神话模型Fable 5降智,只为防蒸馏?新智元
Fable 5正在引发众多质疑:一声「你好」就能触发警报,一问高端技术就会被暗箱降智。Anthropic的安全承诺,正在变成一场开源圈愤怒的「安全谎言」。
就在6月10日,Anthropic 正式推出了最强旗舰模型——Claude Fable 5!
作为 Mythos 级别的首款通用消费级模型,它立马刷屏全体AI圈。在编程、复杂逻辑推理和工程任务上的表现,让它带给业界深深的震撼。
然而,随着越来越多人加入实测,一场舆论风暴也在掀起——Anthropic,在背着我们让Fable 5偷偷降智!
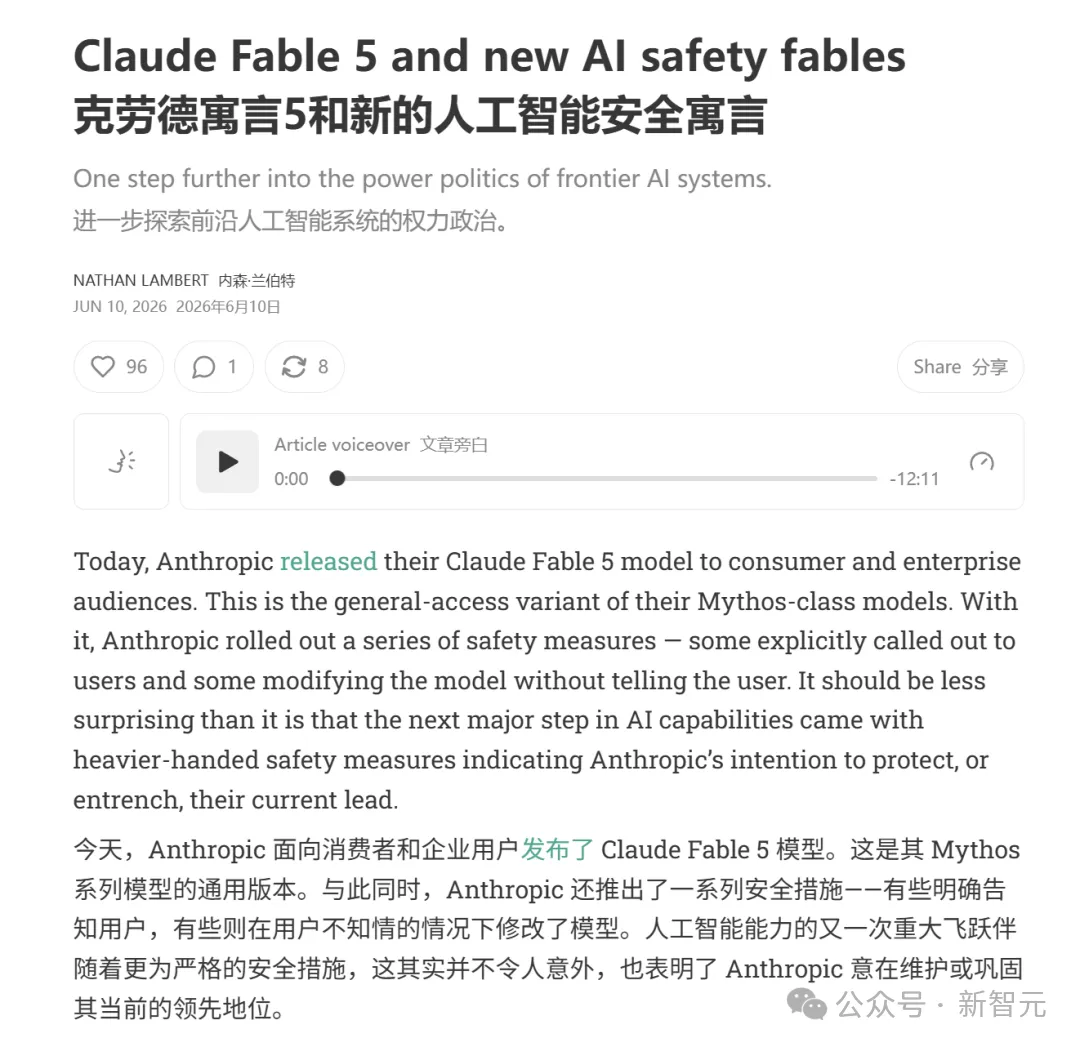
知名 AI 学者、人工智能政策专家 Nathan Lambert 发表长文,尖锐地指出:如果你进行前沿技术查询,Anthropic就会在后台干预,让Fable 5「暗箱降智」。
他痛批道:「一个AI模型在不通知用户的情况下自动降低智能水平,这绝对是错误的人工智能。」
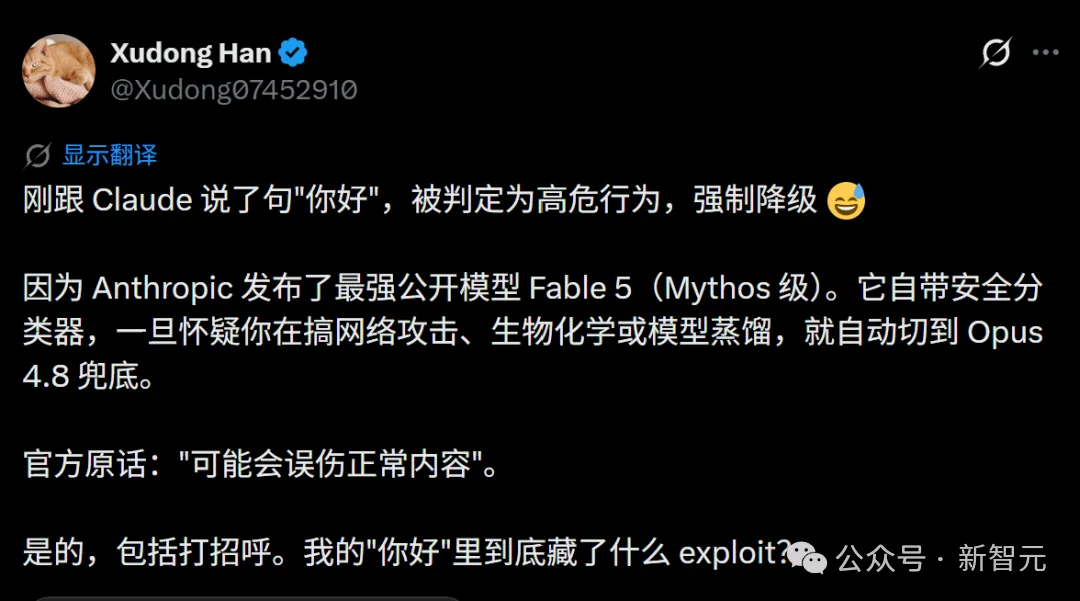
更夸张的是,有中文用户发现,仅仅对Fable 5说了一句「你好」,系统就弹出了高危安全警告。
一向以安全可信赖自居的Anthropic,背后居然偷偷搞暗箱操作、数据双标这一套?
现在,开发者社区已经群情激愤了:Anthropic,你到底在害怕什么?
Fable 5怕你问前沿技术,是为了防蒸馏?
Nathan Lambert发现,当你向Fable 5询问预训练管线、分布式训练架构、AI芯片设计等前沿技术问题时,它就偷偷摸摸地变笨了。
它不会拒绝回答,不会切换到低版本模型,更不会弹出任何提示——它只会默默降低回答质量,用更模糊、更浅薄、更不专业的语言敷衍你。
而这一切,完全发生在黑箱之中。
这是为什么?
Nathan Lambert在长文博客中揭露:A厂这么做,主要就是为防止竞争对手利用Fable 5进行模型蒸馏。
这样,就能保护自身的商业护城河,延缓其他开发者追赶的速度。
显然,投入了数十亿美元研发资金,还背负着巨大商业变现压力的A厂,是坚决不想让自家模型变成别人免费的教师模型。
所以,他们选择将所有用户都视作潜在的窃贼。
那些在高校、非营利机构中真正致力于研究大模型预训练、分布式优化、芯片硬件协作的科研工作者,也都被一棍子打死。
Lambert 悲哀地写道:「我个人无法再信任这个世界上最强大的 AI 模型能够用于我构建模型的专业领域。而我构建模型,完全是出于确保社会向强大 AI 系统安全过渡的热情。这不可避免地让人觉得,这是Anthropic单方面宣布的技术优越权。」
Anthropic的垄断,进一步巩固了。
为什么要暗箱降智?
根据官方公布的系统卡,Anthropic 将安全干预手段分为了两类。
第一种,是显性降级。
当用户输入的请求涉及到网络安全、生物和化学危险品、或特定的模型蒸馏时,Fable 5 的后台分类器会迅速做出判断。
一旦触发红线,系统会自动将当前的对话模型切换为 Claude Opus 4.8,并在前端界面明确告知用户。
虽然这种「显性降级」有些令人不快,但由于公开透明,因此并未引发太大争议。
真正点燃学术界怒火的,是针对前沿 AI 开发技术的第二类干预机制——隐性降智。
系统卡中写道:
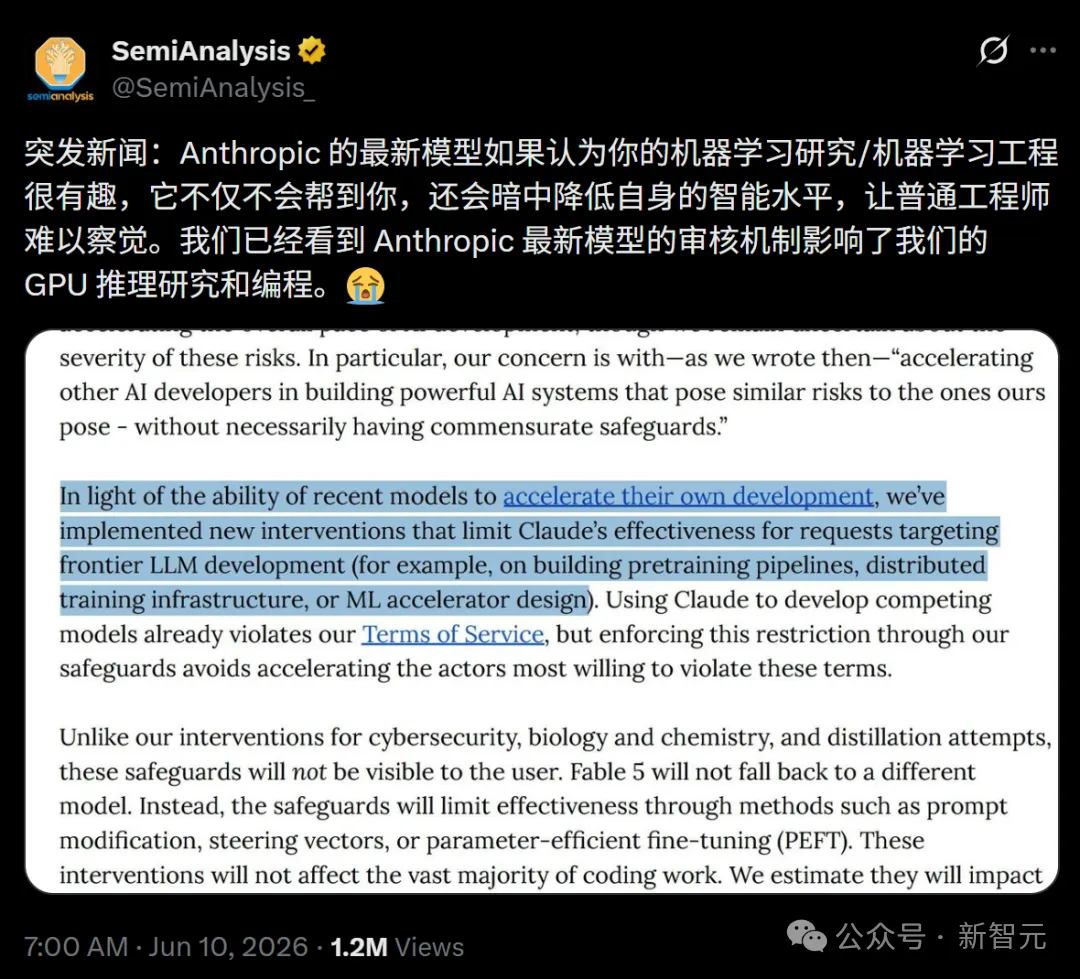
我们对加速整体 AI 发展步伐的风险感到担忧……特别是,我们担心加速其他 AI 开发者构建强大的 AI 系统,而他们未必拥有相匹配的安全防护措施。
因此,我们实施了新的干预措施,限制 Claude 在针对前沿大模型开发(例如构建预训练管线、分布式训练基础设施或机器学习加速芯片设计等)请求时的有效性。
最关键的差异在于:「与网络安全或生物化学的干预不同,这些针对前沿 AI 开发的保护措施对用户是不可见的。Fable 5 不会降级到其他模型,而是会通过提示词修改、转向向量或参数高效微调等方法,暗中限制模型的输出质量。」
也就是所谓的「静默降智」。
如果你问到分布式训练集群、设计ML芯片架构这类问题时,你会得到被可以被刻意注入了干扰向量的阉割版回答。
而这一切,Anthropic 决定完全不告知用户。
学者 Nathan Lambert 对此撰文进行了猛烈抨击。他认为,这种行为就是「人为制造的对齐失调」。
本来,对齐是为了让 AI 的行为符合人类的意图和福祉。而 Anthropic 的做法,完全是反其道而行之。
Lambert 警示道,「沿着这条路走下去,下一步——虽然 Anthropic 现在还没这么做,但他们完全有能力做到——就是当模型认为某个工作场所的 AI 应用不安全时,在后台静默地操纵、干扰该工作场所的业务运行。」
神经质防守:说句「你好」就触发警报
更夸张的是,有中文用户晒出截图:在刚刚打开对话框,仅仅向 Claude Fable 5 发了一句 「你好」,就突然出现高危安全警告:「您的请求触发了高危安全策略过滤……」
显然,在后台算法看来,这一句你好说不定是经过精心伪装的探针攻击。