谷歌第八代TPU,为什么是两款?华尔街日报
谷歌将AI芯片战略推向新阶段。
在周三拉斯维加斯举行的Google Cloud Next 2026大会上,谷歌云发布第八代张量处理器(TPU)的两款新品——专为训练设计的TPU 8t与专为推理优化的TPU 8i,这是谷歌首次将训练与推理任务拆分至独立芯片,标志着其AI硬件路线的重大转向。
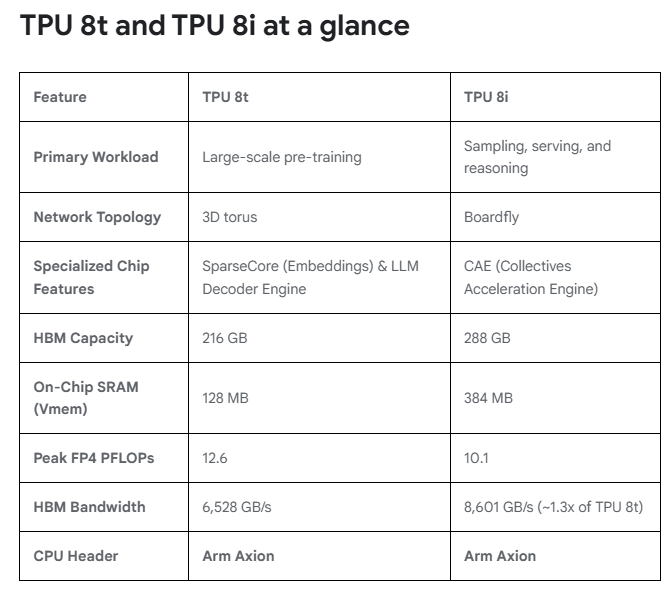
两款芯片均计划于2026年晚些时候正式对外供应。与去年11月发布的第七代Ironwood TPU相比,TPU 8t在同等价格下性能提升2.8倍,TPU 8i性能提升80%;两款芯片每瓦性能均较上一代提升逾一倍,TPU 8t达124%,TPU 8i达117%。
谷歌高级副总裁兼AI与基础设施首席技术官Amin Vahdat表示,随着AI智能体的兴起,"业界将受益于针对训练和推理各自需求专门优化的芯片"。Alphabet首席执行官桑达尔·皮查伊亦在博客中指出,这一架构旨在"以具有成本效益的方式,提供同时运行数百万个智能体所需的大规模吞吐量和低延迟"。
为何拆分为两款芯片
此次将第八代TPU一分为二,是谷歌对AI工作负载日益分化趋势的直接回应。预训练、后训练与实时推理在计算特性上已显著分化:训练任务追求极致吞吐量与规模扩展,推理任务则对延迟和并发更为敏感。单一芯片难以同时兼顾两类场景的效率最优。
谷歌在技术博客中指出,第八代TPU的设计哲学围绕可扩展性、可靠性与效率三大支柱,两款芯片共享谷歌AI软件栈的核心基因,但各自针对不同瓶颈进行了专项优化。
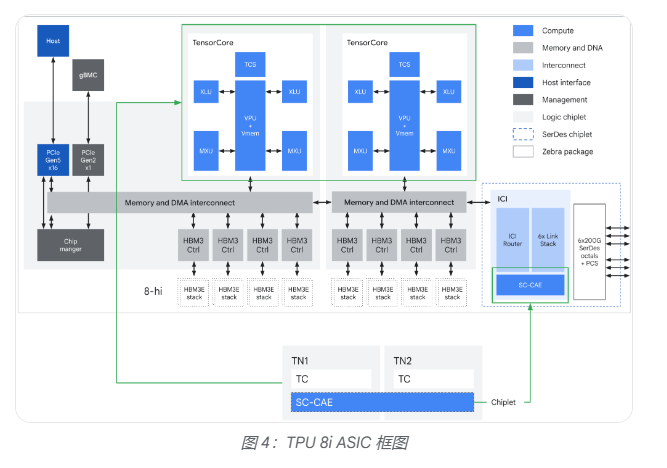
两款芯片均集成了基于Arm架构的Axion CPU,以消除数据预处理延迟造成的主机侧瓶颈,确保TPU计算单元持续满载运行。
TPU 8t:面向超大规模训练的算力引擎
TPU 8t定位为预训练与嵌入密集型工作负载的专用加速器,谷歌称其能够"将前沿模型开发周期从数月压缩至数周"。
在规模上,TPU 8t最多可将9600块芯片组合为单一超级计算节点(superpod),并通过JAX与Pathways框架将分布式训练扩展至单一集群超过100万块TPU芯片。
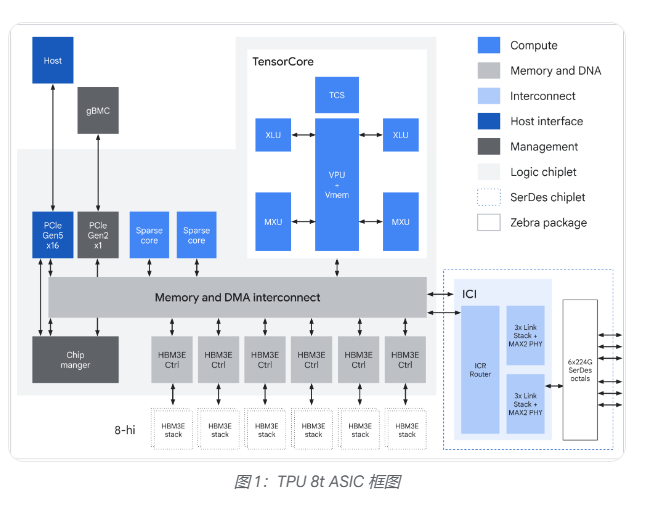
芯片层面,TPU 8t引入了三项关键技术创新。
其一是SparseCore加速器,专门处理嵌入查找中不规则的内存访问模式,将数据依赖的全局聚合操作从矩阵乘法单元(MXU)中卸载,避免通用芯片常见的零操作瓶颈。
其二是原生FP4支持,通过4位浮点数将MXU吞吐量翻倍,同时降低数据搬运的能耗,使更大的模型层可驻留于本地硬件缓冲区。
其三是更均衡的向量处理单元(VPU)扩展设计,使量化、softmax等向量操作与矩阵乘法实现更好的流水线重叠,提升芯片整体利用率。
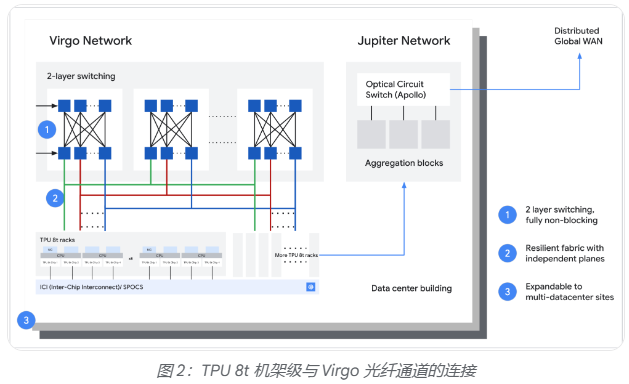
网络层面,谷歌为TPU 8t引入了全新的Virgo网络架构,采用高基数交换机与扁平化两层非阻塞拓扑,将数据中心网络(DCN)带宽较上一代提升最高4倍,芯片间互联(ICI)带宽提升2倍。单一Virgo网络可连接逾13.4万块TPU 8t芯片,提供高达47拍比特/秒的非阻塞双向带宽,整体算力超过160万ExaFlops。
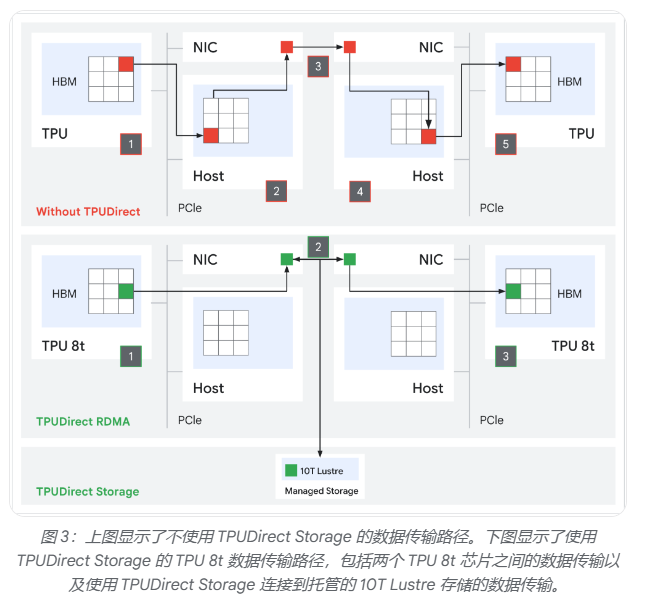
存储方面,TPU 8t引入TPUDirect RDMA与TPUDirect Storage技术,绕过主机CPU直接在TPU高带宽内存(HBM)与网卡、高速存储之间传输数据,存储访问速度较第七代Ironwood TPU提升10倍,可确保MXU在处理大规模多模态数据集时保持满载。
TPU 8i:面向高并发推理的低延迟专家
TPU 8i针对后训练阶段与高并发推理场景设计,其架构重心在于降低延迟、提升每芯片的并发处理能力。
片上存储是TPU 8i最显著的硬件特征。每块芯片集成384MB静态随机存取存储器(SRAM),是上一代Ironwood的三倍,可将更大的KV Cache完整保留在芯片上,大幅减少长上下文解码过程中核心的空闲等待时间,对需要多步骤推理的AI任务尤为关键。
TPU 8i还引入了集合加速引擎(CAE),专门加速自回归解码与"思维链"处理中的归约与同步步骤。每块TPU 8i芯片包含两个张量核心(TC)与一个CAE芯粒,取代了上一代Ironwood中的四个SparseCore,片上集合操作延迟降低5倍,直接提升了同时运行数百万智能体所需的吞吐量。
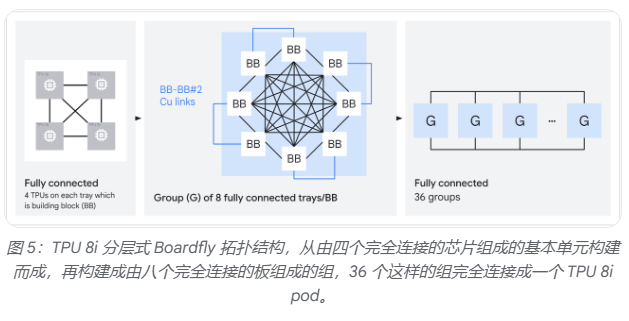
网络拓扑方面,TPU 8i放弃了TPU 8t沿用的3D环面(torus)结构,转而采用全新的Boardfly互联拓扑。3D环面在1024芯片配置下,任意两芯片间最多需要16跳;Boardfly通过高基数设计将最大跳数压缩至7跳,网络直径缩减56%,全对全通信延迟改善最高50%,对混合专家模型(MoE)和推理模型中频繁的跨芯片令牌路由尤为有利。Boardfly采用分层结构,从四芯片构建块逐级扩展至最多1152块芯片的完整Pod,并通过光学电路交换机(OCS)实现组间互联。
软件生态与市场意义
谷歌强调,硬件性能的释放有赖于配套软件栈的协同。
第八代TPU延续第七代Ironwood建立的软件体系,支持JAX、PyTorch、Keras及vLLM等主流框架,并提供Pallas自定义内核语言以充分挖掘SparseCore与CAE的硬件潜力。
谷歌同时宣布,原生PyTorch对TPU的支持现已进入预览阶段,用户可直接将现有PyTorch模型迁移至TPU运行,无需修改代码。
从市场角度看,谷歌此次双芯片策略直接回应了AI基础设施成本压力。训
练与推理对硬件的需求差异显著,统一芯片意味着在某一场景下必然存在资源浪费。通过专项优化,谷歌得以在价格性能比上实现更大幅度的提升,为云客户提供更具竞争力的单位算力成本。
两款芯片均已纳入谷歌云AI Hypercomputer超算架构,与硬件、软件及网络深度集成,覆盖AI全生命周期工作负载。