何恺明首个语言模型:105M参数,不走老路量子位
何恺明,也下场做语言模型了。
只不过,这次他带队做的不是大家熟悉的、像 ChatGPT 背后那套 “预测下一个词元”(next token prediction)的自回归范式。
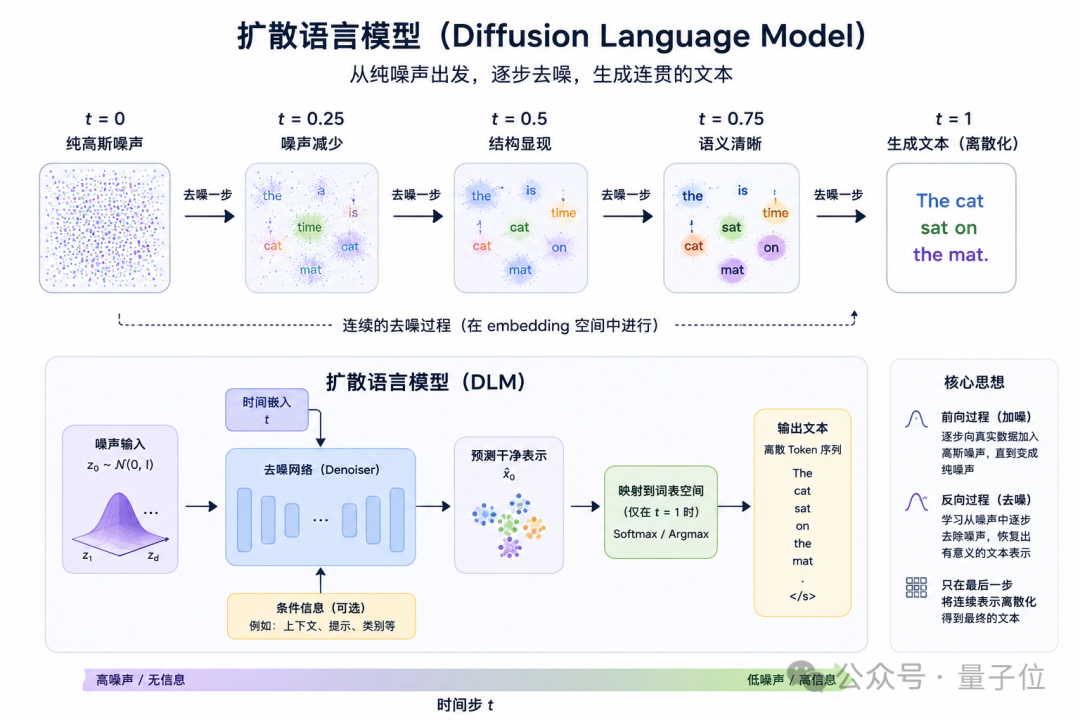
而是另一条过去几年在图像领域大火、如今正被越来越多人搬进文本生成的新路线:扩散语言模型(Diffusion Language Model,DLM)。
在最新的论文中,何恺明团队放出全新连续扩散语言模型:ELF:Embedded Language Flows。
与不少还停留在 token 层面做扩散的语言模型不同,ELF 把整个生成过程都留在了连续的 embedding 空间里,直到最后一步,才重新离散化,将表示变回 token。
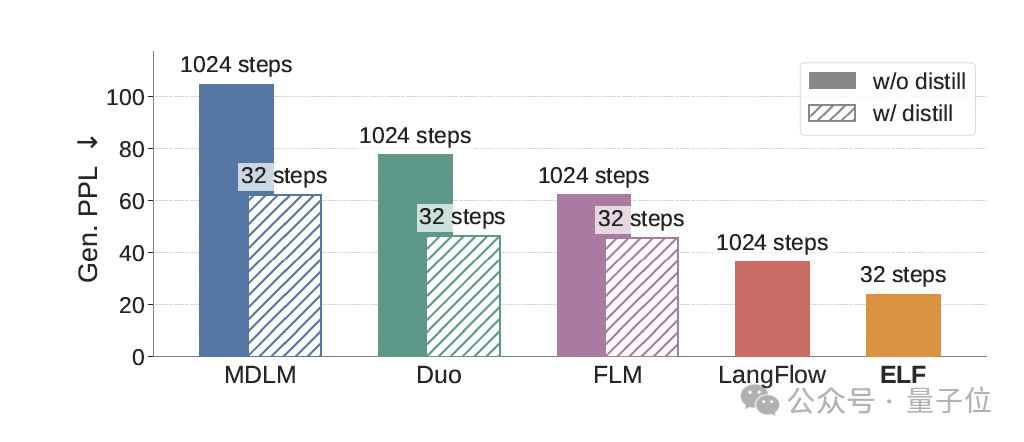
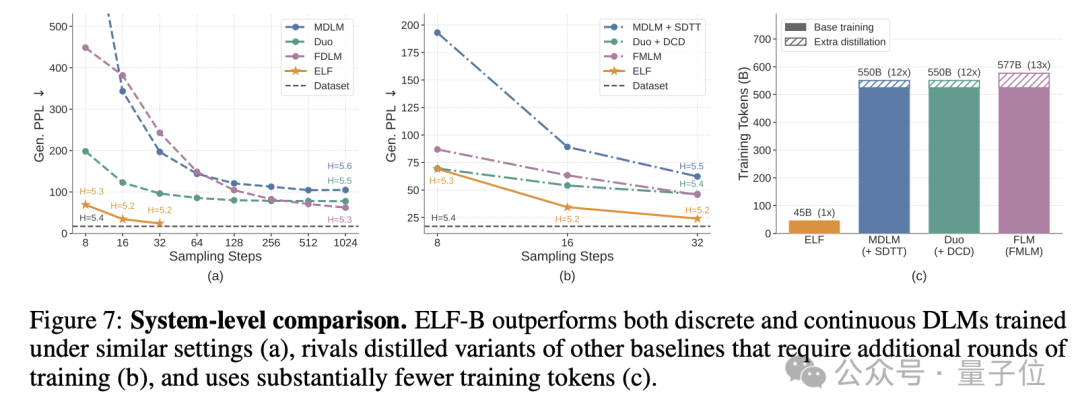
靠着这套设计,ELF 只用了 105M 参数、45B 训练 token、32 步采样,就正面跑赢了一批主流扩散语言模型。
最直观的一项指标是它在 OpenWebText 上,把生成困惑度(Generative Perplexity)直接压到了 24。
这里简单科普一下生成困惑度,它本质上是让一个强大的语言模型,给生成结果 “检查作业”,看看这些文本到底像不像真实人类写出来的语料 —— 值越低,说明生成质量越高、模型出来的东西也就越没 AI 味儿,越自然。
在和主流扩散语言模型的对比中,ELF 在训练 token 少近 10 倍、采样步数更少的情况下,反而拿到了更低的生成困惑度。
可以说,在过去很长一段时间里,扩散语言模型的进展,几乎都发生在离散 DLM(Discrete DLM)这一侧。
而 ELF 第一次证明了一件事:连续的方法,不但能跑,而且效果不错。
ELF 到底做了什么
要理解 ELF,先得理解扩散语言模型现在到底在做什么。
扩散语言模型,主要有两种技术路线。一是以 MDLM、Duo 为代表的离散派,直接在 token 空间做扩散,每一步处理的是离散随机变量。
二是包括 Diffusion-LM、CDCD、DiffuSeq 在内的连续派,把 token 映成连续 embedding,在连续空间里去噪。
此前的研究中,像 MDLM、LLaDA、Dream 7B 这些离散路线占据了上风。原因是很简单,因为语言本身就是离散的。
对于这一看似常识的理解,恺明团队给出的判断恰恰相反 ——
问题可能不是 “语言必须离散”,问题可能是:前人根本没有让连续路线,连续到底。
Diffusion-LM 这一类的方法虽然在 embedding 空间去噪,但每一步都要算一次 token-level 的交叉熵,把连续轨迹一路绑在词表上。
后来的 LD4LG、Cosmos 走 latent diffusion 路线,去噪过程是连续了,但要单独训一个 decoder 把 latent 解回 token,相当于多一个模块。
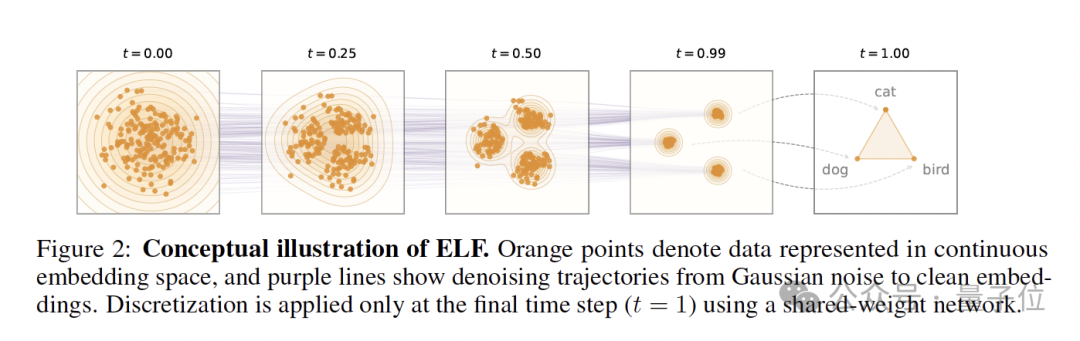
基于此,ELF 把所有 denoising,全留在 continuous embedding space;直到最后一步 t=1,才重新投回 token。
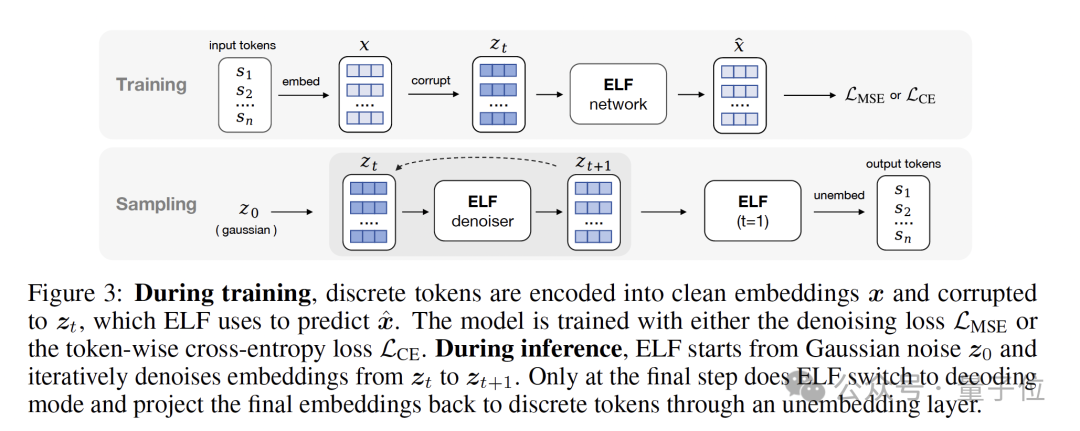
具体来说,ELF 在训练时,离散 token 先被编码成连续 embedding,再加噪成 z_t,模型要么负责把它还原成干净 embedding(MSE),要么直接预测 token(CE)。
推理时,模型从高斯噪声 z_0 出发,一路在连续空间里去噪,直到最后一步,才切到 decode 模式,把 embedding 重新投回 token。
ELF 第一次把 “连续表示” 和 “离散输出” 这两个过去总被认为必须反复对齐的问题,彻底拆开了:
中间的去噪,完全交给连续空间;最终的语言生成,只留到最后一步离散化。
没有每一步都往词表上硬对齐,也不需要额外训练一个 decoder,整个生成流程第一次真正做到了:连续就是连续,离散就是离散。
而这,恰恰也是 ELF 后面能用更少采样步数、更少训练 token,却跑赢一众扩散语言模型的关键。
ELF 不是 “先扩散,再解码”。
在具体的实现上,ELF 还解决了三个问题:token 怎么变连续?连续里怎么去噪?最后又怎么变回 token?
把 token 变成连续 embedding
要把连续扩散用在语言上,第一步,得先把离散的 token 变成连续表示。
论文中,ELF 先把它切成 token 序列,再映射到连续 embedding 空间。这里具体怎么映射,其实有多种选择。
默认情况下,ELF 用的是 T5 预训练 encoder,生成双向的 contextual embedding。论文后面也测试了 jointly trained embedding 和随机 embedding 等不同方案。
值得注意的是,这个 encoder 只在训练阶段使用,推理时并不会额外增加模块。
在连续 embedding 空间里做 Flow Matching
拿到连续表示之后,ELF 就在 embedding 空间里做 Flow Matching。
简单说,Flow Matching 定义了一条从噪声到真实数据的连续流动轨迹:
t=0 时,是高斯噪声;
t=1 时,是干净的 embedding;
中间所有状态,都是两者的线性插值,也就是论文里的 rectified flow。
在传统 Flow Matching,网络通常直接预测 “速度场” v。
但 ELF 没有这么做,而是沿用了恺明团队半年前在《Back to Basics: Let Denoising Generative Models Denoise》里提出的思路 —— 直接预测干净 embedding x,也就是 x-prediction。
训练目标,就是最小化预测 embedding 和真实 embedding 之间的均方误差(MSE)。
至于为什么采用 x-prediction,论文给了两个原因:
第一,它在高维表示上更稳定 —— 比如 768 维甚至更高的 token embedding;第二,它天然和最后一步 “预测干净 token” 的目标对齐。
论文还特别提到:虽然理论上也可以先预测速度 v,再换算成 x,但这样一来,后面 denoising 和 decoding 之间的权重共享就很难成立。
实验上,他们也发现:一旦共享权重,v-prediction 效果明显变差。
从连续 embedding,再回到离散 token
生成语言,最终输出还是离散 token。
所以 ELF 只在最后一个时间步(t = 1),还得把连续 embedding 重新投回 token 空间。
不过,这一步 ELF 没有像很多 latent diffusion 方法那样,额外训练一个 decoder。相反,它把最后一步直接视作:一次 continuous-to-discrete decoding。
换句话说:decoder 和前面的 denoiser,其实是同一个网络。
为了让最后一步训练不至于太简单(因为理论上 t→1 时,输入已经非常接近干净 embedding),ELF 在最后一步额外加入了一次 token-level corruption,构造出一个带扰动的输入。
随后,同一个网络输出 clean embedding,再通过一个可学习的 unembedding 矩阵 W,投影成 token logits。
训练目标,则是标准的 token-level cross-entropy loss。整个网络共享同一套参数,并额外接收一个二值的 mode token:去噪模式 / 解码模式。
推理时,ELF 从高斯噪声开始一路在连续空间里去噪,直到最后一步 t = 1,才切换到 decode 模式,再通过 argmax 输出最终 token。
值得一提的是,在 ELF 中,图像生成里最常用的技术之一,CFG(classifier-free guidance)也被搬过来了。
ELF 用 self-conditioning 作为条件信号,套上 training-time CFG(一次 forward 模拟两次推理,没有 inference 开销),把图像那边的方案直接搬了过来。
实验部分,ELF 基本回答了一个过去两年一直悬着的问题:连续扩散语言模型,到底能不能打?答案是:不但能打,而且第一次在质量、速度、训练成本三个维度同时赢。
如开头所说,在 OpenWebText 生成任务中,在不做蒸馏的情况下,ELF 只用 32 步采样,就把生成困惑度压到了 24。
而此前主流的离散扩散模型,往往要跑到 1024 步,才能接近这个水平。
更夸张的是,ELF 实现这一结果时,训练 token 只用了 45B。