香农悬案:为什么信息论看不见结构?Voke Flow涌现
5/17/2026
一张社交网络有多少信息?
这个问题听起来应该有一个干净利落的数学回答——毕竟香农在1948年就告诉我们怎么度量信息了。但如果你真的试着用香农的方法去算,你会撞上一堵墙:要度量结构中的信息,你必须先摧毁结构。
把图拆成一组概率,算熵。数字出来了,但两张结构完全不同的图可以给出同一个数字。结构信息在"拆"的那一步就丢了。
这个矛盾不是小问题。早在1953年,Shannon本人就提出了建立结构信息理论的构想,但没有给出方案。半个世纪后,计算机科学家 Brooks Jr. 把结构信息的量化列为计算机科学三大挑战之首,原话是:"我认为这个缺失的度量是信息科学理论理解中最根本的缺口。"
然后这个缺口开了60年。
从1955年到2016年,至少七种不同的方法试图解决这个问题。它们全部失败了——而且失败的原因完全相同。
2016年,李昂生在 IEEE Transactions on Information Theory 上发表了一篇38页的论文,提出了一个全新的方案。这个系列要做的事情,是沿着这篇论文的数学脉络,搞清楚一个问题:他们到底做对了什么,让60年没人解决的问题被解决了?
一、1948年:信息有了数学定义
二、一个数字看不见结构
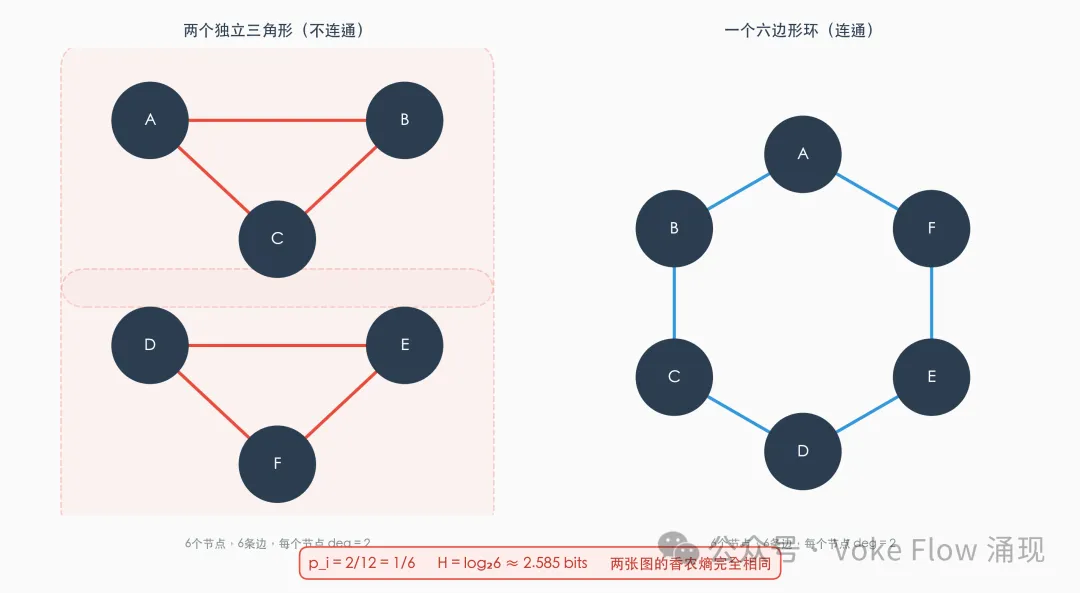
两张结构完全不同的图,香农熵却完全相同
左边是两个独立的三角形——图甚至不连通,一眼就能看出"两个分离的社区"。右边是一个六边形环——所有节点均匀相连,没有任何社区结构。
三、60年间的所有尝试
接下来60年,一代又一代研究者试图修补这个缺口。
第一次尝试:换一种方式拆图(1955–2008)
按距离拆。 Bonchev 和 Trinajstić(1977)换了个角度:用节点之间的最短路距离来定义局部分布:
第二次尝试:不看单张图,看一整类图