杨立昆用15M参数打平了万亿参数多少做点
15M 参数,1 块 GPU,打平了用 1.24 亿张图片预训练的巨型模型,规划速度快 48 倍。
为什么删掉所有的训练技巧,结果反而更好?一个不预测像素、只预测抽象表征的 AI,真的比被迫生成像素的 AI 更懂物理吗?
2024 年 Sora 发布时,整个 AI 社区在庆祝"世界模型终于来了"。
但有一个人不买账。
杨立昆(Yann LeCun),图灵奖得主,当时还是 Meta 首席 AI 科学家。他从 2022 年就在说同一件事。那年他发表了一篇 62 页的 position paper,标题叫"A Path Towards Autonomous Machine Intelligence"。核心主张只有一句:用像素预测世界是浪费的,注定失败的。AI 应该在抽象表征空间做预测,不是在像素空间。
整个 AI 社区几乎没有人听。
2024 年 2 月,Sora 发布前后,他在 X 上写了一段话:
"Modeling the world for action by generating pixel is as wasteful and doomed to failure as the largely-abandoned idea of 'analysis by synthesis'."
"That’s why generative models for sensory inputs are doomed to failure."
翻译成人话:用像素生成来建模世界,跟当年已经被抛弃的"通过合成来分析"一样,既浪费,又注定失败。
53 万次浏览。281 次转发。行业的反应:几乎没人当回事。
2025 年 11 月,杨立昆从 Meta 离职。他没有退休,而是共同创立了 AMI Labs,拿到 10.3 亿美元种子轮融资,估值 35 亿美元。投资人包括 NVIDIA 和贝索斯。他把全部赌注押在了一个方向上:世界模型。
现在,OpenAI 已宣布 Sora 即将停止服务。OpenAI 转手发布了 ChatGPT Images 2.0,工程能力强到整个行业都在讨论。而杨立昆的论文,刚刚出来。
2025 到 2026 年,AI 行业的主旋律是一场军备竞赛。
OpenAI 的 Sora 生成电影级视频,以生成逼真的视频帧为目标。GPT 据报道有超过万亿个参数。Google DeepMind 的 DreamerV4 在 Minecraft 里用像素级重建学会了打游戏。整个行业的共识清晰到不需要讨论:模型更大、数据更多、trick 更复杂,就是进步。
所有人都在做同一件事——让 AI 看到更多像素,生成更多像素,记住更多像素。
越大越好。越复杂越强。
2026 年 3 月,arXiv 上安静地出现了一篇论文。
作者列表第四个名字是杨立昆(Yann LeCun),AMI Labs 创始人。论文叫 LeWorldModel。
但参数表看起来像是写错了。
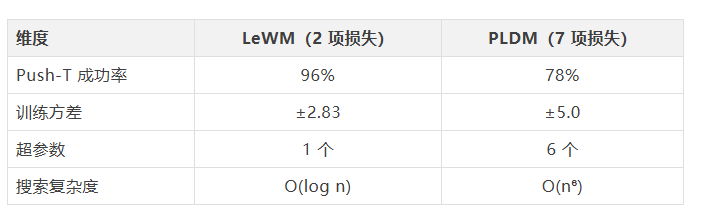
15M 参数。2 项损失函数。1 个需要调整的超参数。1 块 GPU。训练时间:几个小时。
GPT-4 据报道有超过万亿个参数。LeWorldModel 不到它的万分之一。
在一个所有人都在比谁的 GPU 更多的时代,这篇论文像是从另一个平行宇宙寄过来的信。
一篇不该成功的论文
LeWorldModel(以下简称 LeWM)是一种叫做 JEPA(联合嵌入预测架构) 的世界模型。这个名字听起来拗口,但它做的事情用一句话就能说清:它不预测像素,只预测"嵌入"。
翻译成人话:它不试图重建世界的每一个细节,只保留预测未来所需要的骨架,丢掉纹理、光影、颜色这些不可预测的噪声。
这个想法听起来合理。但 JEPA 有一个致命弱点:表示崩塌(representation collapse)。
翻译成人话:模型发现了一个作弊捷径。如果它把所有输入都映射成同一个点,那"预测未来"就变成了一个永远正确的废话——因为未来和现在已经被压缩成了同一个东西。这就像一个学生发现每次都回答"不知道"也能得满分,他就永远不会真正学习。
之前最好的解法叫 PLDM。它用了 7 项不同的损失函数和 6 个需要反复调整的超参数来防止崩塌。代价是训练不稳定,每换一个测试环境就要从头调参。用七把锁来锁一扇门,结果锁和锁之间互相卡死了。
LeWM 的做法完全不同。它只用了一把锁。
这把锁叫 SIGReg,它背后的数学原理是 Cramér-Wold 定理(克拉梅尔-沃尔德)——一个近百年前就证明了的统计学结果。这个定理说:如果你想确认一个高维分布是否符合标准正态分布(这在 192 维的空间中几乎不可能直接验证),你只需要从各个方向做一维投影,然后检查每个投影是否像正态分布。如果所有投影都像,那整体就是。
比方说你去体检。医生不需要打开你的身体检查每一个器官。他查血压、血糖、血脂、心率这几十项指标,如果每项都正常,他就可以判断你大体是健康的。SIGReg 对潜空间做的就是这种指标式体检——从 1024 个随机方向做投影,用一个叫 Epps-Pulley 正态性检验(一种统计学工具)逐一检查。不需要直接观测 192 维空间的全貌,也不需要任何工程 trick。
整个训练目标只剩两项:一项让模型学会预测(收缩力),一项让嵌入保持多样性(展开力)。需要调整的超参数从 6 个降到了 1 个。搜索策略从 O(n⁶) 的网格搜索变成了 O(log n) 的二分法。
结果出来后,有点不讲道理:
不只是打败了同为端到端的 PLDM。LeWM 还和 DINO-WM 打了个平手——后者冻结了 DINOv2 编码器,那个编码器是用大约 1.24 亿张图片预训练出来的。LeWM 从零开始,5M 参数的编码器,在 Push-T 上反而更好(96% vs 74%)。规划速度快 48 倍。
两项损失。一块 GPU。几个小时。
这张表的重点不在任何一行,而在两张表的对比本身:更少的约束,更好的结果。这不是偶然的。
这里有一个违反直觉的事实值得停下来想一想:为什么删掉大部分防崩塌工程技巧反而更稳定?直觉上,更多的稳定化手段应该带来更稳定的训练。
但论文也没有回避自己的失败。在 Two-Room 这个最简单的环境之一中,LeWM 只做到 87%,而 DINO-WM 是 100%。原因很具体:LeWM 强制嵌入匹配高维高斯分布,但 Two-Room 的真实数据结构是低维的。先验和现实不匹配。在这种情况下,越强的先验伤害越大。
这其实是整篇论文最有信息量的发现之一:最简单的问题,是最好的压力测试。
没人要求它学会的事
论文的第五章报告了一个训练目标之外的发现。
LeWM 在训练过程中,潜空间中的轨迹越来越"直"。具体来说,连续时间步的潜速度向量之间的余弦相似度从接近 0 上升到了大约 0.6。这意味着模型把复杂的时间动态编码成了近乎直线的潜轨迹。
但没有任何损失项要求它这样做。SIGReg 只约束每个时间步的分布形状,完全不涉及时间维度上的任何约束。
翻译成人话:模型自己学会了“把复杂的事情简化成直线运动”这件事。没有任何人要求它这样做。
时间路径拉直(temporal latent path straightening) 是纯粹的涌现现象。它不是被设计出来的,而是从正确的约束条件中自然生长出来的。
更有意思的是对比。PLDM 有一个专门设计的时间平滑损失叫 L_time-sim,明确鼓励轨迹变直。它投入了额外的计算和一个专用的超参数来做这件事。
然后 LeWM 的轨迹比 PLDM 更直。
一个专门花力气设计的功能,被一个完全没有考虑过这件事的系统在涌现中超越了。这不是鸡汤。这是被量化数据支撑的工程事实。
2019 年,神经科学家埃纳夫(Hénaff)等人发表了一篇关于人类视觉系统的研究。他们发现人类大脑也会把复杂的时间动态表征为近乎直线的潜轨迹。这被称为"时间拉直假说"。
进化没有"设计"这个特性。它是视觉处理在自然选择压力下的涌现副产品。
LeWM 在没有任何生物学先验的情况下,独立涌现了相同的性质。
一个在 1 块 GPU 上训练了几个小时的 15M 参数模型,和几亿年进化出来的人类大脑,在表征时间动态的方式上走到了同一个地方。这不能证明什么因果关系,但它暗示了一个深刻的可能性:时间路径拉直可能不是人类大脑的特例,而是任何高效时序预测系统的通用归纳偏置。
回到前面预埋的那个问题:为什么删掉大部分防崩塌工程技巧反而更稳定?
因为 PLDM 的 7 项损失意味着 7 个梯度方向在争夺同一组参数。每项损失都在告诉模型"你应该往这边走",但 7 个方向互相矛盾,最终的参数更新方向是一个嘈杂的折中。就像七个人同时拉一辆车的七条绳子,车在原地打转。
LeWM 只有 2 个方向。预测损失(收缩力)想让所有嵌入趋同,SIGReg(展开力)想让嵌入保持散开。两股力量的拉锯产生一个清晰的平衡点。信号干净,折中明确。
进化生物学中有一个完全同构的结构:自然选择是收缩力(物种趋同),突变是展开力(物种分散),两者的张力平衡产生了适应性物种。LeWM 的两项损失,本质上是这种张力的工程化实现。
像测试婴儿一样测试 AI
发展心理学有一个经典的实验范式叫 VoE(违反预期,Violation-of-Expectation)。
做法很简单。给 4 个月大的婴儿看两类场景:正常的场景(一个球滚下斜面,碰到墙停下来)和违反物理规律的场景(一个球穿过了墙)。然后测量婴儿盯着屏幕看了多长时间。如果婴儿看违规场景的时间显著更长,说明它觉得"不对劲"——它有物理直觉,知道物体不应该穿墙。
论文的作者用同样的方法测试了 LeWM。他们准备了三种轨迹:
1. 正常轨迹:物体按物理规律运动
2. 物理违规:物体瞬移到一个随机位置
3. 视觉变化:物体颜色突然改变
然后测量 LeWM 的"惊讶程度"——模型的预测误差峰值。
结果清楚到不需要解释。
物体瞬移:LeWM 显著惊讶。p < 0.01,三个测试环境全部如此。
物体变色:几乎无反应。
LeWM 学会了在意"物体不会凭空消失",但不在乎"物体变了什么颜色"。它学会了区分与预测相关的信息(位置、运动)和与预测无关的信息(颜色、纹理)。
这恰恰是杨立昆四年来一直在说的那句话的实验验证。
理解不是还原所有细节,而是知道哪些细节可以忽略。
人类也是如此。我们能预测一个球从桌面滚下来之后会怎么运动,但几乎没人能精确回忆球表面是什么颜色、什么纹理。我们的大脑在做和 LeWM 相同的事情——保留骨架,丢弃噪声。
论文还做了一个反面验证。他们尝试给 LeWM 加上像素重建损失——强制模型去"看清"每一个像素级别的细节,理论上这应该帮助模型"更好地理解"环境。
结果反而变差了。训练方差从 ±2.83 暴增到 ±7.54。因为重建损失迫使编码器记住和控制无关的视觉细节(纹理、阴影、光照变化),这些细节变成了规划时的噪声。"看得越清楚"不等于"理解得越深"。
他到底在反对什么
到这里可以把镜头从论文本身拉远一步。
LeWorldModel 这篇论文写得非常克制。它的对手是 PLDM 和 DINO-WM——两个 JEPA 家族内部的竞品。它没有和 Sora、Dreamer、DIAMOND 做直接实验对比。论文里没有任何一句话在挑衅生成式路线。
但论文的存在本身就是一个立场声明。
因为它的共同作者,就是前面说了四年“wasteful”的那个人。论文没有替他宣战,但数据替他说话了。
他用过一个类比。你想模拟一个足球的飞行轨迹。你需要建模球表面每一个六边形的材质吗?不需要。你只需要质量、速度和重力。
像素重建路线在做的事情,是建模每一个六边形。LeWM 在做的事情,是只保留质量、速度和重力。