世界引擎:Post-Training开启Physical AGI机器之心
一年前,DeepSeek R1 横空出世,人们才意识到,真正让模型产生推理能力质变的,不必是更大的预训练规模 —— 后训练,用强化学习、过程奖励、闭环反馈,以极低的代价解锁了原本需要数倍算力才能触达的能力边界。
这场范式革命,正在物理世界重演。
自动驾驶系统已经在海量驾驶数据上完成了预训练,但距离真正的 Physical AGI,仍有一道鸿沟:模型知道 "该怎么开",却不知道「为什么这样开更好」。真正的进化,需要闭环、需要反馈、需要在与世界的交互中不断修正。
香港大学李弘扬团队联合华为、上海创智学院及清华大学李升波教授团队,共同给出了他们的答案——世界引擎:以后训练为核心范式,以闭环仿真为训练环境,驱动自动驾驶系统在海量真实与合成场景的交互中,涌现出真正的决策能力。
代码地址:https://github.com/OpenDriveLab/WorldEngine
主页:https://opendrivelab.com/WorldEngine/
作为自动驾驶领域的重要学术力量,2022 年底,OpenDriveLab 推出 UniAD—— 第一个将感知、预测、规划统一在单一框架下的端到端系统,以「规划为中心」重新定义了自动驾驶的建模范式,成为学术界公认的里程碑。
但 UniAD 之后,一个更深的问题浮出水面:端到端系统在学术 benchmark 上表现优异,真实世界却是另一回事。
雨夜里逆行的电动车,施工路段突然倒下的锥桶,大客车后方的鬼探头 —— 这些长尾场景,在训练数据里几乎不存在。靠更大的数据集、更深的网络,无法根本性地解决。
OpenDriveLab 开始从两个方向同时推进。一方面,MTGS 通过多次遍历的 3D 高斯泼溅技术,构建出高保真的可渲染驾驶场景 —— 这是闭环仿真的物理基础。另一方面,Nexus、Omega 等世界模型工作聚焦于反事实难例高动态交互模拟,突破真实数据对长尾场景覆盖的天然局限。
至此,一个核心问题自然浮现:有了高保真仿真环境,有了能生成难例的世界模型,如何让端到端系统真正在其中安全进化?
答案,就是后训练。
2025 年 4 月,华为发布 ADS 4.0,正式披露了全新技术架构 WEWA。其中云端核心 World Engine,正是华为与 OpenDriveLab 联合开发的成果。(https://auto.huawei.com/cn/ads)华为将这套架构的目标定义为:面向自动驾驶,从类人到超人。
World Engine,由此登场。
World Engine:迈向物理 AI 的后训练时代
如果说预训练让自动驾驶系统学会了「模仿」,那后训练要解决的,是如何让系统学会「判断」。
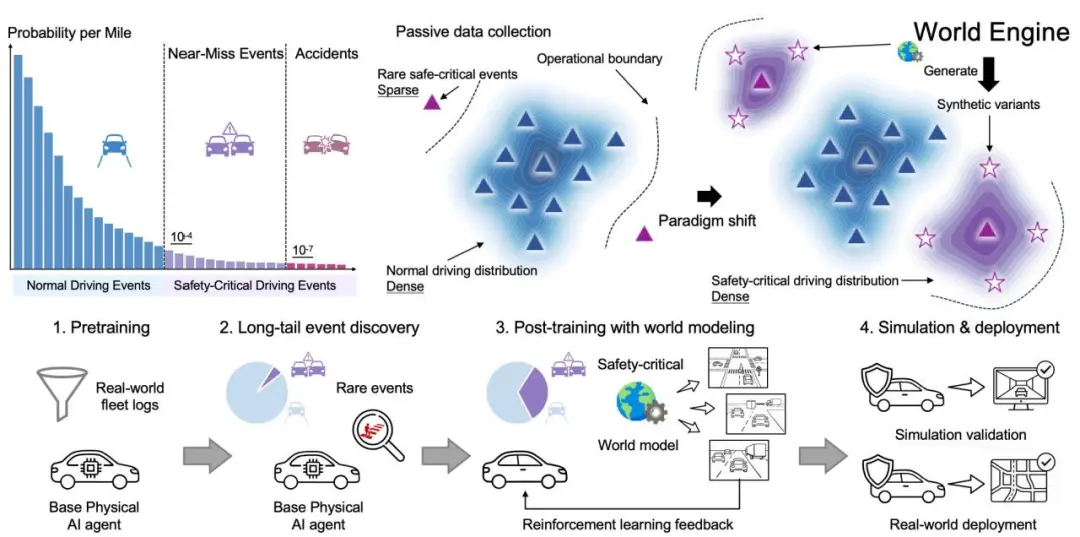
World Engine 的设计哲学,正是围绕这一目标展开。它不是一个单一模型,而是一套完整的后训练 pipeline,由三个核心能力构成:
3DGS 仿真环境 —— 基于 3DGS 构建的高保真视觉输入,为后训练提供了真正意义上的闭环反馈。系统的每一个决策,都能在环境中得到即时响应,而不是停留在数据回放。
难例挖掘 & 扩散生成 —— 真实世界的长尾场景稀缺且难以复现。World Engine 首先从海量真实驾驶数据中主动挖掘难例,再以世界模型为工具,对这些难例进行扩散生成后,依托仿真环境进行渲染,放大长尾场景的密度与多样性,让系统在训练中「见过」它在路上可能遇到的一切。
基于强化学习的后训练 ——World Engine 在仿真生成的大规模难例场景上,以强化学习驱动系统优化,将安全价值规范内化为奖励信号,让系统不只是「开得快」,更是「开得对」。
三者协同,构成了一个完整的飞轮:仿真生成难例,难例驱动后训练,后训练强化决策能力。
图 1 World Engine 架构总览
从暴露弱点到超越弱点
三个模块,一套飞轮。
难例挖掘与扩散生成
World Engine 首先让模型「自己暴露弱点」。将预训练好的端到端模型在训练集上做开环推理,以 PDMS 作为评判标准,自动筛选出模型表现差的场景 —— 碰撞、偏离道路、自车停滞不前。这些场景,就是模型的能力边界所在。
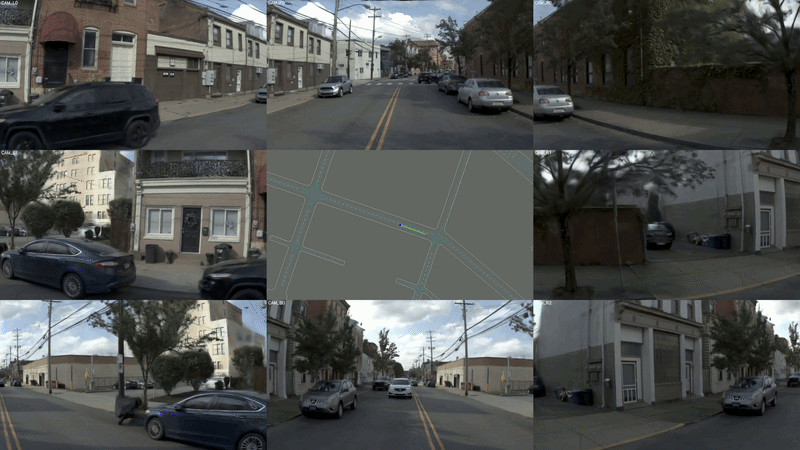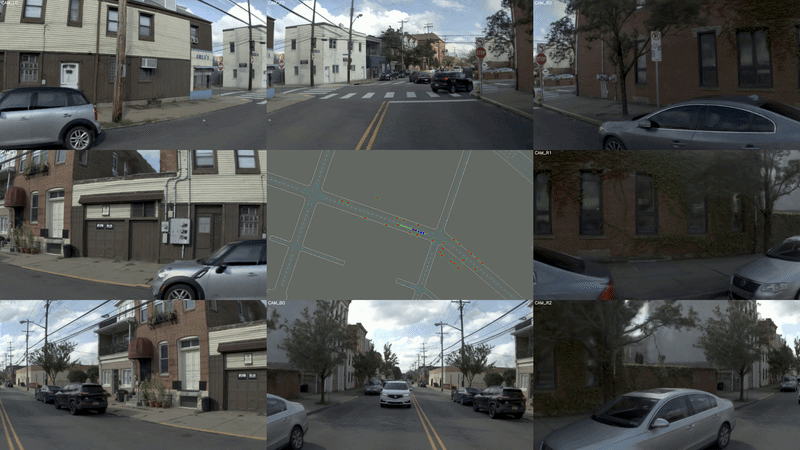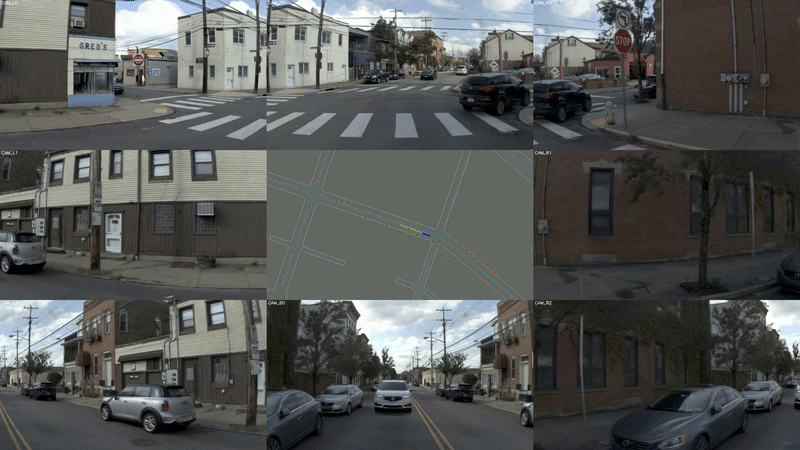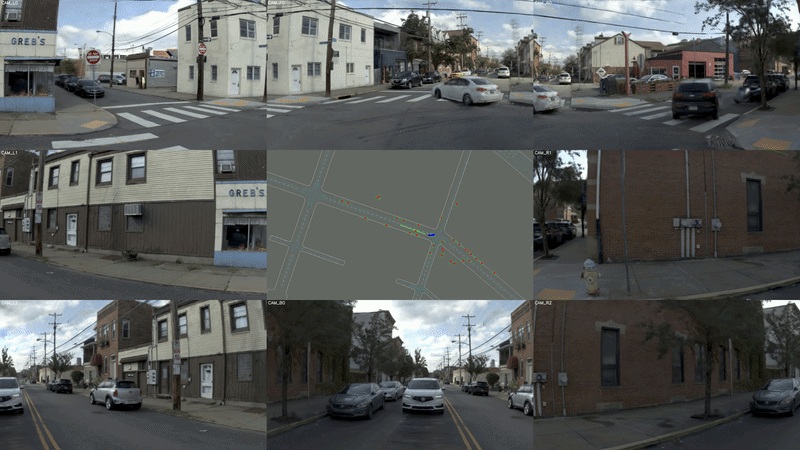
挖掘出难例之后,World Engine 并不止步于此。行为世界模型(Behaviour World Model) 以解耦扩散的方式,对这些难例场景进行变体生成 —— 在保持真实地图拓扑与场景布局的前提下,引入对抗性交通行为,批量合成高密度的安全关键场景。真实数据的长尾,由此被系统性地放大。
图 2 难例扩散生成典型 case
高保真闭环仿真
难例场景需要一个足够真实的舞台。World Engine 内置了基于 3DGS 的场景重建 pipeline—— 融合同一路段的多次真实驾驶记录,构建出扎根于真实世界的高保真三维场景。这不是凭空生成的虚拟沙盒,而是闭环训练的真实物理基础。
图 3 高保真闭环仿真效果图
基于强化学习的后训练
有了大规模难例数据,World Engine 以离线强化学习驱动端到端模型持续优化。奖励信号将舒适性、避障、道路合规等安全价值直接内化为训练目标。模型不再只是模仿人类驾驶员,而是在与难例的反复博弈中,学会真正的安全决策。
图 4 navsim 测试难例集对比
World Engine 发现了什么?
数据量上做加法,不如在训练范式上做乘法
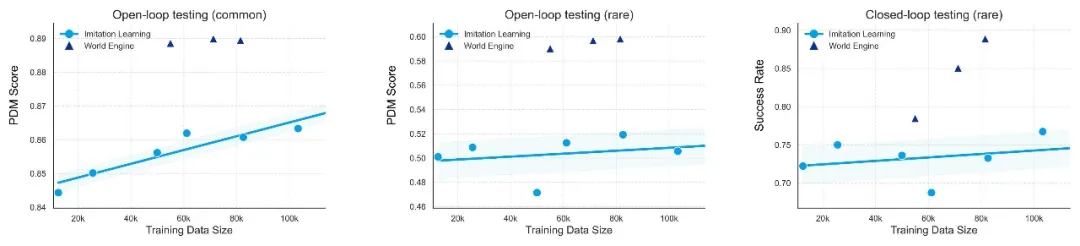
图 5 验证 Data Scaling: 将预训练数据集场景数量从 12k 增广至 103k 进行对比
自动驾驶行业有一个长期信仰:数据越多,模型越安全。World Engine 给出了一个更复杂的答案。
将预训练数据从 1.3 万个场景一路扩大到 10.3 万个,在日常驾驶场景上,scaling law 如期生效 —— 数据越多,表现越好。但在安全关键的长尾场景上,曲线很快躺平。原因并不意外:真实路测中危险场景本就极度稀缺,堆再多常规数据,模型在关键时刻依然束手无策。
数据 scaling,在长尾场景这件事上,撞上了天花板。
World Engine 的后训练给出了另一条路径:在仿真环境中以强化学习反复博弈难例场景,将避障、合规、舒适性直接编码为优化目标,同时确保系统不丢失预训练阶段习得的基础驾驶能力。从同一个基础模型出发,后训练直接跨越了 scaling 曲线,实现了等效于将预训练数据扩大约 14 倍的闭环性能增益。
一块都不能少
后训练有效,但增益从何而来?World Engine 对自身的三个核心模块做逐一拆解。