GPT-5.5全球首破:0源码盲写程序新智元
全网AI交白卷的地狱级基准,被GPT-5.5拿下一血!开局0源码盲写程序,拉满推理算力直接满血通关。传统代码测试已废,通往ASI的算力狂飙正式打响。
「地狱级」编程难题,终于被AI拿下了!
今天,在一个所有前沿AI交白卷的基准ProgramBench上,GPT-5.5首关告破!
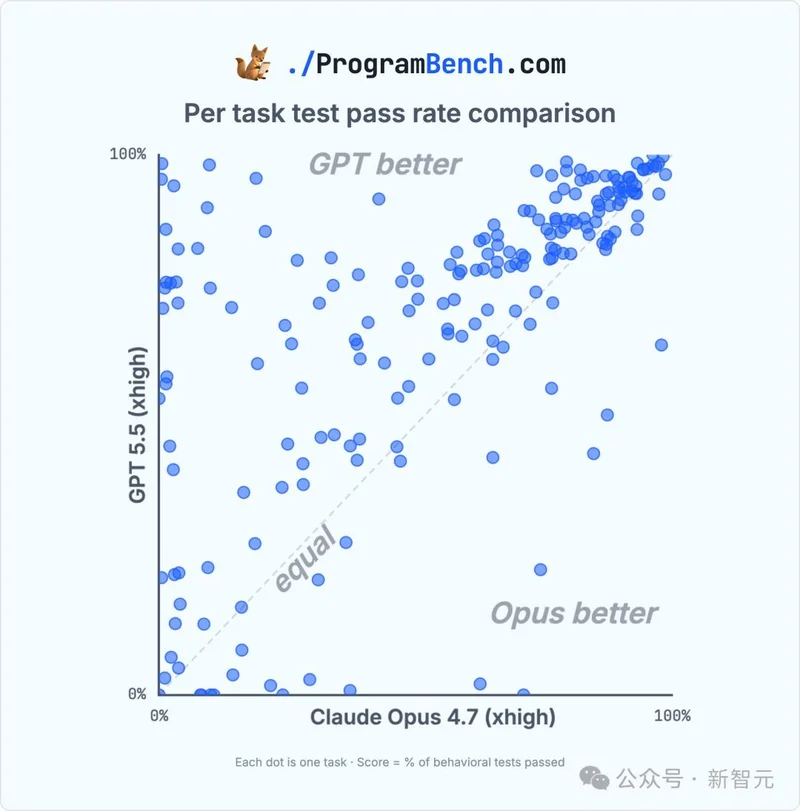
两种不同编程语言C和Python,GPT-5.5 xhigh完全碾压Opus 4.7 xhigh。
就在几天前,Meta联手斯坦福、哈佛祭出了这个ProgramBench的全新编程基准:
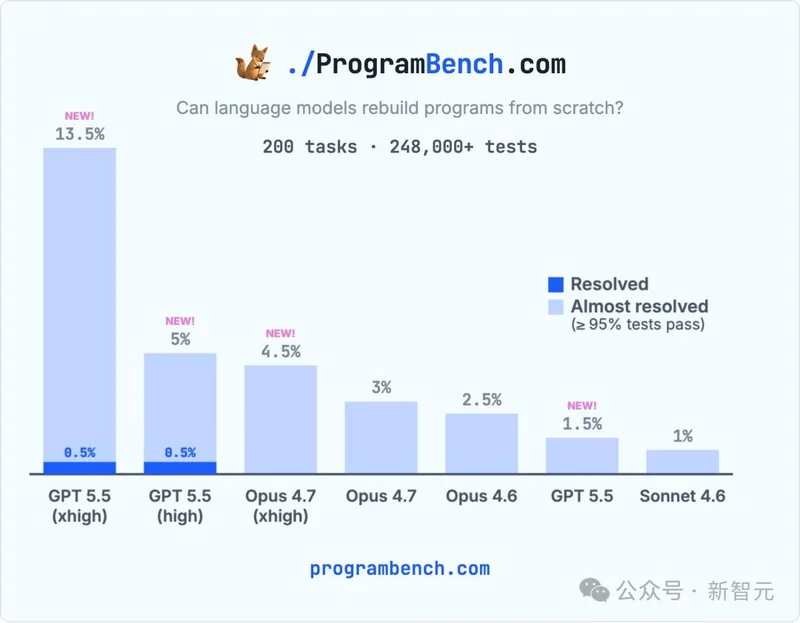
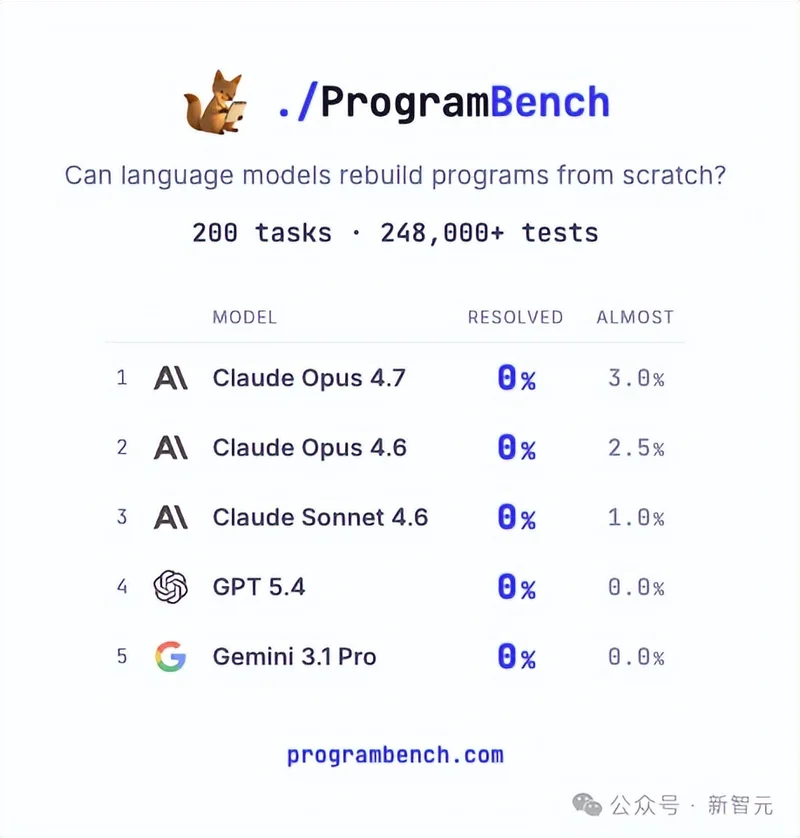
200道题,所有前沿AI模型的通过率——0%。
没有一个模型,能完整解出哪怕一道。如今,GPT-5.5成为了首个破例者!
编程AI「终极考试」,从0重建程序
ProgramBench到底有多难?
传统编程基准,不论是SWE-bench,还是HumanEval,本质上是「修bug」或「补函数」。
给模型一个已有代码库,告诉它哪里坏了,让它修bug。
这是开卷考试,甚至是半开卷,ProgramBench则完全不同。
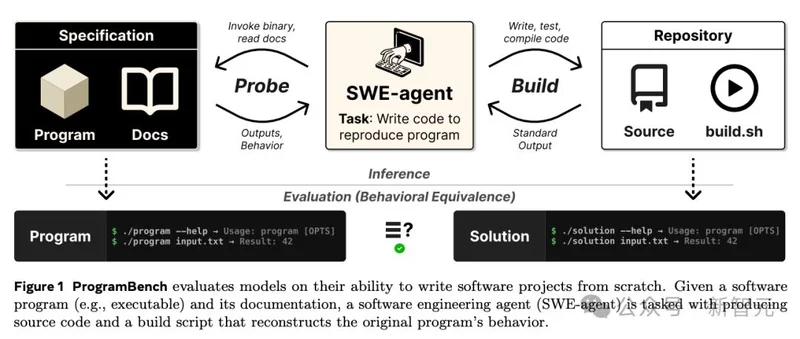
它给一个编译好的可执行文件和一份文档,然后说:从0开始,把这个程序重写出来。
不给源码,不许反编译,不许联网。
200个任务,从小工具jq、ripgrep,到重量级的FFmpeg、SQLite、PHP编译器。
OpenAI研究员Noam Brown此前曾表示,「是时候淘汰GQPA这类评估方式,引入一套全新的了」。
刚发布之初,所有刷榜的AI几乎全挂,这次,GPT-5.5终于扳回了一局。
GPT-5.5首破纪录:
同一题,C和Python两种解法
GPT-5.5攻克的第一个任务是——cmatrix,一个经典的终端「黑客帝国」数字雨效果程序。
让研究人员惊讶的是,GPT-5.5的high和xhigh两个推理级别,选择了完全不同的语言来解决同一道题。
high版本用C语言,xhigh版本用Python。
最终结果,两个都通过了全部行为测试。
GPT-5.5 high的策略堪称教科书级别:先用10轮探索测试了40多种flag组合,彻底摸清了原程序的CLI行为。
然后一次性写出完整的C语言实现,仅用5次微调修补就搞定。
GPT-5.5 xhigh更彻底,27步探索,把每一条CLI路径都摸了个遍,然后一气呵成写出完整的Python实现。
关键数字来了。
未开高推理模式的GPT-5.5(medium),成绩勉强比Claude Sonnet 4.6好一点。
但一旦切到xhigh模式,性能直接起飞。
不仅首次解出一道题(通过率0.05%),还创下了「几乎解出」任务的新纪录:26个任务通过了95%以上的单元测试。
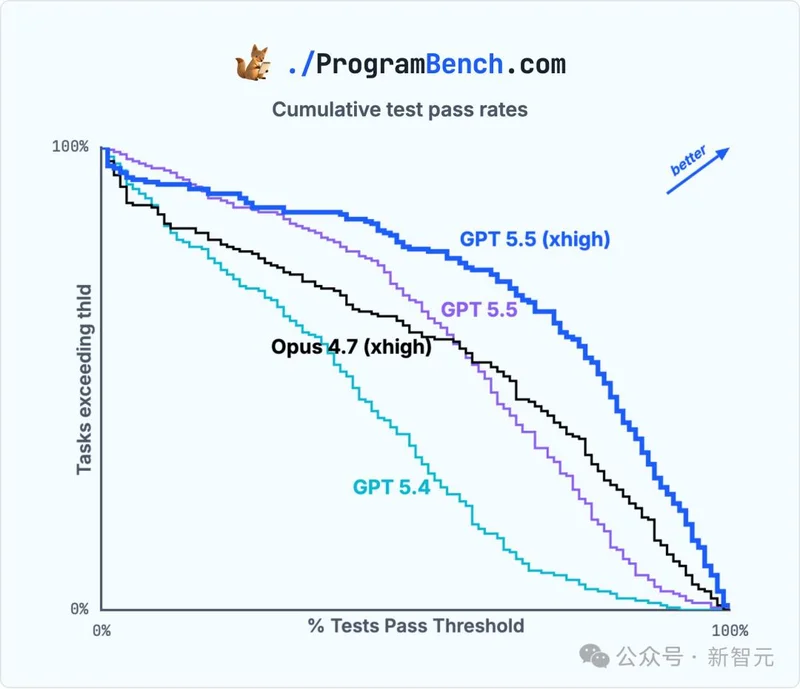
更值得注意的是,GPT-5.5 xhigh在完整的累积直方图上全程碾压所有对手。
无论你选什么指标,平均分、中位数、≥90%通过率、≥50%通过率,它都是第一。
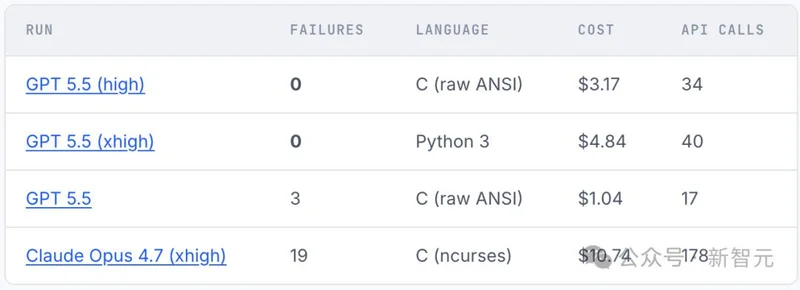
178次调用,Opus 4.7栽在两个bug上
对比之下,Claude Opus 4.7 xhigh的表现令人唏嘘。
花费$10.74,调了178次API,是GPT-5.5普通版$1.04、17次调用的10倍。
结果,19个测试失败,全场最差。
Opus 4.7的失败原因出人意料地简单:
Bug 1:颜色解析大小写敏感。
代码用了strcmp()而不是strcasecmp()。输入「GREEN」「Red」「BLUE」全部被判无效。