LLM推理机制被发现了?AI TIME论道
不再迷信 Benchmark 分数。研究发现:真正会推理的大模型,内部并非“乱想”,而是自发坍缩到一个极低维、高信息密度的“受约束空间”。一种全新的、基于内部动力学的“推理健康度”诊断法诞生。
过去三年,AI行业一直在疯狂追逐一个问题: 为什么大模型突然学会了推理?从 GPT-4 到DeepSeek-R1,从思维链(CoT)到测试时缩放(Test-Time Scaling),我们讨论了太多关于“结果”的问题:
推理能力从哪里来?
为什么模型规模一大就突然“开窍”?
RL(强化学习)是如何强化 Reasoning 的?
但一个更本质的问题,长期被忽视: 推理在模型内部,到底长什么样?
最近,一篇来自中国人民大学、清华大学、小米汽车 EV、厦门大学的重磅论文,尝试第一次从“内部动力学”的角度回答这个问题。
这篇论文最核心的观点可以浓缩为一句话: 大模型的推理,并不是高维空间中的自由搜索,而是一种在高表达能力基础上,自发形成的低维、信息非退化的受约束动力学过程。
通俗点就是: 真正聪明的大模型,内部并不是在“漫无目的地乱想”。它们会自发收缩到一个极小的低维结构中,同时保持极高的信息密度,并依赖强大的世界知识作为支撑。
这种结构,被称为“推理流形(Reasoning Manifold)”。
我们一直在“误解”推理?
过去几年,评价 LLM 推理能力的方法非常粗暴:看 Benchmark。
GSM8K、MATH、GPQA、AIME、LiveBench……本质上都是在看最终答案。但作者指出,这里有一个巨大的盲区: Benchmark 只能看到“结果”,却看不到“内部过程”。
这就像看到一个学生做对了一道数学题。你不知道他是:
真的理解了逻辑?
还是背过了答案?
还是运气好蒙对的?
甚至是简单的 Pattern Matching(模式匹配)?
对于 LLM 同样如此。两个模型可能 Benchmark 分数差不多,但内部机制可能天差地别。一个可能是“真推理”,另一个可能只是“会考试”。类比测谎仪,它只关注人类说话时大脑的脑电状态,并不直接判断人类所说的话的真实性,如果把LLM比作人脑,那么是否可以用“类脑电”或者其他探测方式来判断大模型是否真的聪明。
震撼发现:推理是“自发坍缩”
为了揭开黑盒,研究者并没有关注模型最终输出了什么答案,而是盯着模型在生成每一个 token 时,内部隐藏状态(Hidden States)轨迹是如何演变的。
通过对 Qwen2.5/3、Gemma 3、DeepSeek-R1 等多个主流模型家族的深入分析,团队观察到一个惊人且一致的现象:
理论上,LLM 的隐藏状态维度极高(2048、4096 甚至更高)。如果推理是一种复杂的“搜索”,那么这些状态轨迹应该在高维空间中四处扩散、自由探索。
但实验结果完全相反。
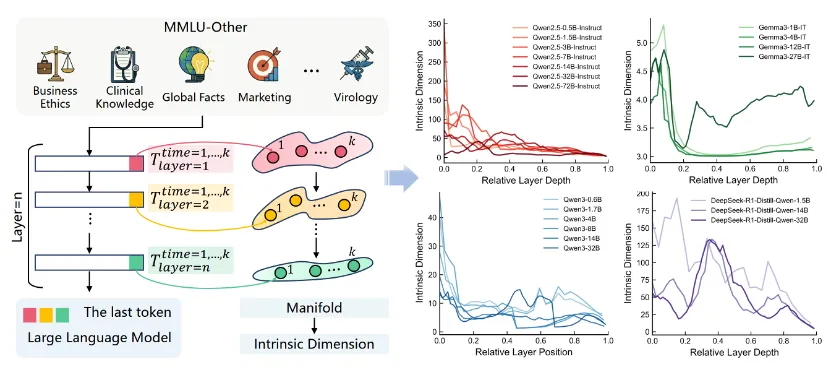
研究者记录了模型生成每一个 Token 时,每一层最后一个 Token 的隐藏状态。他们发现: 几乎所有大模型,在推理过程中,内部状态都会自发地“坍缩”到极低维的空间(图1)。
图 1 展示不同模型层间内在维度ID的快速下降
注意关键词:自发(Spontaneous)。 这不是架构强行限制的 Bottleneck,也不是 PCA 降维,而是模型在推理时,自己把自由度收缩了。
随着层数加深:内在维度(Intrinsic Dimension, ID)快速下降。
最终稳定区域:很多模型最后甚至稳定在低于 10 维的区域。
这意味着,一个拥有几千维表示空间的大模型,在真正推理时,实际上只在一个极小的低维流形中运动。
更有趣的是:越强的模型(如 Qwen3、DeepSeek-R1、Gemma3),收缩越快,轨迹越稳定,流形越清晰。
这像极了高手解题:真正厉害的人,不是尝试更多可能,而是一开始就知道哪些方向是错的,迅速排除干扰,进入正确的逻辑子空间。
除此之外,作者还发现了以下现象:
普适性: 无论提示词如何变化,无论模型规模大小,这种低维结构普遍存在(图2C)。
特异性: 静态的词向量嵌入仍然保持高维(保留了对世界知识的丰富表达),但一旦进入推理动态,维度急剧压缩(图2B)。
这意味着,推理本质上是一个在高维 expressive 空间中,沿着低维紧凑流形进行的动力学过程。
图 2 无论提示词如何变化,无论模型规模大小,这种低维结构普遍存在。以及静态词嵌入的高维与推理轨迹的低维对比
只有“低维”还不够,还要保持信息不损失
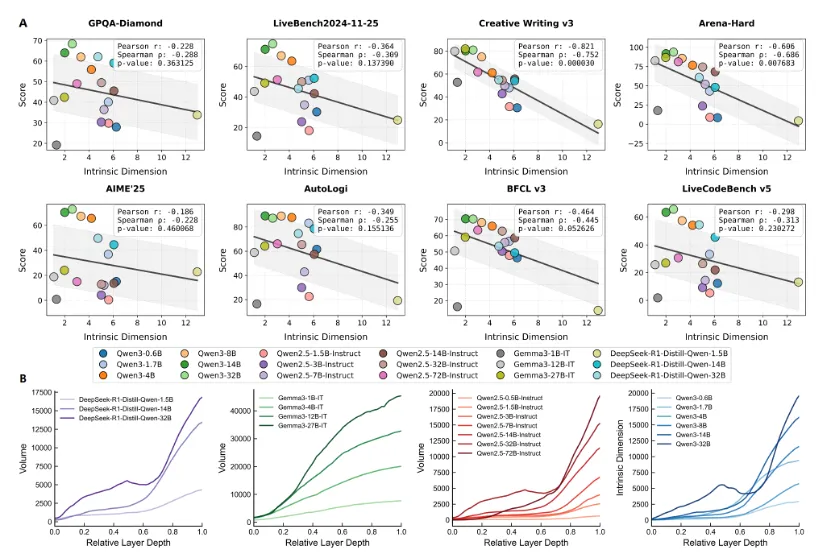
既然推理发生在低维流形上,是否意味着维度越低,推理能力越强?
答案是否定的,因为有些模型虽然很低维,却并不聪明(图3A)。
作者发现,部分模型虽然轨迹收缩得很厉害,但信息也一起塌掉了。它们进入了一种“刚性推理”或“退化坍缩”的状态,即轨迹很稳定,但没有真正的信息流动,像一条“死掉的轨迹”。
图 3 A:本征维度低,不总是表现好。B:推理流形信息量随着层数加深而快速增加。
因此,论文提出了第二个关键原则:非退化信息保持(Non-degenerate Information Preservation)。
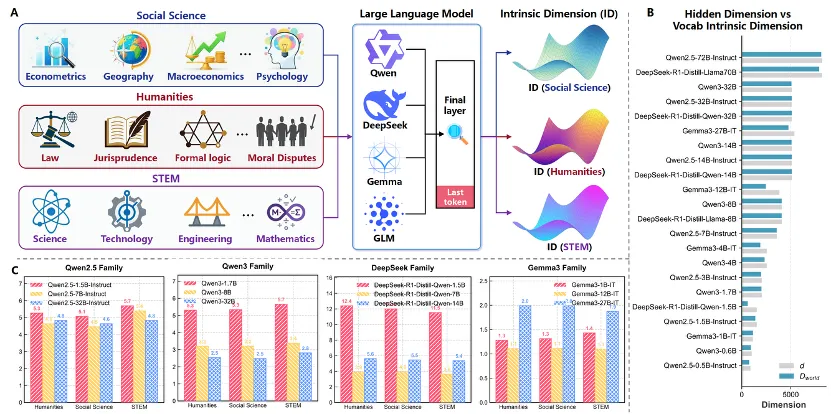
作者定义了信息体积(Information Volume, V),用于衡量推理流形内部保留了多少有效结构。
结果令人惊讶:
随着网络加深,内在维度(ID)在下降(去噪)。
但信息体积(V)却在上升(保留有效结构,图3B)。
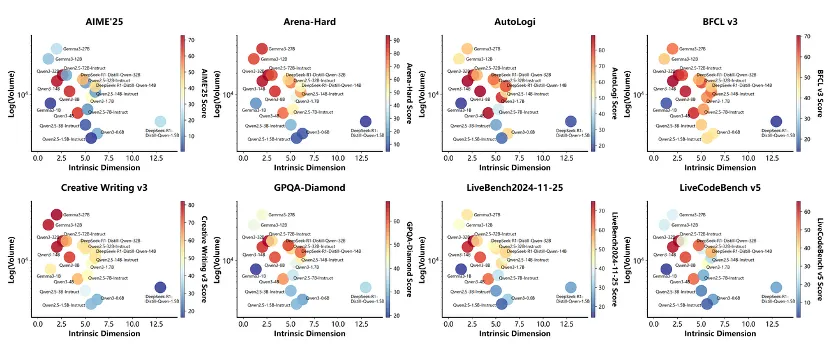
这非常反直觉,因为维度的降低往往带来巨大的信息损失。这说明,真正的 Reasoning 不是简单降维,而是在受约束的流形中,保持高密度的信息组织。模型在压缩噪声的同时,放大了与任务相关的概念变化。图 4 清晰地展示了这一点:高性能模型并非分布在单一轴线上,而是密集聚集在一个“低维度 + 高信息量”的狭窄区域内。偏离这个区域的模型,要么过于松散(Diffuse),要么过于退化(Degenerate),表现均不佳。
图 4 三维空间展示模型分布,高性能模型集中在低维、高信息量的区域
第三个支柱:世界表达能力
即使低维结构存在、信息量足够,模型仍可能不稳定。为什么?
因为世界表达空间(World Expressivity)不够大。
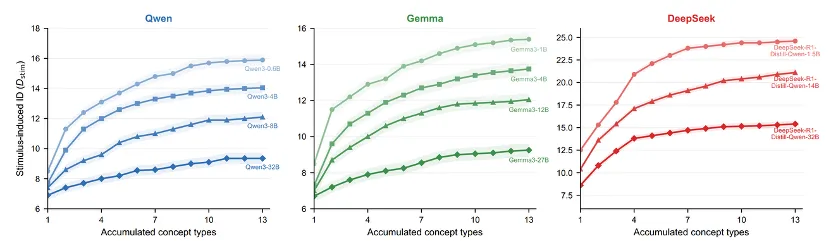
作者测量了模型静态词汇嵌入(Vocabulary Embedding)的内在维度,定义为 D world。它代表模型对“世界概念”的基础表达能力,决定了模型在面对多样化概念时,是否有足够的“空间”来承载信息。表达能力强的模型,在面对复杂刺激时,推理流形更稳定(图5)。
图 5 逐渐增加刺激的多样性,推理流形的本征维度变化曲线。