AI如何读懂中国文明?腾讯数字文化
汉字是中华文明的经纬。从殷墟甲骨到现代楷书,三千年的文字演变史,也是一部视觉特征不断漂移、介质环境高度复杂的演化谱系。
5月18日,腾讯混元、SSV数字文化实验室和SSV技术架构部联合安阳师范学院甲骨文信息处理重点实验室、中科院信工所、南开大学,正式推出 Chronicles-OCR——业界首个覆盖"七体之变"完整演化轨迹的中国古文字感知评测基准。这一基准的发布,不仅照向中国文化遗产数字化的进路,也与此前发布的全球首个甲骨文智能体“殷契行止”共同构成了 AI 守护古文字的技术闭环。
OCR链接:https://github.com/VirtualLUOUCAS/Chronicles-OCR
现代 OCR 的"舒适区",从来不是真正的中国汉字史
想要让 AI 真正服务于数字人文(Digital Humanities),它不能只擅长识别打印机吐出的宋体和黑体,它必须能跨越时间的长河,从甲骨上歪歪扭扭的契刻、青铜器上漫漶的铭文、石碑上风化的刻痕中,把字一个一个地"认"出来。
回想一下 OCR 模型每天都在面对的现代场景:清晰的边界、统一的拓扑、规整的版式、干净的载体。在 OCRBench、OmniDocBench 这类现代评测中,主流多模态大语言模型都已经表现得相当成熟。
但中国汉字的真实历史完全不是这样的。
图:汉字"虎"的演化轨迹——从甲骨到草书
把镜头从今天往回拨——
退到行草,字与字的边界开始糊在一起
退到隶篆,字形的拓扑结构与现代汉字已经完全不同
再退到金文与甲骨文,符号变成了无标准化、刻在龟甲兽骨青铜器上的图画
而载体本身——龟甲的裂纹、青铜的锈蚀、石碑的风化、绢本的褪色——又给视觉感知叠加了一层厚厚的"噪声滤镜"
这是一次横跨三千年的视觉分布漂移(distribution shift)。
甲骨文智能体的率先破局
面对这些难题,2025年发布的甲骨文智能体“殷契行止”率先在甲骨文这一源头领域取得了突破。
长期以来,甲骨文研究一直面临“识别难、比对难、共享难”的挑战。由于拓片噪声复杂、字形异构多变,通用大模型难以理解甲骨文的特征规律。基于腾讯云智能体开发平台,腾讯优图实验室联合腾讯SSV数字文化实验室、甲骨文信息处理实验室、厦门大学人工智能研究院,以 AI + 多模态语料融合为基础,研发出多项关键技术,包括部首识别、字形匹配、拓片摹本目标检测、拓片摹本生成、重片检测等原创算法,以及融合单字、释文、甲骨片图片的多模态检索能力。
这些针对性算法的引入,使得 AI 首次具备了“理解古文字”的能力,有效解决了通用模型在专业领域中的适配难题,最终让每一片甲骨“读得懂、找得到、用得上”
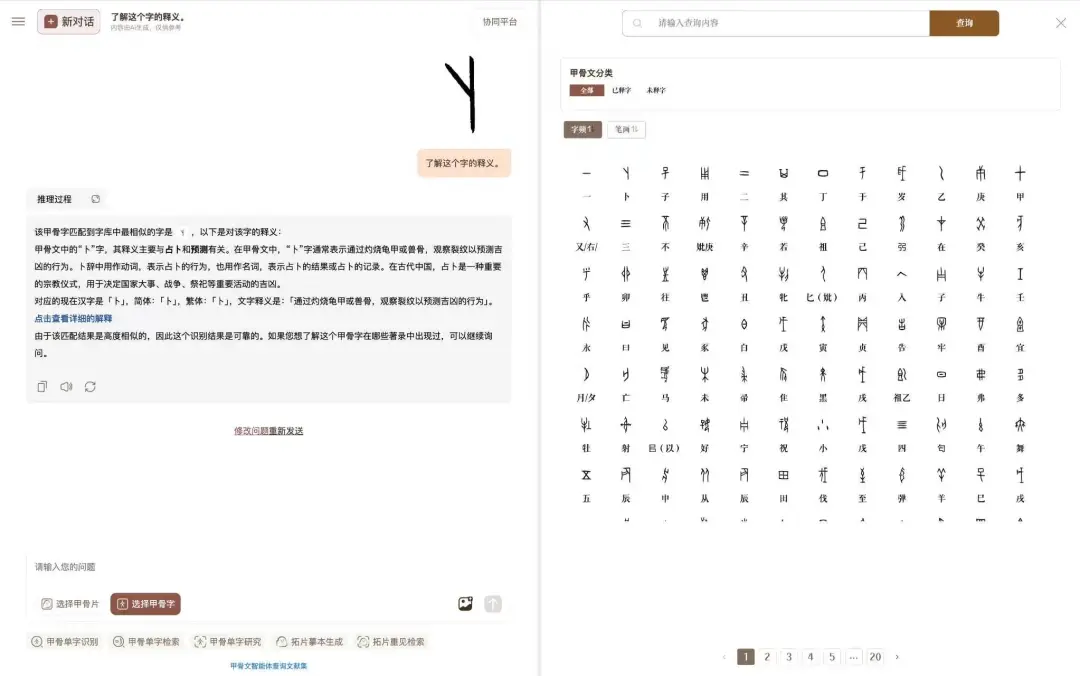
同时,该智能体面向专家与公众免费提供“双端服务”,用户只需上传一张甲骨图片,AI 即可完成文字识别、释义查询、文献溯源和数字摹本生成。在专业端,甲骨文AI协同平台为古文字研究者提供智能识别、比对与检索工具,显著提升研究效率;在公众端,可以通过“了不起的甲骨文”微信小程序就轻松体验甲骨识读的乐趣,获取古文字知识,让千年前的文明真正“活”在掌心。
Chronicles-OCR:七体之变,同卷竞技
汉字之所以是汉字,是因为它从未停止演化。
在甲骨文这一源头领域实现单点突破后,新的挑战随之而来:我们该如何衡量 AI 对汉字三千年完整演变史的理解程度?
从殷墟的甲骨到此刻你手机屏幕上的这段文字,每一笔每一画都承载着这个文明的连续性。让 AI 看懂这条连续性,是技术问题,更是文化课题。
为了精准衡量大模型在汉字演化全谱上的视觉感知能力,腾讯混元、SSV数字文化实验室和SSV技术架构部联合安阳师范学院甲骨文信息处理重点实验室、中科院信工所、南开大学,正式推出 Chronicles-OCR——业界首个覆盖"七体之变"完整演化轨迹的中国古文字感知评测基准。
数据来源全部来自顶级机构与古文字学专家:
甲骨文 → 安阳师范学院甲骨文信息处理重点实验室
金文、篆书 → 古文字学博士与研究生团队人工整理
隶、楷、行、草 → 故宫博物院文物手写体识别测试数据集
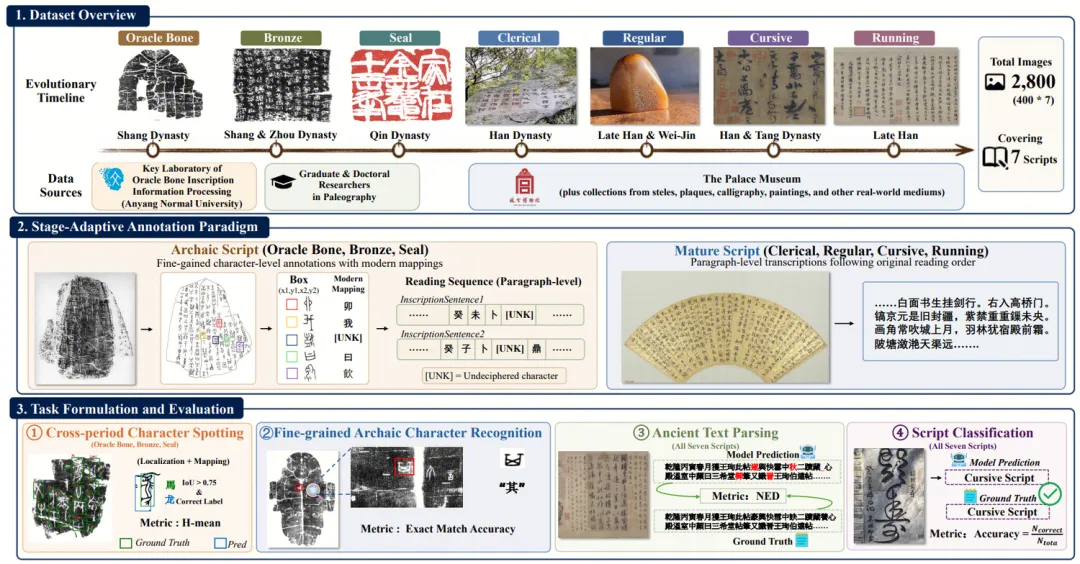
整个数据集由领域专家多层级交叉标注,包含 2,800 张严格平衡的高质量图像(每种字体 400 张)。
图:Chronicles-OCR 数据示意图——从龟甲到宣纸的真实物理介质
阶段自适应标注范式(Stage-Adaptive Annotation Paradigm)
不同时代的汉字"难"在不同的地方,所以评测方式必须分阶段定制。Chronicles-OCR为不同字体设计了两套标注体系:
1.古早字体(甲骨、金文、篆书):字符级精细标注
由于古早字体形态高度不稳定、布局无约束、载体噪声严重,我们提供:
单字级 bounding box
现代汉字映射(字一对一翻译到现代汉字)
对学界至今未释读的字符,统一标记为 [UNK]
段落级阅读顺序
2.成熟字体(隶、楷、行、草):序列级转写
由于成熟字体已具备相对稳定的版式与高字间区分度(尤其草书是连笔的,强行框字反而错),我们采用:
行/段落级的逐字转写
严格保留原始阅读顺序
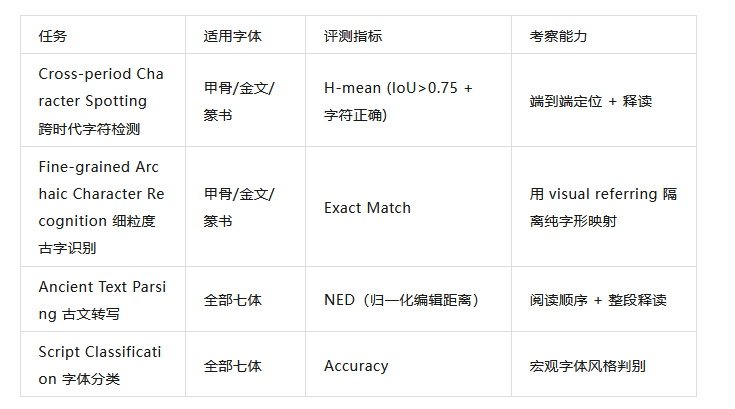
四大核心任务
基于上述标注,Chronicles-OCR设计了四个层层递进的任务,严格地把"视觉感知"和"语义推理"解耦开来:
特别值得一提的是 fine-grained recognition 这一任务:当古文字学家面对一个模糊的甲骨符号时,他们不会输入"x1, y1, x2, y2"这种坐标,而是直接用手指。所以我们用 visual referring 机制——直接在图上画一个有色框,让模型回答"红框里这个字是什么"。这样就把"找得到"和"认得出"彻底分离开。
Chronicles-OCR的核心发现与结论
Chronicles-OCR项目评测了 28 个主流的开源与闭源多模态大语言模型,包括 GPT-5、Gemini 3.1 Pro、Claude Opus 4.7等一线模型。结果令人意外:
发现 1:在古早字体上,端到端 Spotting 全军覆没
图:甲骨文、金文、篆文上的检测可视化——漏检、错认、幻觉三连
GPT-5、Gemini 2.5 Pro 在跨时代字符检测任务上 H-mean 接近 0
表现最强的模型也只有16.5
模型出错有三种典型形态:
1.Missed Detection:完全漏掉龟甲上斑驳的刻字
2.Hallucination:把青铜锈斑、石碑裂纹幻觉成"字"
3.Recognition Error:定位对了,但映射不到正确的现代字
这说明现代 VLLM 严重依赖"现代版式先验"——一旦面对无约束、不规则、强噪声的古代物理介质,它们用来分割文本的内部机制就直接失效了。
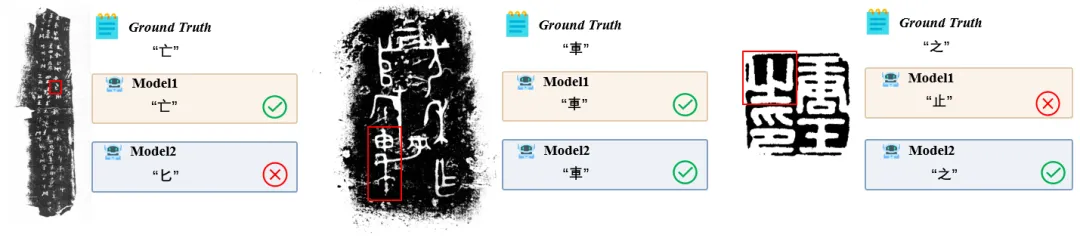
发现 2:哪怕给你画好框,也认不出来
为了验证这一点,Chronicles-OCR用 visual referring 把"定位"这一步完全免掉——直接画一个红框,问"框里是什么字"。