给大模型验DNA,微调、蒸馏的隐藏血缘藏不住了新智元
模型数量持续增长,大模型世界正变得像一个快速膨胀的「物种库」:谁由谁微调而来,谁与谁更为接近,哪些模型实际上共享相似的能力底色,很多时候并不清楚。LLM DNA基于行为进行谱系分析,为判断模型来源提供了新依据。
如今的大模型生态,早已不再只有少数几个头部模型。
Hugging Face上的模型数量持续膨胀,不同家族、不同架构、不同 tokenizer,再加上大量微调版、蒸馏版和适配版,使整个生态越来越像一片快速扩张的「模型丛林」。
问题在于,许多模型之间究竟是否存在谱系关系,哪些能力继承自上游模型,哪些只是表面上看起来相似,往往无法从模型卡或发布说明中直接看出。
这不仅影响我们对模型生态的理解,也关系到模型治理、安全审计以及多智能体系统设计。
现有方法仍存在明显局限:有些依赖特定任务,难以刻画模型的整体特征;有些仅适用于固定模型集合,缺乏对新增模型的可扩展性;还有一些方法较强依赖 tokenizer 或内部结构,因而难以适配异构模型。归根结底,这一方向仍缺少一种更通用、更稳定、且更具扩展性的模型「身份表示」。
面对这一问题,新加坡国立大学与上海交通大学联合团队提出了LLM DNA,尝试像研究生物演化一样,用功能行为表征刻画模型之间的「亲缘关系」。他们不仅从数学上定义了什么是 LLM DNA,还提出了一套无需训练的提取方法RepTrace,并在305个大模型上进行了验证。结果表明,这种「DNA」不仅能够识别模型之间的关系,还能进一步构建大模型的系统发育树。
论文链接:https://openreview.net/pdf?id=UIxHaAqFqQ
项目代码:https://github.com/Xtra-Computing/LLM-DNA
项目网站:https://dna.xtra.science/
该论文已被ICLR 2026 接收为Oral,约占总投稿量的1%。
给模型做「DNA检测」,核心不是看参数,而是看模型「怎么回答」
LLM DNA的核心思想,是从模型的功能行为而非参数表面出发,对 LLM 进行统一表征。
研究团队把这种从功能行为中提炼出来的低维表征称为「LLM DNA」,如果两个模型在很多问题上的反应模式很接近,那么它们的DNA也应该彼此接近;如果两个模型差得很远,它们的DNA也应该拉开。
论文进一步证明,这样的表征具备两种类似生物DNA的性质:一是「继承性」,也就是模型经过微调或演化后,DNA 不会突然彻底变掉;二是「遗传决定性」,也就是 DNA 相近的模型,行为上通常也更相似。
不用重训的「验DNA」流程
为了将这一思想落到实践,作者提出了训练无关的 DNA 提取流程 RepTrace。具体而言,该方法首先构造一组统一的 probe 输入,收集不同模型在这些输入上的文本响应;
随后利用冻结的句向量模型将响应编码为语义embedding,并将多条响应embedding串接为高维功能表示;
最后,基于Johnson–Lindenstrauss lemma所支撑的随机投影思想,采用随机高斯投影将这一高维表示压缩到低维 DNA 空间。
这里的关键并不只是降维本身,而是在压缩过程中尽可能保持不同模型在功能行为上的相对几何结构,从而使语义上相近的模型在 DNA 空间中仍然彼此接近。
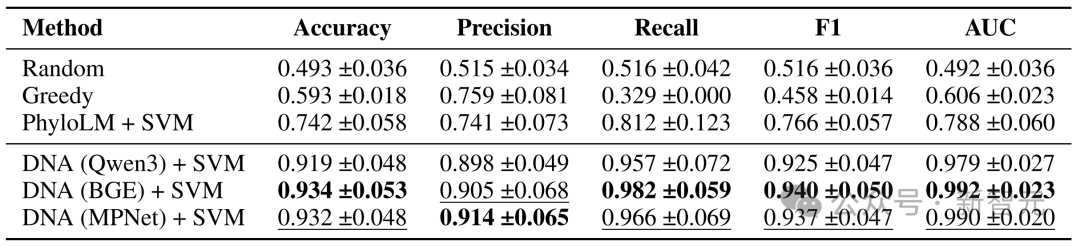
值得注意的是,这里的 probe 输入并不依赖精心设计的任务数据。论文及其官方材料表明,即便使用按固定规则随机生成、且完全不经过任何大模型参与构造的文本作为输入,提取出的 DNA 依然能够保持很强的判别能力;在关系预测任务中,这种随机输入设定下的 AUC 仍可达到 0.987。
这个结果说明,LLM DNA 并不依赖特定 benchmark 的题目形式,而能够从更一般的输入中捕捉模型较为稳定的功能特征。随机输入的意义主要在于,它有助于减弱特定评测集、训练语料或题目分布带来的偏置。
面对一个新模型,只需在同一套输入和流程下提取其 DNA,便可直接纳入现有比较框架,而无需重新训练或调整其他模型的表示。
这项工作的一个重要亮点,在于其实验验证具有较大的覆盖范围。研究共分析了来自153家机构的305个大模型,覆盖不同架构、不同参数规模,并同时包含 base 模型与 instruction-tuned 模型。
实验结果表明,基于 LLM DNA 的关系检测取得了接近 0.99 的 AUC,显著优于多个基线方法。这说明,LLM DNA 能够较为稳定地区分彼此存在关联的模型与关系较弱或无明显关联的模型。
更有意思的是,DNA还能够帮助发现一些文档里没有明说的潜在关系。论文在 305 个模型的t-SNE可视化中观察到,同一机构、同一家族的模型往往自然聚在一起,而一些没有明确记录来源的模型,也会靠近其可能的上游家族。
这种现象说明,LLM DNA不只是「复述已知关系」,还可能成为发掘隐藏演化线索的新工具。
除了「认亲」,DNA还可以拿来做模型路由。论文把DNA用在与EmbedLLM相同的路由设定中,结果显示,冻结的DNA表示在测试集上的路由准确率达到0.672,略高于EmbedLLM的0.665。
更重要的是,EmbedLLM的表示是围绕该任务专门学出来的,而LLM DNA并没有针对路由任务做任何专门训练。这说明,它确实更接近一种任务无关的模型「基础表征」。
在305个模型的大规模实验之外,LLM DNA 的价值还体现在对新模型的实际分析上。
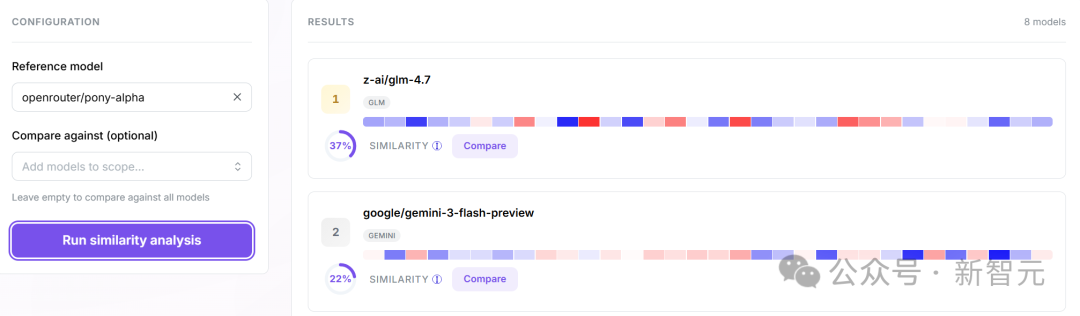
最近,在GLM 5.1相关信息尚未完全公开之前,研究团队利用LLM DNA的workbench对openrouter/pony-alpha进行了比较分析。
结果显示,在候选模型中,pony-alpha与z-ai/glm-4.7的DNA相似度最高,显著高于Gemini等其他模型;从功能行为表征的角度看,这一结果为其可能属于 GLM 谱系提供了较强线索。
与依赖公开文档、命名方式或零散传闻不同,这种判断直接建立在模型响应所形成的功能表示之上,因此更接近一种「基于行为的谱系分析」。这一案例也说明,LLM DNA的意义并不局限于论文中的离线基准评测。
除了在305个模型上系统验证其能够稳定识别模型关系之外,它还可以作为面向新模型的分析工具,在公开信息有限的情况下,为模型来源、继承关系和潜在家族归属提供额外证据。
从「模型指纹」走向「模型进化树」
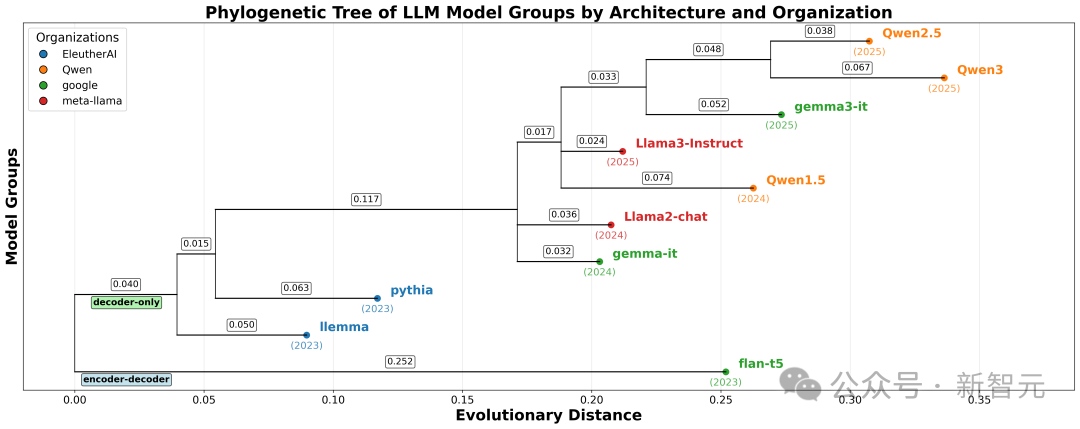
当模型之间的距离可以量化之后,下一步就很自然了:能不能把整个大模型世界画成一张「家谱图」?
论文确实这么做了。团队基于 DNA 距离构建了系统发育树,结果发现这棵树能够比较自然地反映出一些真实世界中的演化规律:例如从encoder-decoder到decoder-only的整体迁移,不同家族随时间推进的演化,以及像Llama、Qwen、Gemma这样的家族分支结构。论文还观察到,不同家族的「演化速度」似乎也不一样,有些分支变化更快,有些则更平稳。
这也是这项工作最容易打动人的地方之一。过去我们谈模型演化,很多时候靠的是发布时间、模型名字、官方说明,或者圈内经验判断。LLM DNA提供的则是另一种视角:直接从模型实际表现出发,反过来重建它们之间的关系图谱。对于越来越复杂的大模型生态来说,这种「从行为反推谱系」的能力,本身就很有价值。
为什么这件事重要
从更现实的角度看,LLM DNA可能带来几类直接价值。
第一是模型溯源。未来如果某个模型出现安全问题、版权争议或许可证争议,DNA可能成为辅助判断其来源和演化关系的证据之一。
第二是模型治理。对于企业或平台来说,面对海量模型,如何快速判断哪些模型相近、哪些模型值得保留、哪些模型可能只是已有模型的近似变体,DNA可能提供新的组织工具。
第三是多模型系统设计。如果不同模型之间的「亲缘远近」能够量化,就可能帮助我们更合理地做路由、集成甚至多智能体协作分工。论文在引言中也明确提到,这正是该工作的几个重要动机。
当然,LLM DNA不是说一个低维向量就能解释模型的一切。更准确地说,它提供的是一种更统一、更可扩展的「观察模型」的方式。过去很多模型之间的关系,要么只能靠公开资料猜,要么只能靠零散案例分析。现在,至少有了一种办法,可以比较系统地识别这些潜在的谱系关系。
LLM DNA这项工作的吸引力,不只是在于它提出了一个新名字,更在于它把一件很多人隐约觉得重要、但一直缺少统一工具的事情,真正往前推了一步:在模型越来越多、版本越来越杂、公开谱系越来越不透明的时代,我们能不能像「验DNA」一样,从模型回答问题的方式里,看出它和谁更像、可能继承了谁、又和哪些模型暗中相连。
从这个角度看,这项ICLR'26 Oral工作最值得传播的,并不只是一个接近0.99的数字,而是它让「发现模型隐藏谱系」这件事,开始变得更系统、更可操作,也更容易被真正用起来。