横跨大西洋11小时:用Mac跑Llama 70 B新智元
一位中国开发者,在横跨大西洋的航程中,在飞机上用 MacBook 本地跑 Llama 70B,整整 11 小时没有网络,帖子瞬间在X上爆火!但是随后,越来越多网友发现,这故事不太对啊?
一位中国开发者,在横跨大西洋的 11 小时航程中,拒绝了 25 美元的机上网络,却在万米高空完成了一整套复杂的客户项目交付?
没有 Cloud API,没有 Anthropic,没有 OpenAI,甚至没有一格信号。
只有一台 MacBook Pro M4、一段自己写的编排脚本,以及Llama 70B这个本地AI模型,然后就把项目跑通了?
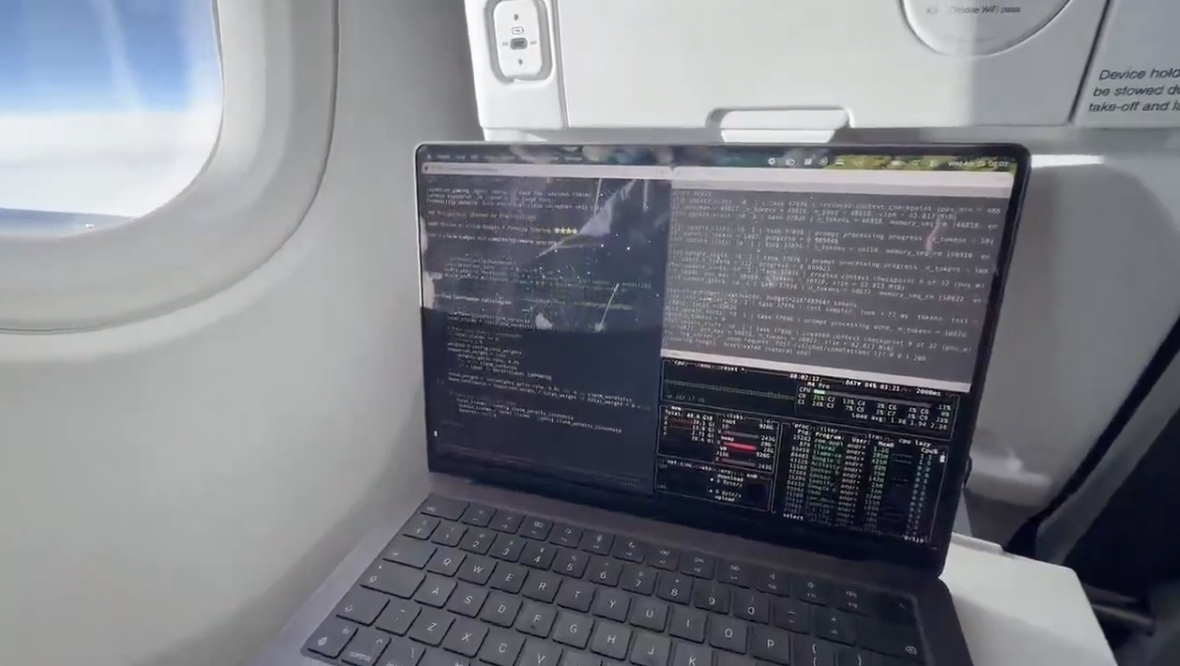
舷窗外是白云与蓝天,没有 WiFi;小桌板上是一台 MacBook,终端开着两个窗口,本地运行着一个推理服务器
因为太过炸裂,这个帖子一经发出,就在技术社区传开了。
本地推理的时代,真的来了?
在万米高空,用MacBook跑Llama 70B
据说,故事的主角是一位中国开发者。
在飞往大洋彼岸的靠窗座位上,他打开64GB内存的MacBook Pro,面对的是堆积如山的客户任务队列。
接下来整整11个小时,都没有网络。
换做普通人,此刻已经乖乖掏出信用卡,支付那昂贵且延迟极高的 25 美元机上 Wi-Fi。
但他选择了另一条路:本地推理。
他启动了通过 llama.cpp 运行的 Llama 3.3 70B。
生成速度 71 tokens/秒,上下文约 60,000 tokens,内存占用 48.6 GiB / 64 GiB,起飞时电池剩余 3 小时 21 分钟。
为了让这个庞然大物在64GB内存的机器上跑起来,他甚至为自己编写了一个「离线编排器」脚本。
最令人拍案叫绝的,是他给AI下达的系统提示词。
你是一个运行在单台 MacBook 上的离线编排器。没有网络。你唯一的资源是 /Users/dev/work 下的本地文件、localhost:8080 的 Llama 70B 推理服务,以及 3 小时 21 分钟的电池预算。
处理 /Users/dev/work/queue.jsonl 中的任务队列(每行一个客户任务)。对每个任务:起草 → 运行本地评估 → 保存产物到 /Users/dev/work/done/。每 12 个任务保存一次上下文检查点,以便更换电池后恢复。仅在队列为空或电池低于 5% 时停止。
因此,这个系统完全清楚自己所处的困境。
它知道自己未来 11 小时与世隔绝,知道内存和电池是有限的奢侈品,甚至知道在飞机降落前,它必须独自处理所有的逻辑。
系统在一个循环中运行:从任务队列中取出一个任务,进行推理处理,保存生成结果,写入检查点。一个接一个,就这样持续执行。
只有当电量低于 5% 时,调度器才会自动暂停,等待笔记本切换到备用移动电源,然后从上一次的检查点继续运行。
飞行过程中,系统日志里写下了这样的内容:
「已保存上下文检查点 8 / 12(pos_min = 488,pos_max = 50118,大小 = 62.813 MiB)」
「已恢复上下文检查点(pos_min = 488,pos_max = 50118)」
「提示处理进度:n_tokens = 50 / 60,818」
「任务 37016 完成 | 处理速度 = 71 tokens/s → 输出至 /Users/dev/work/done/proposal_westside.md」
有人惊呼:这是我过去一年里见过的最干净利落的离线 AI 工作流程!
11 小时航程,WiFi 花费为 0,当飞机轮子触碰跑道的那一刻,他合上电脑,所有的客户提案已经整整齐齐地躺在 done/ 文件夹里。
系统不再是一个只会复读的复读机,而是一个具备资源意识的管理者。
这正是「Self-aware Computing」最迷人的地方。
技术神话,还是「赛博爽文」?
不过,文章在社区疯传后,很快引来了技术极客们的质疑。
资深开发者们纷纷掏出计算器,开始疯狂「对线」。
第一刀:内存与权重的「不可能三角」
Llama 3.3 70B 如果以 BF16(半精度)运行,光模型权重就需要约 140GB 内存。要在 64GB 的 MacBook 上跑起来,简直就像把大象塞进冰箱。
64GB 内存大概率只能跑 4-bit 量化版本,算上 60k 的上下文 KV Cache,内存占用至少也要 40GB+,BF16 绝无可能。
非要说的话,要在64GB上跑70B,只有一条路——量化。4-bit量化后模型约35GB,加上KV缓存和系统开销,勉强能塞进去。
但量化版本和BF16是两回事,精度、推理质量都会打折扣。