DeepSeek-V4:重新设计记忆AGI Hunt
4/25/2026
DeepSeek V4 发布后,我因为太忙了一直没空详细测试和看技术报告,但毕竟是源神一年半之后再次的重磅更新,今天多少得补上一个:
DeepSeek-V4 性能与效率总览
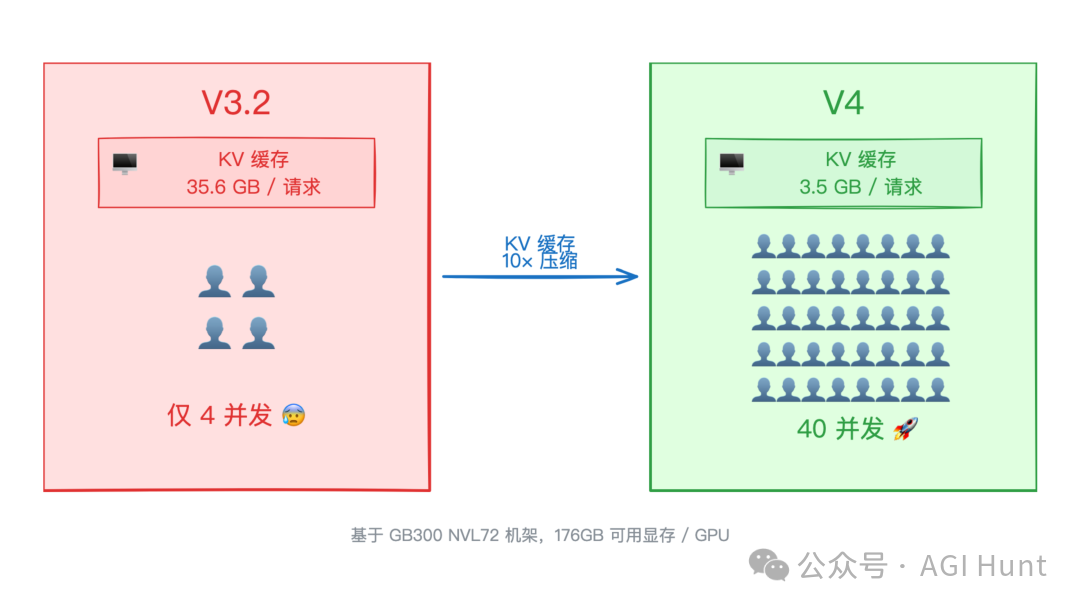
也就是说:同样一块 GPU,V3.2 时代只能同时服务 4 个长上下文用户,而 V4 能服务大约 40 个。
这可以说是 DeepSeek 再一次的非渐进式优化,把长上下文推理的成本进行了改写。
Pro 和 Flash
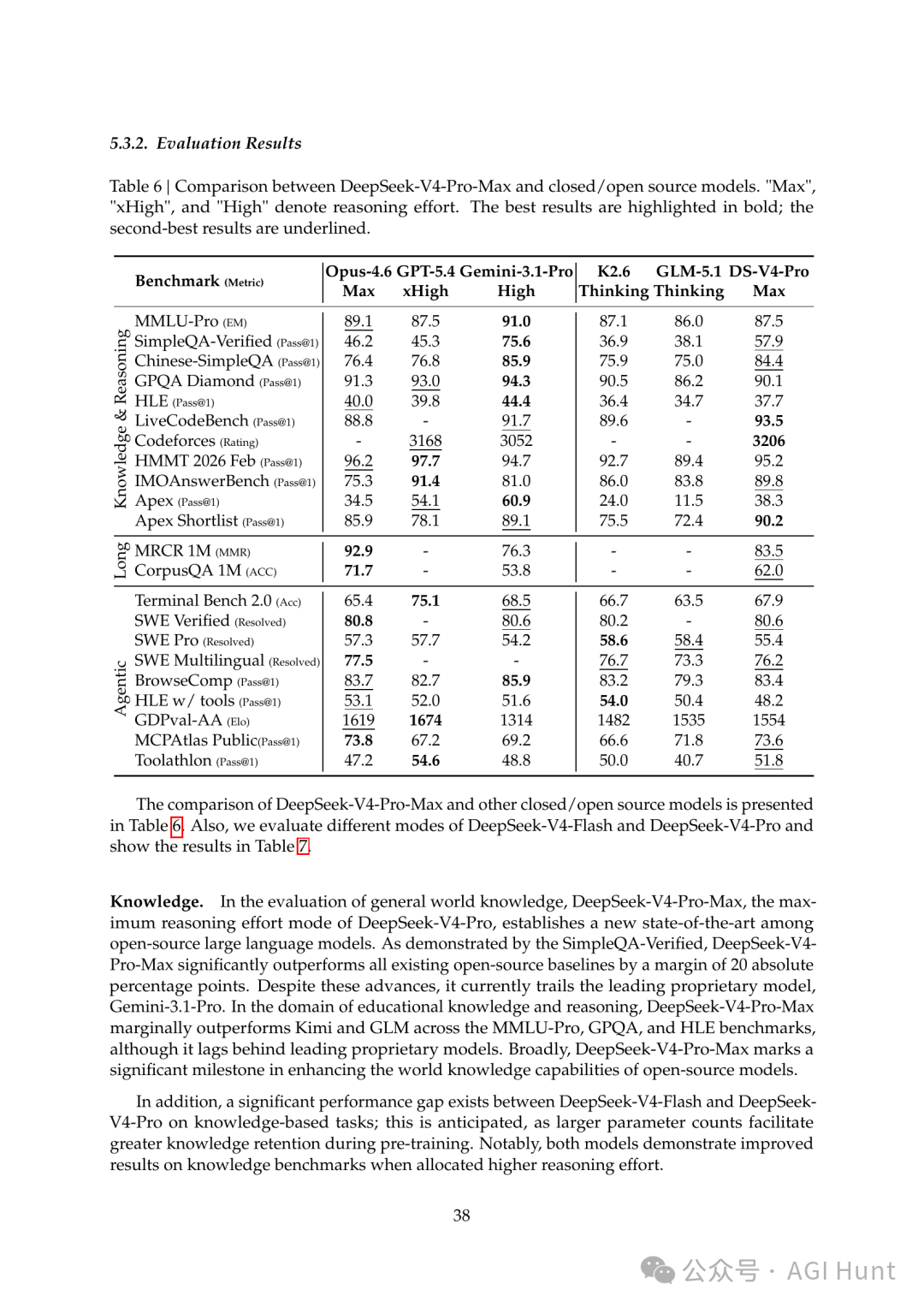
DeepSeek-V4 评测对比
技术报告很谦逊,直说了自身的不足:在推理能力上,V4 的发展轨迹「落后前沿闭源模型大约 3 到 6 个月」。知识评测上,也还追不上 Gemini-3.1-Pro。
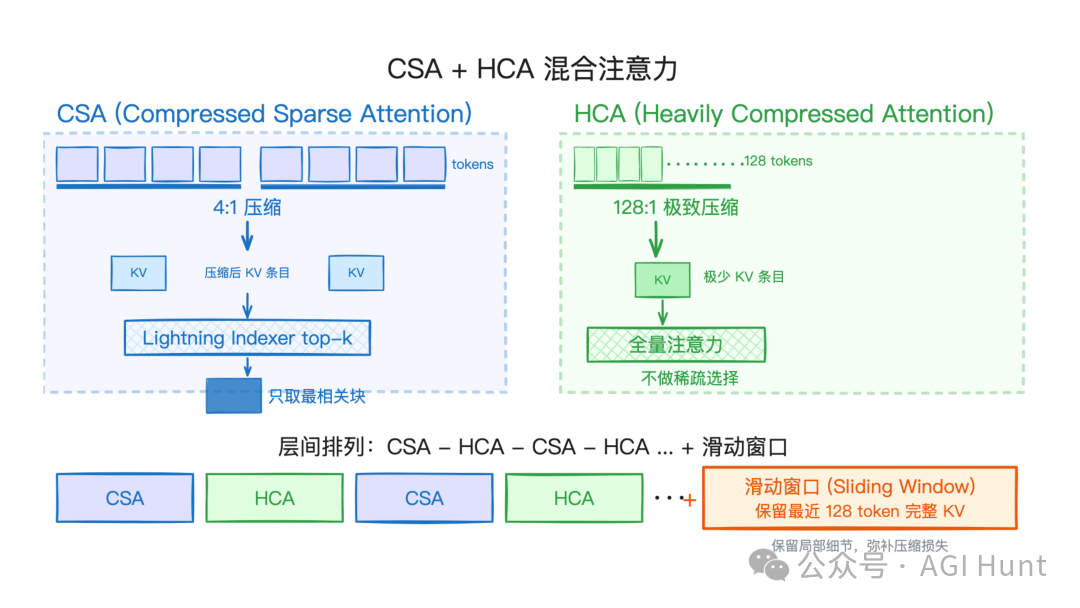
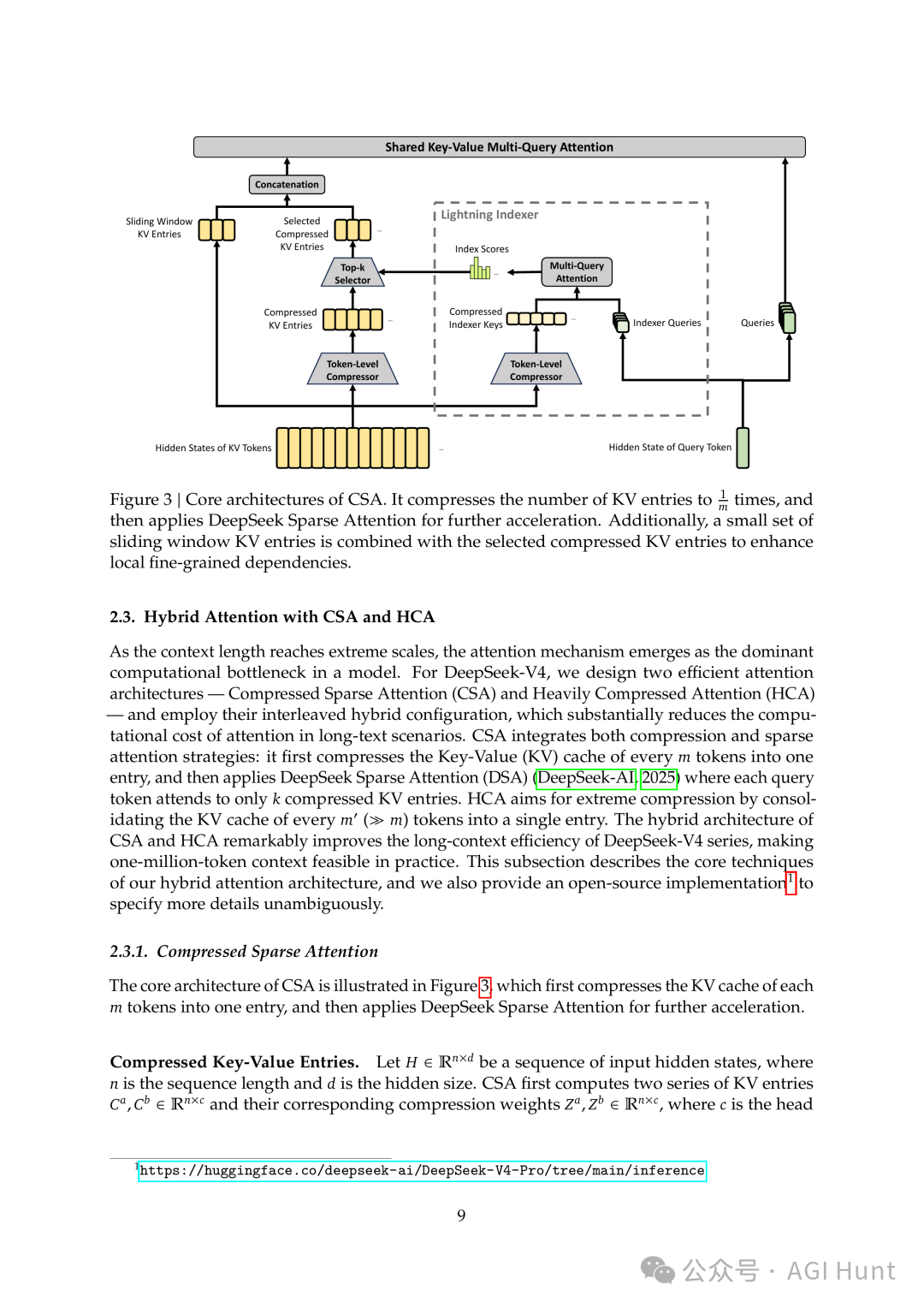
CSA + HCA 混合注意力机制
CSA(压缩稀疏注意力),每 4 个 token 的 KV 缓存压成 1 个。压完之后还有一步:用一个叫 Lightning Indexer 的轻量索引器,快速给所有压缩块打分,只挑 top-k 个最相关的块来看。既省显存,也省计算。
CSA 架构
HCA(重度压缩注意力),则压得更狠,每 128 个 token 压成 1 个。不过因为压缩太猛了,HCA 就不做稀疏筛选了,对所有压缩后的条目做完整的注意力计算,确保不遗漏。
HCA 架构
V3.2 vs V4 KV 缓存与并发对比