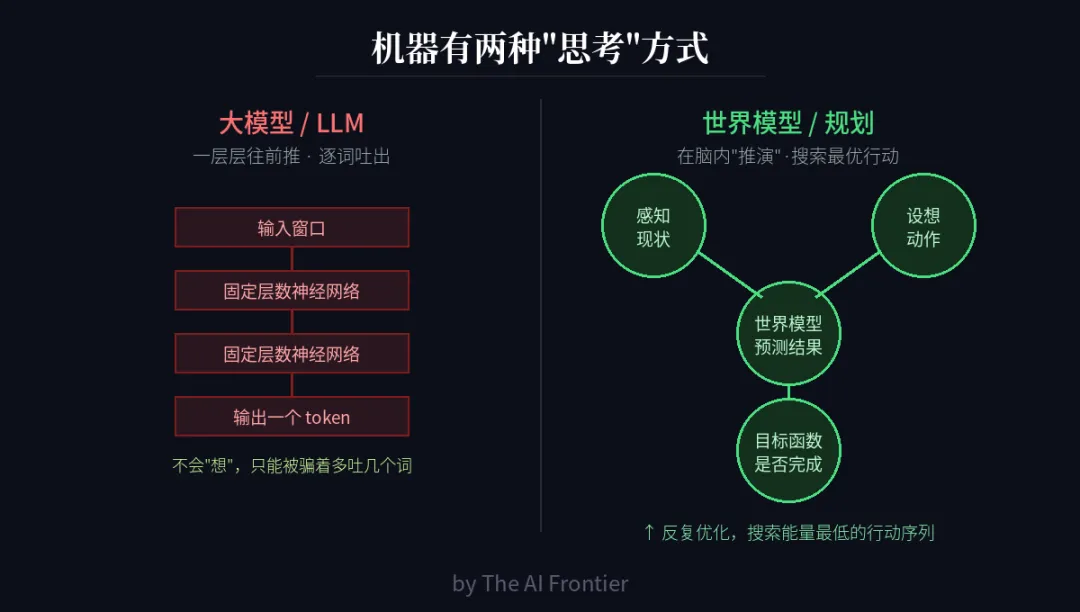
左:大模型逐层前向传播、逐词输出;右:世界模型在脑内推演、搜索最优行动
大模型的做法:拿一段输入,过一遍固定层数的神经网络,吐出一个 token;再把这个 token 拼回去,吐下一个……这就是“自回归预测”。每个词的计算量都是固定的、有限的。LeCun 说这不是好的推理模型——你让大模型“推理”,其实是在骗它多吐几个词(思维链)。可人类不是这么想事的,我们是在脑子里推演,根本不在“词”的空间里思考。
他主张的做法:你感知到当前世界的状态,然后在脑内“设想”一串动作,把它喂给一个内部的世界模型,让它预测这串动作会带来什么结果,再用一个“目标函数”去衡量任务有没有完成。最后,通过反复优化,搜索出那串“能量最低”、最能达成目标的动作。这就是“用优化来推理”,而不是“用前向传播来推理”——计算上本质更强大。LeCun 早在 2022 年就把这套架构写成了长文放到网上。
这套架构还顺手解决了一个大问题:安全。你可以给系统加上“护栏目标”——无论它想让世界往哪走,都不能伤人、不能造成恶果。因为它除了优化目标和护栏,啥也干不了,所以这种系统理论上无法被越狱。而大模型只能靠微调来“对齐”,总有办法被 jailbreak 绕过去。
一个去巴黎的例子,讲清“分层规划”
LeCun 说,人和动物都会“分层规划”,但机器还不会,这是个完全开放的难题。他举了个特别接地气的例子:他坐在纽约大学的办公室里,想明天出现在巴黎。
他不可能把整趟行程拆成“每 10 毫秒动一下哪块肌肉”来规划——太长了,而且信息根本不够(他都不知道下楼后要等多久才能拦到出租车)。于是他只能分层:高层先定个两步走的大计划——去机场、赶飞机;“去机场”这个子目标,再拆成下楼、拦车、抵达;“下楼”又拆成走到电梯、按按钮、出门……一层层往下,直到某一步简单到你不用动脑、站起来这种事一个“策略”就搞定。
🌟如果你要读 AI / 机器人方向的博士,“分层规划怎么做”是个绝佳的题目——它完全开放,至今没人证明自己真的解决了它。
四|15 年的失败:为什么“视频生成”根本不是世界模型
说到这,你可能会问:那“世界模型”到底怎么训练?LeCun 在这件事上栽过大跟头——他做了 15 年,头 10 年基本都在失败,因为他一直试图训练“生成式模型”。
生成式那一套,在语言上简直神了:盖住句子里的一些词,让神经网络去还原——BERT 就是这么干的,而大模型是它的特例(只盖最后一个词,专门预测下一个)。可这招一搬到视频上就崩了。
为什么?LeCun 打了个比方:拿摄像机拍这间屋子,慢慢转一圈停下,然后让系统“接着往下预测画面”。它大概能猜到这是个礼堂、有窗户、空间有限……但它绝对没法预测你们每个人长什么样、哪把椅子是空的——信息根本不在那里。一段视频后续的可能性是无穷多的,你逼系统在像素层面去预测“一切”,等于把它逼死。
“那那些能生成漂亮视频的模型算什么?” LeCun 说,那些系统的预测通常发生在“表征空间”,而且它只需要生成一段看起来不错的视频就行,并不需要表示所有可能的视频——那是个简单得多的问题。
他的解法:JEPA——别在像素里死磕,去抽象空间预测
LeCun 的方案叫 JEPA(联合嵌入预测架构)。核心区别:生成式是观察 X、还原出 Y 的所有细节;而 JEPA 是把 X 和 Y都先编码成表征,预测发生在表征空间里。这样系统就能主动“扔掉” Y 里那些根本无法预测的信息,预测变得更抽象、细节更少,但反而更准。
为什么“扔掉细节”反而对?因为人类做科学就是这么干的。原则上你可以用量子场论模拟这间屋子里每个粒子的轨迹,从而推断出谁在听我讲、谁睡着了——但这完全不现实。所以我们发明了一层层抽象:从粒子到原子、分子、蛋白质、细胞、个体、社会……每一层都忽略下面的大量细节,换来更长程的预测能力。设计飞机时你算空气动力学,把空气当成有速度和密度的小立方体,绝不会去模拟每个空气分子的碰撞——那不仅算不动,还会因为细节太多而迅速偏离现实。
🌟世界模型不该是“模拟器”,也绝不该是视频生成。很多人做视频生成还管它叫世界模型——那不是世界模型,那就是视频生成。一句忠告:想造能控制机器人、看懂世界的系统,就别去搞视频生成;想做好看的视频,那才去搞生成。