刚刚,GPT-5.5被中国纯血AI反超了新智元
刚刚,国产纯血大模型彻底逆袭了!在医疗领域全面碾压GPT-5.5,狂揽双料第一,91%的医生直呼敢用。
刚刚,医疗大模型赛道的魔咒,终于被打破了!
过去两年,医疗大模型是AI落地中关注度最高的赛道之一,也是公认最难啃的一条。
几乎每家大厂都会端出一个「会看病」的LLM:发布会上对答如流,PPT里指标霸榜。
然而,一旦把它放进诊室,医生用两次就默默关掉了。
归根到底,「能上台演示」和「能下场干活」之间的那道坎,真正迈过去的屈指可数。
但这几天,剧情迎来了反转。
飞利浦最新发布的《2026未来健康指数》里,藏着一个极具画面感的数据。
27%的临床医生承认,就在过去九十天里,屏幕里那个曾经被嫌弃的AI,已经至少三次帮他们揪出了潜在的医疗差错。
但故事还没完。
就在这几天,一家中国公司直接把一份更为硬核的答卷拍在了桌面上。
星火医疗大模型V3.5
医生采纳率91%
6月9日,讯飞医疗正式发布——星火医疗大模型V3.5。
生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。
这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。
要理解此版本发布的分量,先得理解它跨过的那道门槛到底有多高。医疗是所有AI落地场景里最苛刻的一个,原因有三。
▪︎医疗场景容错率近乎为0
在教育、营销、客服领域,大模型偶尔「一本正经地胡说八道」,代价是一次返工。
但在诊室里,一个错误的用药建议、一处遗漏的影像征象,关乎的是人的健康乃至生命。
这意味着医疗大模型,不能只是「大概率正确」,它必须做到可验证、可溯源、可问责。
▪︎真实场景远比Demo复杂
发布会上的「AI问诊」,往往是安静房间里、一个人对着麦克风的清晰口述。
可真实诊室是什么样?
多位医生、患者、家属同时说话,远场嘈杂,方言夹杂,病情陈述断断续续。
能在录音棚里转写得完美的模型,一进诊室就「失聪」。
▪︎医生的工作流不容打断
医生最稀缺的是时间,一个需要医生反复修改、二次校对的AI工具,本质上是在增加负担。
它必须无缝嵌进医生既有的工作流,让人「用了就回不去」,才谈得上真正落地。
这三道坎,过去鲜有医疗大模型能同时跨过。
而星火医疗大模型V3.5最大的价值,恰恰在于它在临床最刚需的几个场景里,同时把三道坎踩在了脚下。
医生愿不愿意用
才是唯一的标尺
实际上,「实用门槛」的定义很朴素:
医生在真实的临床场景里,拿到AI生成的结果,愿意直接采纳。
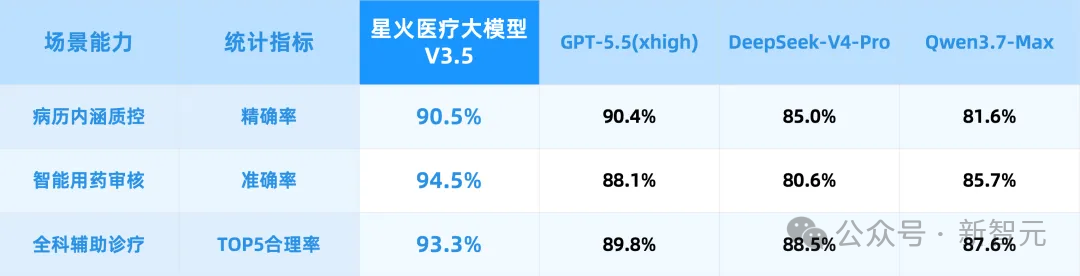
这个标准下,星火医疗大模型V3.5在三大核心场景下,交出了硬数据。
病历生成,时间砍半
病历书写,是临床医生日常工作中最耗时、最痛苦的环节之一。
很多医生白天看完门诊,晚上还得花两三个小时补病历。
星火医疗大模型V3.5,在病历场景实现了全维度技术升级——
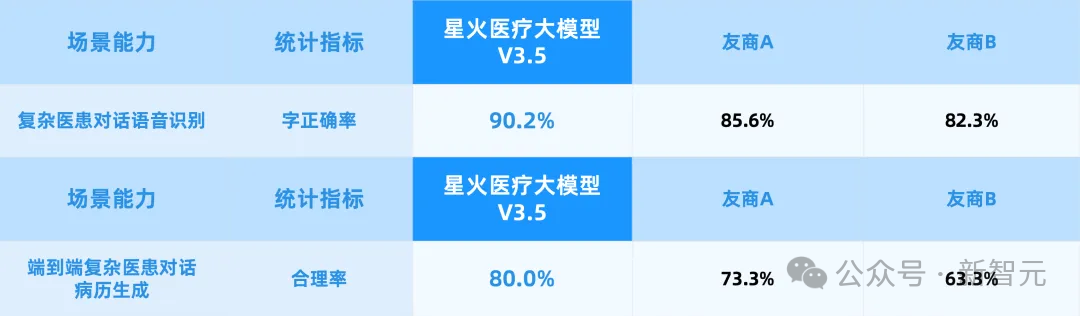
突破了多源医患远场识别、多角色定向语音增强、医疗语音识别非自回归架构等多项核心技术。
在医生和患者对话的过程中,星火医疗大模型V3.5通过远场多说话人语音识别,实时抓取对话内容,端到端自动生成结构化病历。
结果,端到端病历生成合理率达到80%。
落到真实临床,在多家头部三甲医院的应用中,生成病历的医生采纳率达到91%,病历书写时间缩短52%。
有一组数据很扎心:一位门诊医生日均要接诊100位患者,边接诊边手写录入一份高质量病历,平均需要2.5分钟。
100位患者,意味着每天有超过4个小时耗在「码字」上。
医生这个职业,正在被文书工作活活拖垮。
而用AI病历生成系统,医患对话结束后30秒,一份同等质量的规范病历自动生成——一天下来,就能省出2.8小时。
正因如此,91%的病历采纳率才显得分量十足——
AI生成的病历,超过九成医生看一眼就能直接用,几乎免修改。
星火医疗大模型V3.5精准砍掉了那一半的文书负担。那些本该属于病患的时间,现在终于可以还回去了。
AI读片,采用率75%
影像辅诊是医疗AI最早被寄予厚望、也最容易「翻车」的方向。
放射科医生看一张CT或MR,要在多个序列间来回对照、结合临床信息判断,再用规范医学语言写成报告。
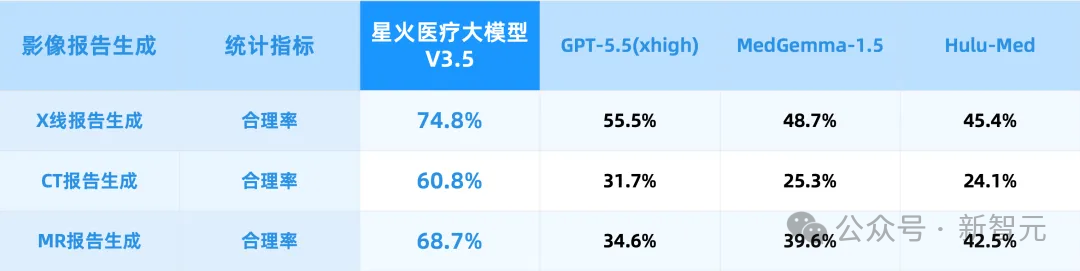
星火医疗大模型V3.5靠多序列联合空间建模和影像-文本跨模态推理,把识别和报告生成打通成一个动作——输出的不只是「片子上有什么」,还有「意味着什么、下一步怎么办」。
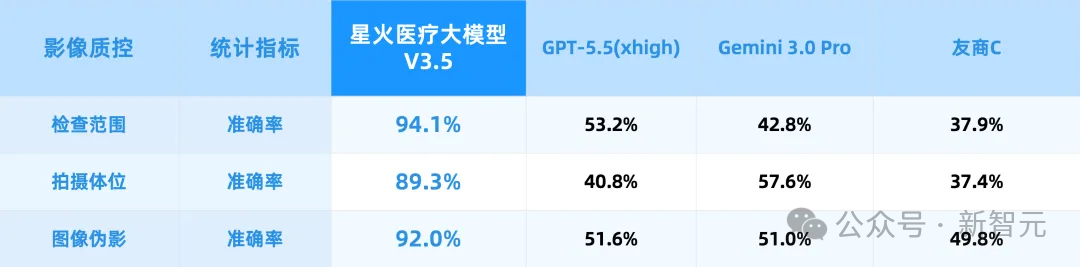
结果,X线、MR报告生成的医生采纳率达75%,影像质控达到专家会诊水准。
75%初看不如91%亮眼,但影像报告的专业性和复杂度远高于文字病历,这是全球医疗大模型首次在真实临床场景跨过这道线。
循证诊疗助理智能体,一个随身的「医学图书馆」
如果说前两者解决的是「效率」,那么循证诊疗助理智能体解决的是「决策质量」。
做过临床决策支持的人都知道,医生最怕的不是AI「不够聪明」,而是AI「太自信地错」。
星火医疗大模型V3.5循证诊疗助理智能体,采用了「证据对齐—反思校验—专家强化」的技术路径。
核心是,每一个诊疗建议都能追溯到权威医学文献,支持多步推理和深度反思。
它覆盖了病历内涵质控、智能用药审核、全科和跨专科辅助诊断等多个刚需场景,背后接入了大量权威诊疗指南和专家共识,同时兼容中国诊疗规范和中西医双诊疗体系。
如果要找一个国际对标——大洋彼岸的OpenEvidence,现估值已达120亿美元。