这套题,GPT-5.5、Opus 4.7加起来没考到「1分」机器之心
在大模型「卷生卷死」的今天,大家似乎已经习惯了模型在各大榜单上刷出逼近满分准确率。然而,在一项名为 ARC-AGI-3 的基准测试中,堪称当下「最红炸子鸡」的两款顶尖模型 ——OpenAI 的 GPT-5.5 和 Anthropic 的 Claude Opus 4.7,却双双「折戟」……
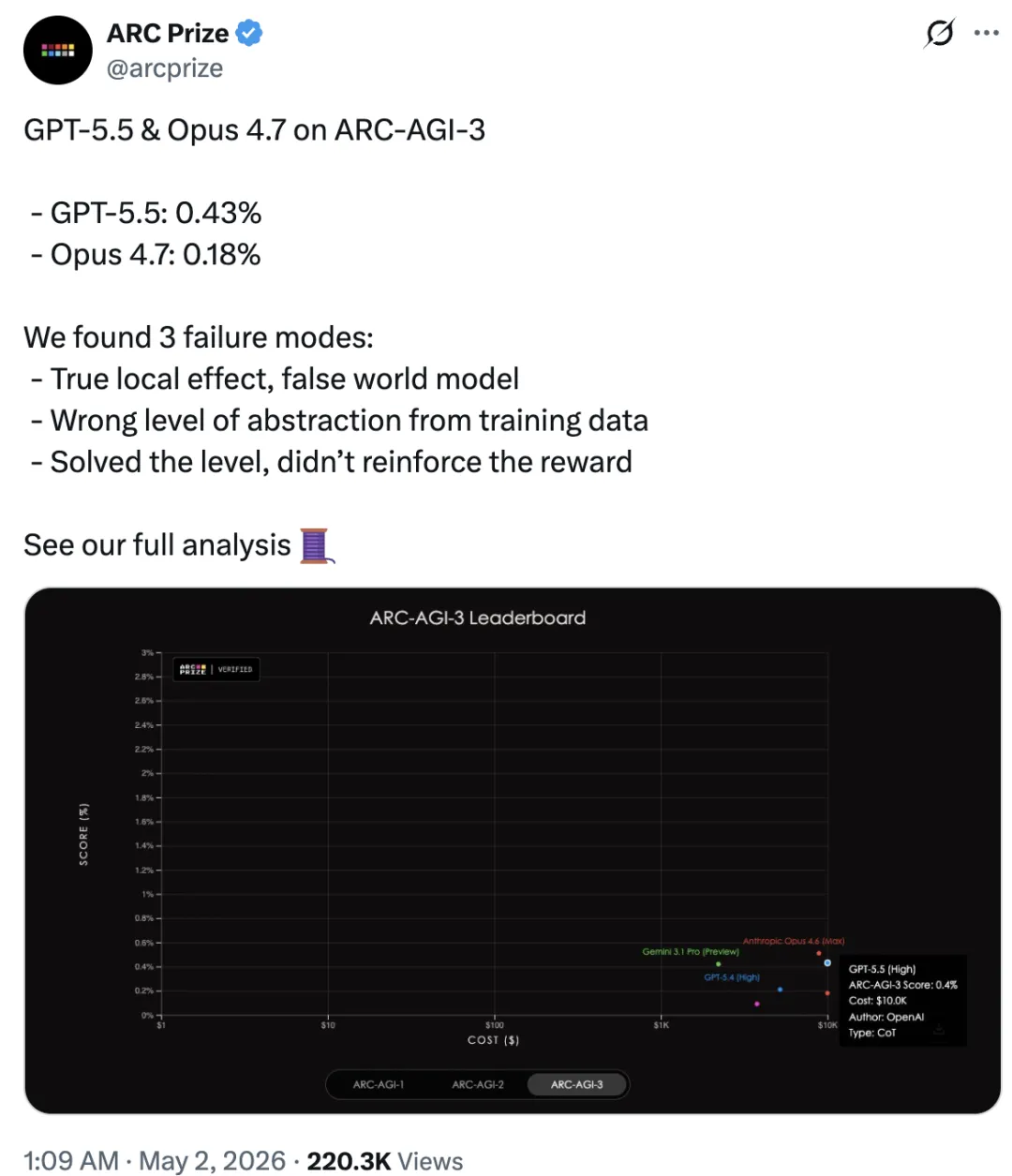
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
这意味着,即便拥有千亿级参数和近乎无限的算力,这些模型在处理「全新逻辑环境」时的表现,甚至不如一个 6 岁的儿童。
这是怎么一回事?
ARC-AGI-3:智能的「真伪试金石」
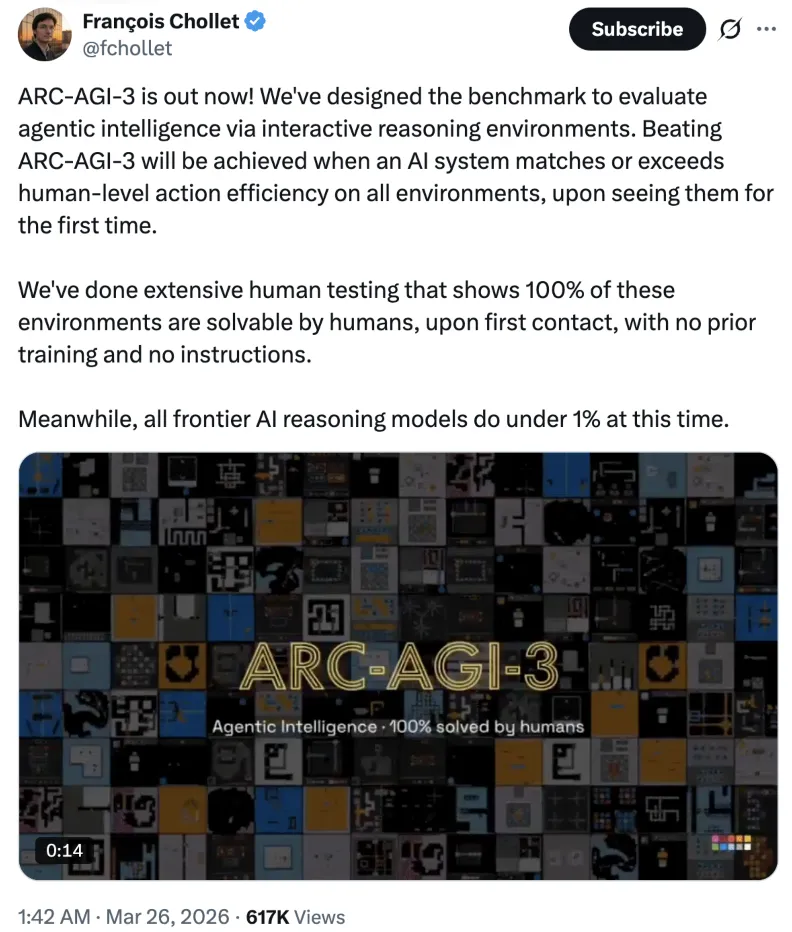
为了更好理解这一成绩,首先我们来了解一下 ARC-AGI-3,这是由 Keras 之父 François Chollet 创立的基准测试系列的最新一代,于今年 3 月分布。
François Chollet 当时称,当一个 AI 系统在首次接触所有环境时,其行动效率能够达到或超过人类水平,才算真正「攻克」ARC-AGI-3。
而根据团队进行的大量的人类测试结果来看:在没有任何先验训练、没有任何说明的情况下,人类在第一次接触时可以 100% 解决这些环境中难题,与此同时,目前所有前沿的 AI 推理模型在这一测试上的表现都低于 1%。
彼时,OpenAI 的 GPT-5.5 和 Anthropic 的 Claude Opus 4.7 还没有发布,如今来看,这两个模型也同样难逃这一结果。
具体来看,ARC-AGI-3 是由 135 个全新环境组成的测试集,每个环境都由人类手工设计,用来测试模型面对「未知」的能力。
对于测试者来说,无论人类还是 AI,进入环境中将不会获得任何的玩法说明,要前进,取得进展,必须做到以下几点:
探索未知界面 ;
从稀疏反馈中推断规则(构建世界模型) ;
提出并验证假设 ;
从错误中恢复 ;
将经验迁移到下一关(持续学习)。
每个环境的构建都缺乏模型通常依赖的文化知识,只保留「抽象推理能力本身」。
换句话说,可以把 ARC-AGI-3 理解为,一个在「新颖性、模糊性、规划、适应性」上的最低共同测试集合,而这些,正是现实世界任务对智能体的核心要求。因此,ARC-AGI-3 也被公认为目前最接近「人类智能本质」的测试。
顶尖模型纷纷「败北」背后的三大失败模式
此次,GPT-5.5 和 Claude Opus 4.7 的表现得分均低于 1% 的成绩固然令人「心痛」,但比起成绩,知道背后的失败原因似乎更重要。
ARC Prize 研究团队通过分析 160 组完整运行轨迹,包括模型的每一步操作和推理过程,总结出了导致模型「崩溃」的三大核心失败模式:
一、真实的局部反馈,虚假的世界模型
模型能够理解哪一步动作产生了变化(局部反馈),但无法将这种因果效应转化为一套通用的全局规则。
这是一个最为明显的原因。比如,在一个需要旋转物体以匹配插槽的任务中,模型能够识别出「我按下这个键,物体可以旋转」这一局部规律,但它无法将此逻辑上升为全局目标,进一步推理出:「旋转会影响结果,因此我需要在行动前调整物体方向以匹配目标。」
换句话说,模型失败不是因为它们「看不见」,而在于无法把观察的事物整合成一个完整的世界模型。
比例,Claude Opus 4.7 在运行任务 「cd82」 时,在第 4 步已经意识到执行 「ACTION3」 可以旋转容器,随后在第 6 步也观察到执行 「ACTION5」 可以倾倒或蘸取油漆。然而,它始终无法将这些碎片化的认知转化为一个完整的逻辑策略,即「先调整桶的方向,然后再蘸取油漆,以还原左上角的目标图像」。
Claude Opus 4.7 理解 ACTION3 旋转物体,但未能理解游戏的概念。
或者在任务 「cn04」 中,Claude Opus 4.7 虽然发现了一个成功的「旋转后放置」交互逻辑(这是正确的假设,见第 23 步),但随后却陷入了追求「整体形状重叠」的误区(错误假设),并为了追求「顶行进度」的假象而偏离了目标(见第 60 步)。
二、被训练数据「绑架」的抽象思维
模型对当前环境产生了误判,由于受到训练数据的影响,它们会将一个全新的「ARC-AGI-3」任务误认为是在玩另一种已知的游戏。
这种失败模式源于模型对训练数据的「错误抽象」,在多次运行中,模型反复尝试通过将其映射到已知游戏来解释陌生的机制,这些游戏包括:「俄罗斯方块」「青蛙过河」「推箱子」「粉末游戏」「填充颜色」「打砖块」等。
虽然从核心先验知识中提取抽象概念在理论上有助于解决问题,但这些来自训练数据的字面类比反而「绑架」了模型的动作选择,从而演变成:局部视觉相似、导致被误认为完整的游戏规则、行动方向被带偏。
比如,在任务 「cd82」 中,GPT-5.5 的思维被锚定在了流沙、物理模拟或 「填充颜色」的游戏机制上;而在任务 「ls20」 中,它将本应是按键组合的逻辑误判为了「打砖块」。