DeepSeek V4报告太详尽了量子位
DeepSeek V4“迟到”半年,但发布后的好评如潮还在如潮。
中外热搜上了一整圈,科技媒体的版面今天都让给了它,OpenAI也成了它的陪衬。
大家惊叹于DeepSeek在有限条件下作出重大突破的创造力,也佩服其在2026年,还能坚定选择开源路线的决心。
可以说,一时间信息多的有些超载,但多归多,主线就两条。
第一条,百万token上下文全面开源,KV cache大幅缩减。
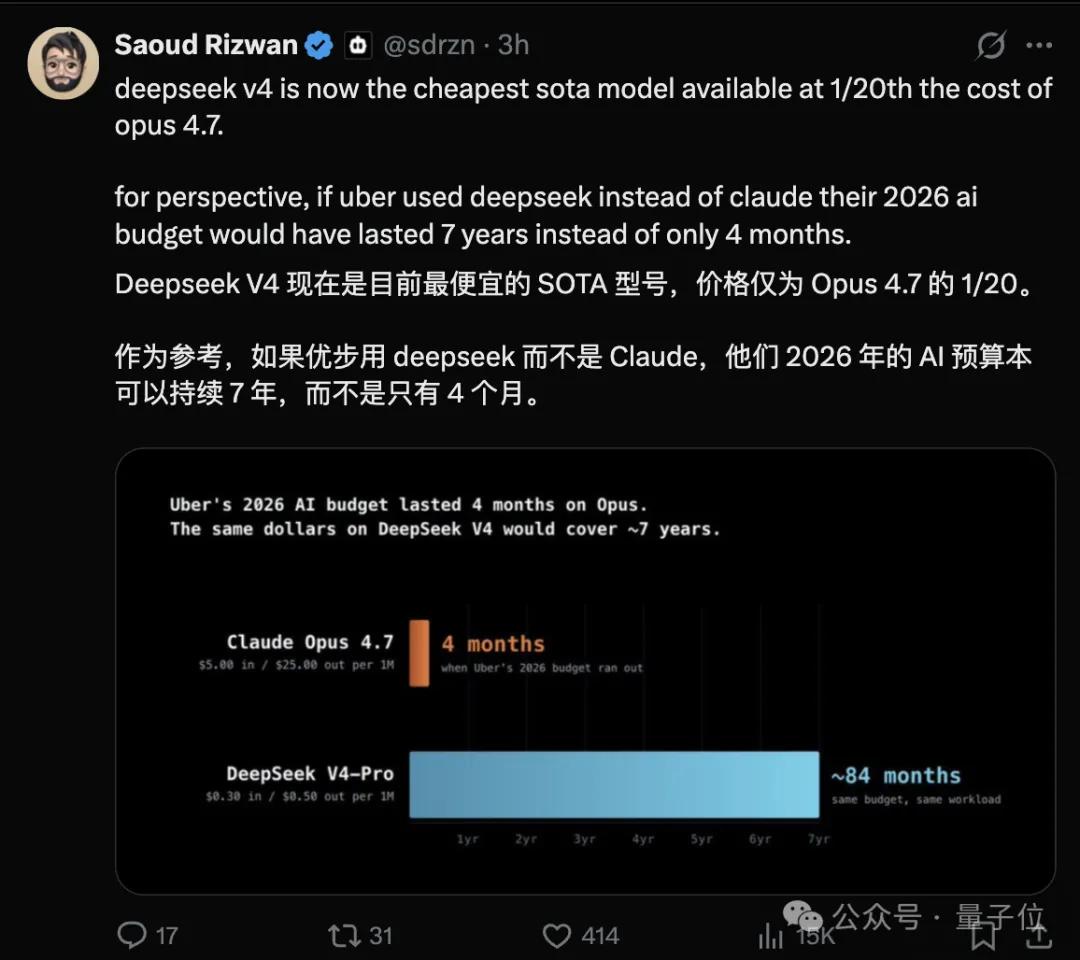
V4-Pro和V4-Flash,1.6万亿参数/2840亿参数,上下文都是1M。1M场景下,V4-Pro的单token FLOPs只有V3.2的27%,KV cache只有10%。
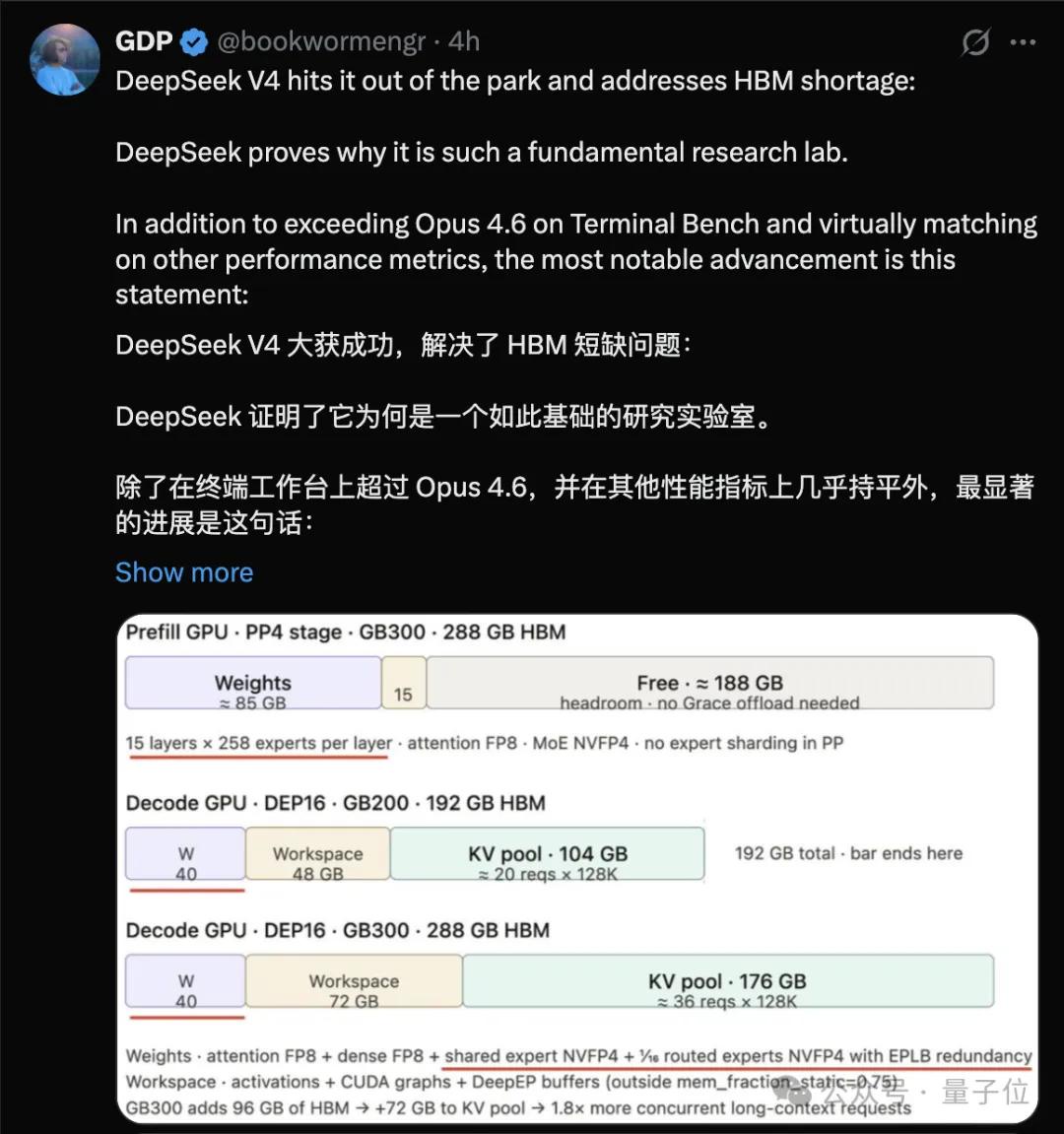
亚马逊硬件师GPD表示,这意味着DeepSeek可能解决当前的HBM短缺问题。
第二条,国产芯片适配,已经支持华为算力,预计下半年昇腾950超节点批量上市。
此外,大家最关心的,还莫过于在过去四个月中,DeepSeek陆续放出了几篇「可能进V4」的论文,今天技术报告开源了,可以对一下账。
▪︎ mHC(流形约束超连接):2025年12月31日上传arXiv,梁文锋挂名。进了V4。
▪︎ Engram(条件记忆模块):1月DeepSeek联合北大发布。没进V4,但在未来方向里被点名,留给V5。
▪︎ DualPipe:V3老伙计。继续用,针对mHC做了调整。
▪︎ Muon优化器:从Kimi那边借的。V4把AdamW替了,接管绝大多数参数的训练。
四个预期,三个落地,一个给下一代。
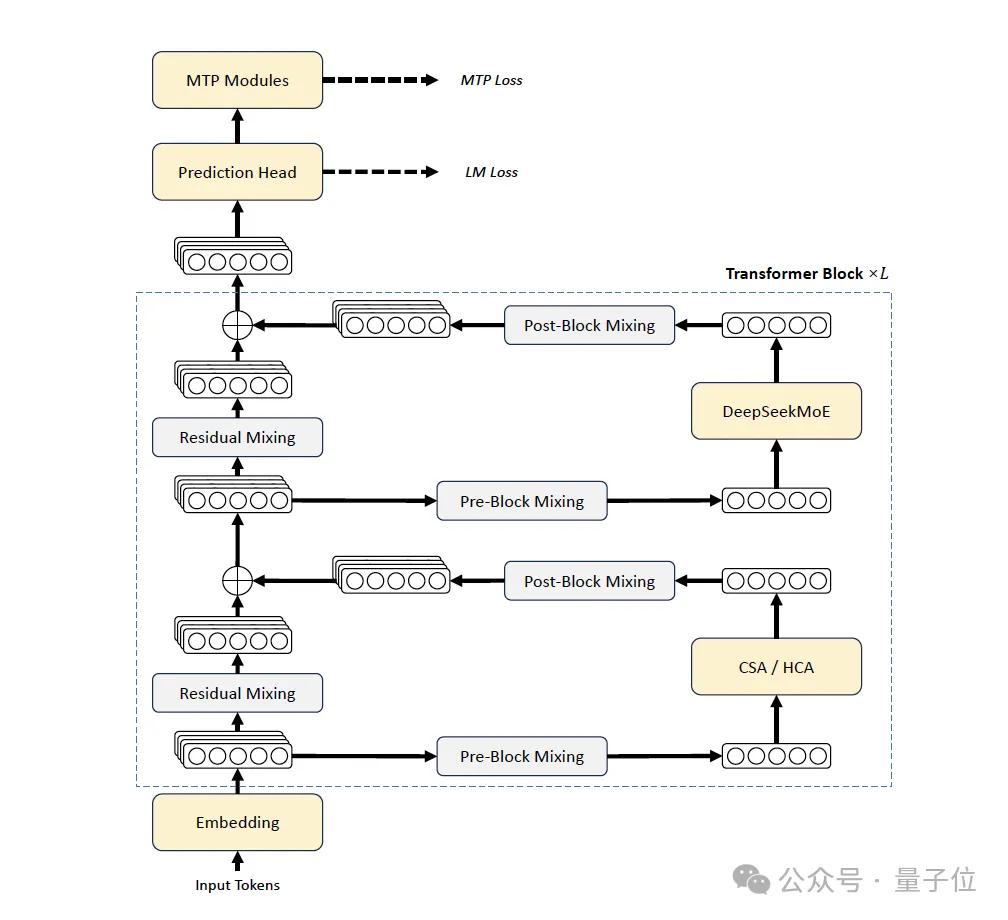
V4这一代,是DeepSeek系列里动刀最多的一版。相比V3,V4在三个地方做了升级。
第一,引入mHC(Manifold-Constrained Hyper-Connections)强化残差连接。
第二,设计hybrid attention架构,CSA和HCA交替叠加,解决长文效率问题。
第三,采用Muon作为主优化器。
MoE部分仍然用DeepSeekMoE,MTP(Multi-Token Prediction)模块跟V3保持一致。
一些细节微调包括,affinity score的激活函数从Sigmoid换成了Sqrt(Softplus(·)),去掉了routing target nodes的数量约束,前几层dense FFN换成了用Hash routing的MoE层。
接下来,我们一个个看。
mHC,给残差连接加一层约束
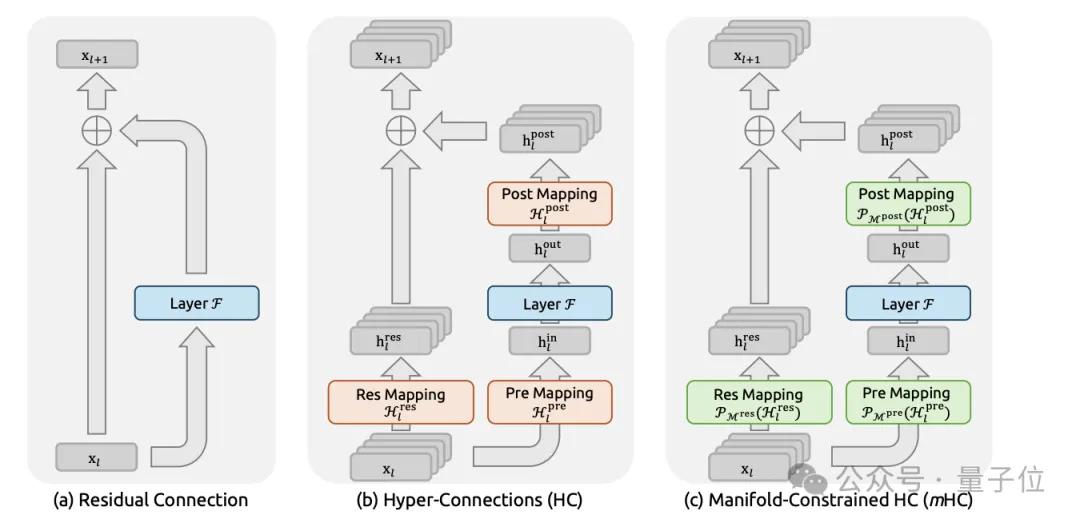
残差连接是何恺明2016年在ResNet里提出来的,十年没怎么变过。模型一层一层堆,梯度沿着残差往回传,这是深度学习能work的前提。
但模型越来越深、参数越来越多之后,传统残差开始露怯,信号传递不稳,训练容易崩。
先说Hyper-Connections(HC),这是Kimi团队之前提出的想法。核心是把残差流从一维变成n_hc条并行通道,每层之间通过一个矩阵B来混合。
A、B、C是三个线性映射。想法很优雅,相当于给残差流增加了一个新的scaling维度。但DeepSeek在堆多层时发现,HC经常出现数值不稳定,训练说崩就崩。
V4的做法叫mHC,把矩阵B约束到「双随机矩阵」的流形上(数学上叫Birkhoff polytope),行和列都归一化为1。这个约束带来两个好处。
▪︎ 矩阵的谱范数天然不超过1,残差传播套上硬上限,爆不起来。
▪︎ 这种矩阵在乘法下是封闭的,堆很多层也稳。
输入映射A和输出映射C则通过Sigmoid函数保证非负且有界,避免信号互相抵消。
实现上用Sinkhorn-Knopp迭代,交替做行归一化和列归一化,迭代20次收敛。整个过程对每一层都跑一遍。
听起来贵,但DeepSeek做了fused kernel,再配合选择性recomputation,实测mHC带来的wall-time开销控制在overlapped pipeline的6.7%。
技术判断上,mHC不是那种让人眼前一亮的架构创新,更像是一个「稳得住大模型」的工程补丁。但随着模型深度和参数量继续往上推,这种补丁会变成刚需。