压缩的本质:数据消失的字节去哪了?黑盒与白箱
0. 打破无损的基准:我们真的需要全部信息吗?
上篇我们花了很大力气追问同一个问题:压缩的极限在哪里?香农熵给出了统计回答,柯氏复杂度给出了算法回答,两种视角在深层统一。而所有这些讨论,都默认了一个前提——我们要保留全部信息,分毫不差。
但这里还有一个更根本的问题:我们真的需要全部信息吗?
不妨看看这个世界上最顶级的“压缩器”——人脑。你昨天走过的街道,你记不住每一块地砖的纹理;你听过成百上千次对话,却没有一次能逐字复述。但你记得街道的走向,记得对话的要点。人脑本身就是一套巨大的有损压缩系统:它从海量感官数据中提炼出一个内部模型——一个关于世界的“隐空间”——只保留那些对生存和预测真正有用的结构,把其余细节果断丢弃。
这正是有损压缩的根本动机:不是为了省硬盘空间,而是为了理解。 当我们主动丢弃信息时,一个在无损压缩中被回避的问题浮现出来:依据什么标准来判断“重要”还是“不重要”?
1. 率失真理论:用数学描述“不重要”
率失真理论的核心问题就是:当我们允许一定程度的失真时,传输信息所需的最低比特数是多少?这个最低比特数如何随着失真的增大而减少?
1.1 一个思想实验:猜年龄
上篇我们用存储来讲压缩,下篇换一个同样本质的场景——传输。压缩是把数据变小,存进硬盘跟传过网线,数学上是同一件事。
你要通过电话告诉朋友一个人的年龄,精确到几岁几月几天——比如 27 岁 3 个月零 15 天。这需要传输相当多的数字。这就像无损传输——你必须完美复述每一个细节。
但朋友说:“行了,我只需要知道他大概是‘幼年’(0–12 岁)、‘青少年’(13–19 岁)、‘中年’(20–59 岁)还是‘老年’(60 岁以上)就行。我不需要知道那么精确的年龄。”
这就是引入了失真。当你允许失真 ——也就是告诉朋友“我不需要精确年龄,四档就够了”——你需要传输的信息量 急剧下降。四档只需要区分四种状态,用 2 个比特就够(00、01、10、11 分别代表幼年、青少年、中年、老年)。
率失真理论的核心问题就是:当我们允许一定程度的失真时,传输信息所需的最低比特数是多少?这个最低比特数如何随着失真的增大而减少?
1.2 率失真函数 R(D):定义与数学形式
1948 年,香农在同一年不仅提出了信息熵,还提出了率失真理论。这个理论的形式化定义如下:
1.3 一个具体算例:猜年龄
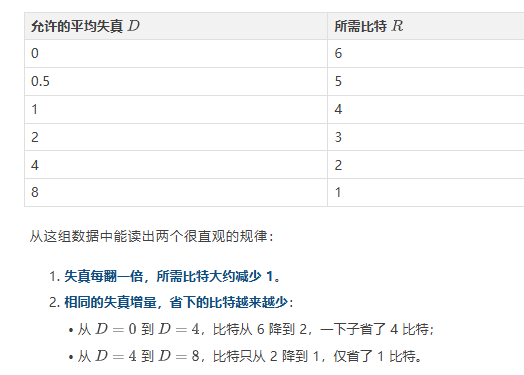
设定:假设所有人的年龄均匀分布在 0 到 63 岁之间,共 64 种可能。信源熵 比特——无损传输时,每个年龄值需要 6 比特(刚好用 6 位二进制表示 0–63)。
现在允许有损传输。失真度量用绝对误差:,即重建年龄和真实年龄相差多少岁。
我们可以用一种最朴素的方法来构造有损方案:把 0~63 岁分成若干组,只传输组号,接收方收到组号后取该组的中间值作为年龄估计。组分得越粗,需要传输的组号越少,比特数就越低,但每组覆盖的年龄范围越大,平均误差也越大。
顺着这个思路,很容易得到一系列“速率–失真”对应关系:
• 只用 1 比特(分 2 组):{0~31} 和 {32~63},重建值取每组中点 15.5 和 47.5,组内平均误差为 8 岁 → 时只需 1 比特。
• 用 2 比特(分 4 组):每组 16 个年龄,平均误差 4 岁 → 时只需 2 比特。
• 用 3 比特(分 8 组):每组 8 个年龄,平均误差 2 岁 → 时只需 3 比特。
• 用 4 比特(分 16 组):每组 4 个年龄,平均误差 1 岁 → 时只需 4 比特。
• 用 5 比特(分 32 组):每组 2 个年龄,平均误差 0.5 岁 → 时只需 5 比特。
• 用 6 比特:不分组合,无损传输,。
整理成表格能看得更清楚:
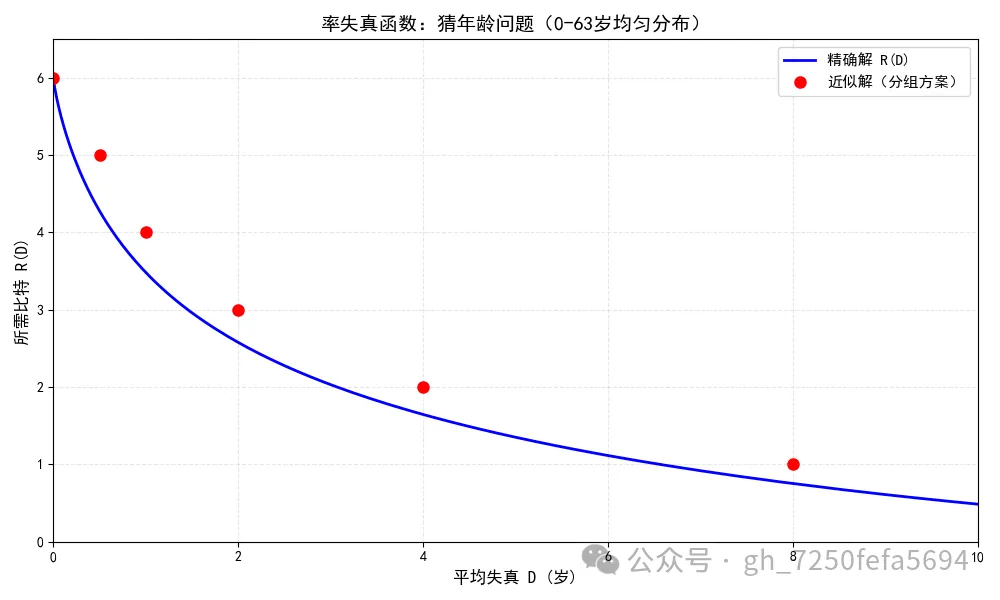
画在图上, R(D)就是一条从 6 开始、向右下方逐渐变平缓的曲线。这正是率失真函数凸性的直观含义:在失真很小的时候,稍微放宽一点限制,就能换来比特数的大幅下降;而当失真已经比较大时,再继续放宽,节省比特的效果就越来越有限了。
需要注意的是,这里列出的比特数只是通过简单分组得到的一个可达方案(即率失真函数的上界),并非精确的 值。真正的 还会更低一些(见上图的红色点和蓝色线,红点表示分组结果,蓝色线为理论值)。
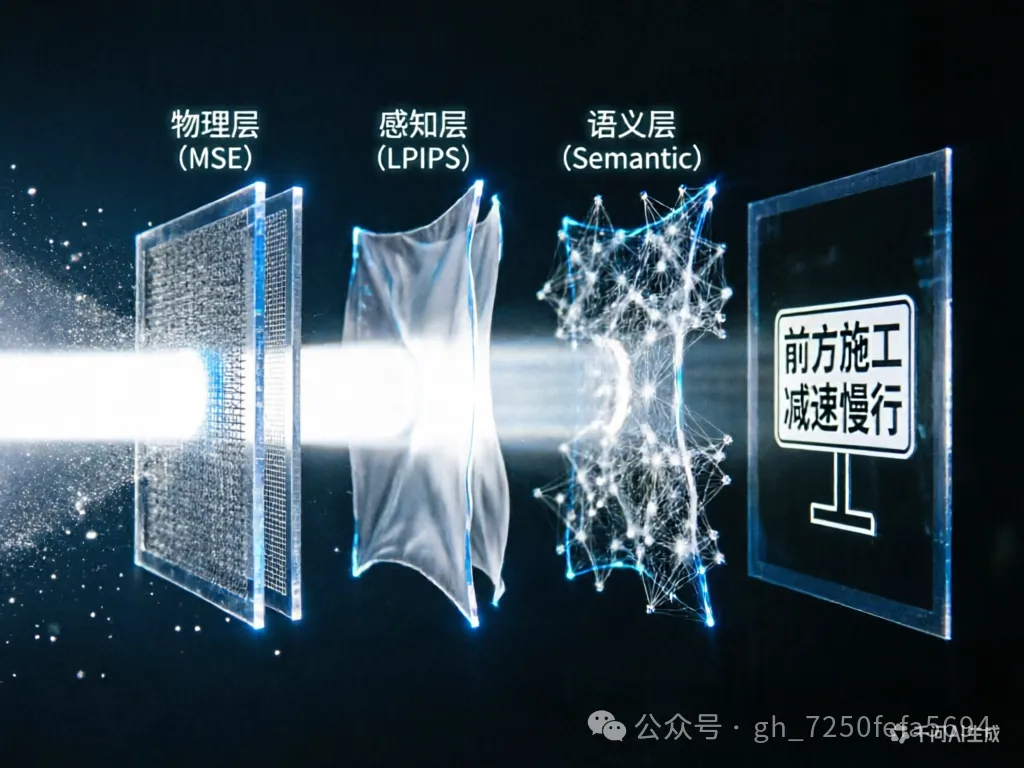
2. 重要性的光谱:从物理保真到语义保真
率失真理论给出了一套精密的数学框架,但它绕开了一个关键问题:失真度量 本身怎么定义? 什么算“差得多”,什么算“差得少”?
在传统数据压缩里,最常用的失真是平方误差(MSE):把原始信号和重建信号的每个数值的差的平方加起来,越小越好。这个度量好算、好优化,但它有一个致命的盲区:它把每个数值的偏差等量齐观,不管你偏差的是什么。图像压缩里,一个像素的微小色偏和另一个像素的巨大色偏,在 MSE 的账本里只是数字不同,没有本质区别。但人眼对某些区域的偏差极其敏感(比如人脸),对另一些区域几乎无感(比如天空的纹理)。MSE 不关心这些。
这个看似技术性的选择——怎么定义“失真”——背后是一整套关于“什么重要”的哲学立场。“重要性”不是一个非黑即白的问题,更像一道光谱,每一层对应着不同的“保真”标准。
2.1 第一层:物理保真——逐点都对
最传统、也最易于数学处理的标准正是平方误差(MSE)。
在图像压缩里,这意味着每个像素的颜色值都要尽量接近原始值。在音频压缩里,这意味着每个采样点的幅度都要尽量吻合。
这种标准的哲学是物理还原论:信号的全部意义就在于其波形的精确幅度。“重要”的,就是“客观存在的每一个波动”。你改动哪怕一个肉眼根本看不出来的像素,在 MSE 的账本里也是一笔赤字。
但这里有一个致命的问题:很多物理细节,人眼和人耳根本感知不到。一张 MSE 极低的图像,人眼看可能是布满精细噪点的乱码;一张 MSE 略高但噪点被智能抹除的图像,人眼看反而觉得更“真实”。
2.2 第二层:感知保真——看起来真
这就是感知保真要解决的问题。它的标准不再是“逐点都对”,而是**“看起来真”**。
这个判断由一个经过训练的深度神经网络来做出:它能区分重建图像和原始图像在“分布层面”的差异。也就是说,如果你把重建后的图像和原始图像混在一起,即使是最敏锐的判别器也分不出哪张是重建的、哪张是原始的——这就叫分布不可区分。那些会被人眼察觉的失真,才是真正的失真;而那些视觉上无感的纹理差异、微小的色彩偏移,尽管丢弃。
核心洞见:能改变语义概念的细节才重要,视觉上无感的噪声尽管丢弃。 “看起来真”压倒了“逐点都对”。
2019 年,Blau 和 Michaeli 将感知保真正式纳入了率失真的理论框架,提出了率-失真-感知函数(RDPF)。具体来说,R(D) 只约束平均失真,而 RDPF 额外要求重建信号的分布与原始信号的分布在统计上不可区分——这个“分布层面的约束”就是感知保真的数学表达。它揭示了率、失真、感知三者之间的三方权衡:追求更高的感知质量,可能需要额外付出码率,或容忍更大的传统失真。
2.3 第三层:语义保真——意思对
感知保真已经往前走了一大步。但它仍然不够。
想象一张路牌的图片。经过有损压缩后,背景比原来更干净了,路牌边缘更锐利了——在像素层,MSE 可能很小;在感知层,它看起来很自然。但路牌上的文字被算法错误地“编造”成了另一个地名——从“中山路”变成了“中山东路”。