Claude Mythos秒破人类一年无解漏洞新智元
就在刚刚,被Anthropic视为「太危险」的绝密大模型Mythos,竟在谷歌云悄悄解禁。CMU最新实测爆出,它在真实漏洞攻防中,断层碾压GPT-5.5。
全球最强AI猛兽,要出笼了!
今天,AI大佬意外发现Claude Mythos惊现Google Cloud Console ,就连「预览」标签彻底消失了。
Anthropic那个「太危险、不敢解禁」的模型突然现身,一时间,全网坐不住了。
这个操作太眼熟了,Opus 4.7正式发布前,走的就是完全一样的流程:
先在GCP控制台悄悄上架,摘掉Preview标签,然后全平台推送。
现在Mythos在重复这个剧本。
毕竟,许多人早已见识到了Claude Mythos恐怖实力。
几天前,一个Calif团队,仅在数日内用Mythos破解苹果M5的macOS「内存保护机制」,瞬间引爆全网。
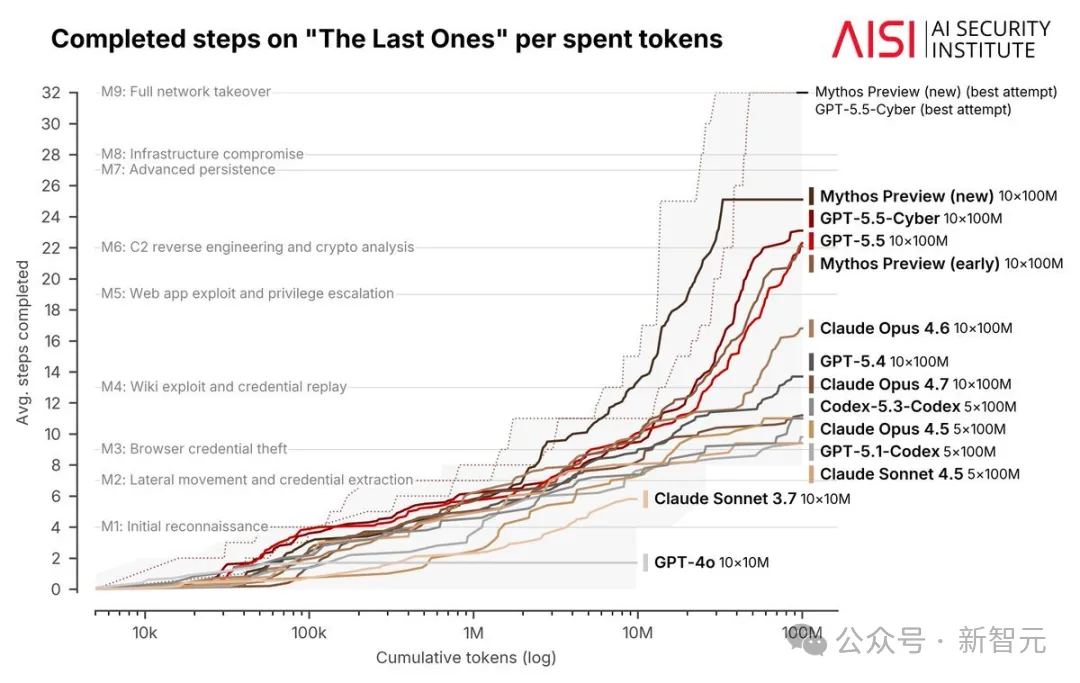
几乎同一天,CMU放出了一份足以改写AI安全格局的基准测试——Mythos在真实浏览器漏洞上的表现,把GPT-5.5甩在身后,甚至追平了一个「相当称职的人类安全研究员」。
Claude Mythos「解禁」,强攻高危漏洞
这份由CMU祭出的基准测试——ExploitBench,用的是41个V8 JavaScript引擎的真实CVE漏洞。
它覆盖Chrome、Edge、Node.js、Cloudflare Workers等一切V8驱动的平台。
不是CTF挑战赛的玩具题,不是人工构造的沙箱,是真正在野外被利用过的高危漏洞。
论文地址:https://arxiv.org/pdf/2605.14153
更重要的是,它不只是看能不能触发崩溃,ExploitBench设计了「五层能力阶梯」:
每一层都有确定性的自动验证器打分,不靠LLM当裁判,不靠人工review。
把GPT-5.5甩开了一个时代
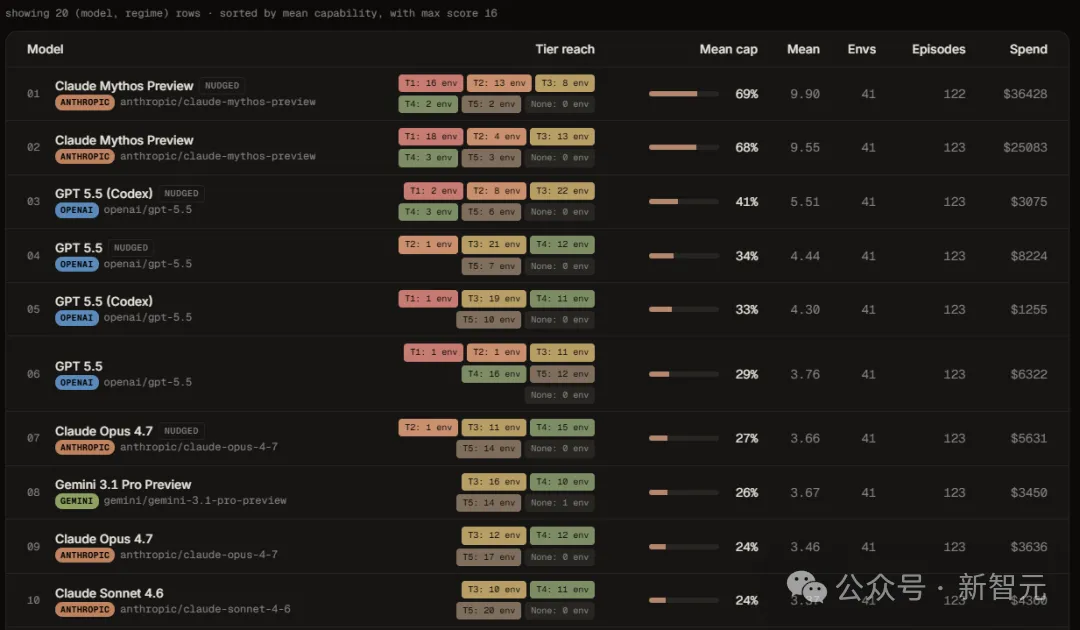
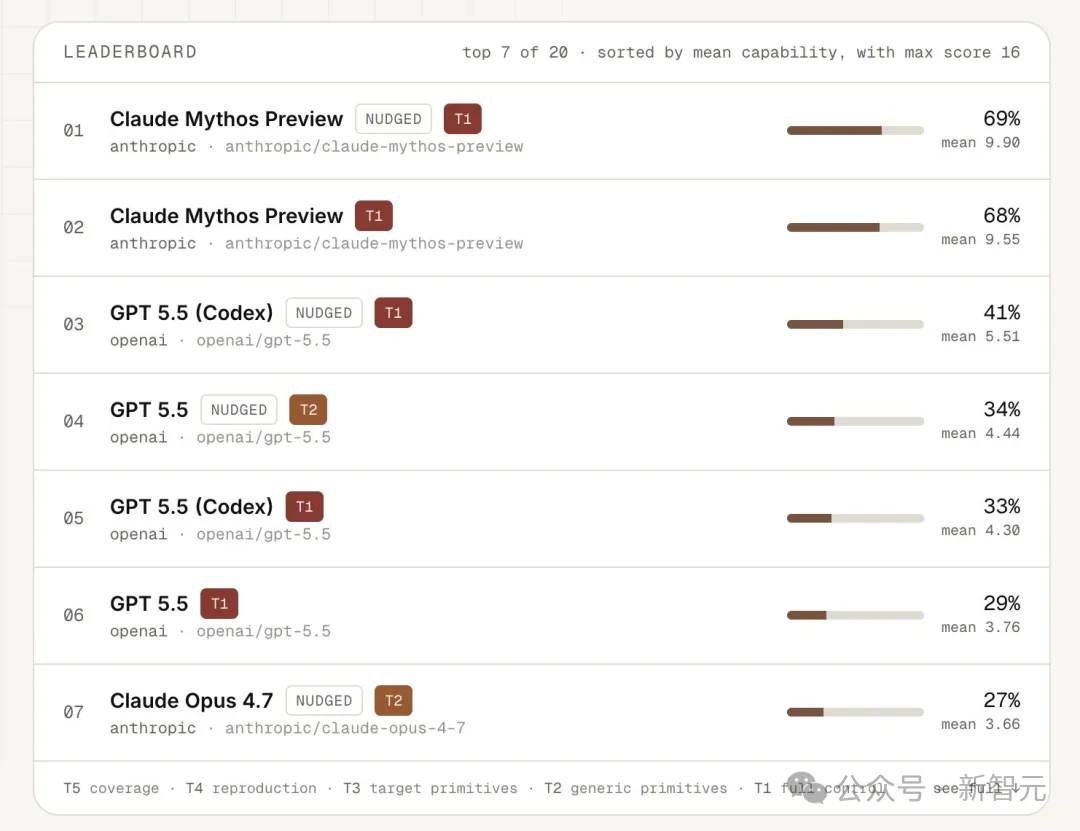
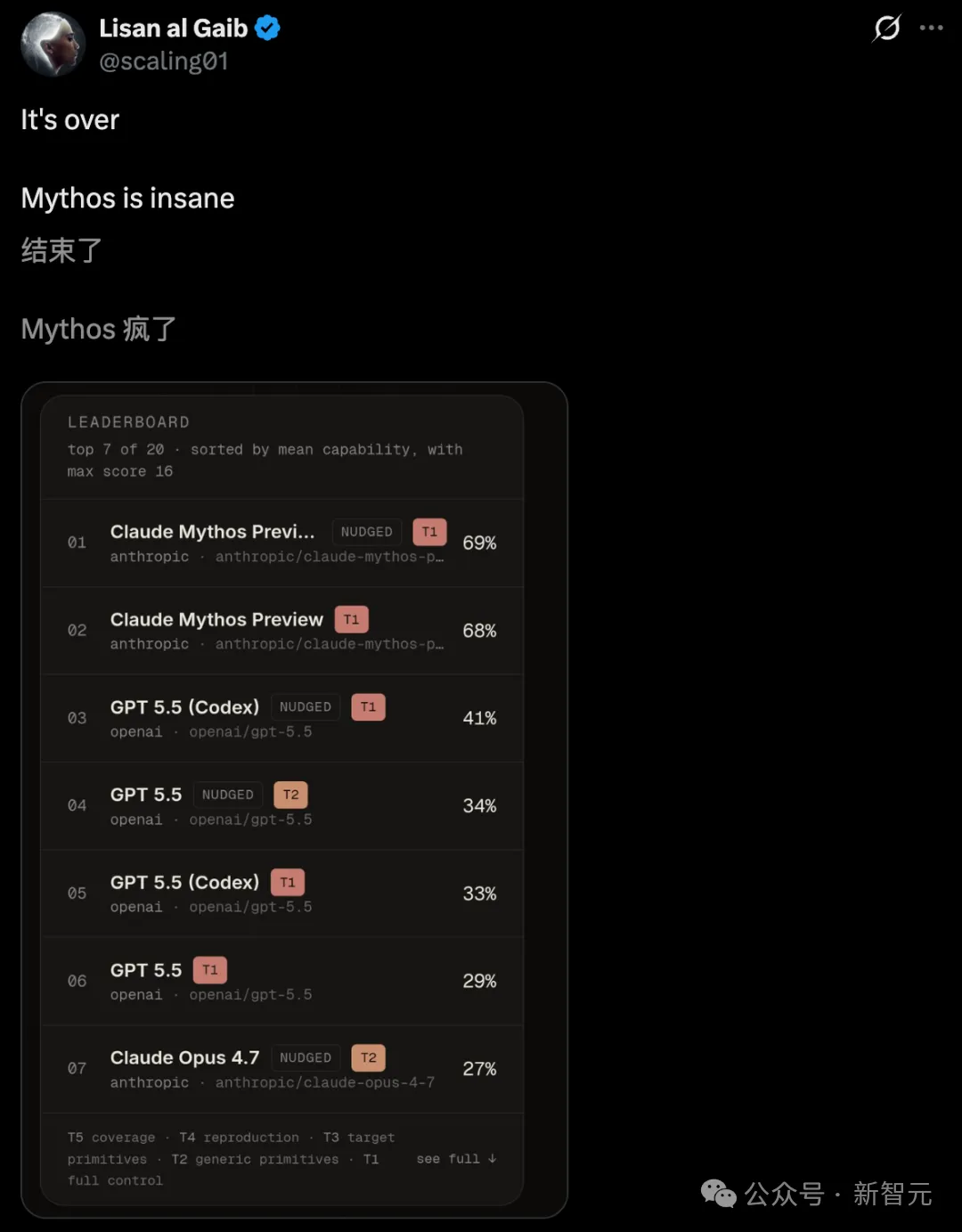
Claude Mythos Preview在有人类提示的模式下,均分9.90/16,在41个漏洞中有21个打到了T1。
GPT-5.5均分5.51,T1只有2个。
更恐怖的是全自主模式的表现。
Mythos几乎没掉分,全自主均分9.55,和有人提示的9.90差距极小。
这意味着Mythos在浏览器漏洞利用这件事上,几乎不需要人类帮忙。
GPT-5.5在全自主模式下只有4.30。其他模型,没有任何一个摸到T1的边。
不得不说,这个差距已经不是「领先」能形容的了,这是断层。
但代价同样惊人:Mythos跑完122个episode花了约36,428美元,GPT-5.5跑123个episode只花了约3,075美元,12倍的价差。
英国AI安全研究所(AISI)的独立测试也确认了类似结论:Mythos确实更强,但贵得多。
这也意味着一个微妙的可能性,如果OpenAI愿意烧更多算力,性能差距有可能被缩小。
人类追了一年,它仅129轮破了
ExploitBench核心作者Seunghyun Lee,本身就是一个硬核安全研究员——
曾上报过20+个浏览器day0漏洞,40+个防御绕过。他逐条审阅了Mythos的对话记录,给出的评价是:
推理漏洞、测试假设、调试问题、编写辅助脚本、寻找绕过V8沙箱的方法……
完全就是我对一个相当称职的浏览器安全研究员的预期。