动动嘴写SQL:OpenAI把查询难度直接归零新智元
2026年初,当大多数企业还在用数据分析师手动写SQL查表时,OpenAI内部曝光的能自主思考、推理甚至自我进化的数据分析智能体,将数据查询从「天数级」缩短至「分钟级」。
为什么数据团队总在「踩同一个坑」?
答案往往不是算力不够多,而是表太多、定义太多、经验散落太多:
同样叫「活跃用户」,不同表的口径可能完全不一样;即便选对表,也要写出上百行 SQL 才能跑出结果,错一个连接条件就前功尽弃。
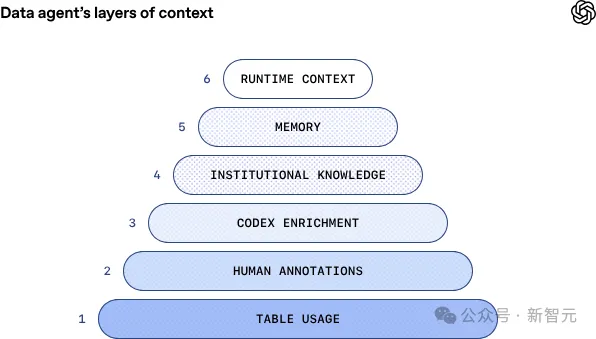
在内部,OpenAI做了一件更激进的事:让 Codex 驱动的数据智能体接管「找表—懂表—写SQL—校验结果」这条链路,用一套六层上下文架构,把数据语义补齐、把组织知识接入、把经验记忆沉淀,让工程师用提问取代搬砖。
数据查询不再需要手动查表
「我们有大量结构相似的表,我花费大量时间试图弄清楚它们之间的区别以及该使用哪个。」一位OpenAI工程师的日常抱怨,道出了数据工作者的共同困境。
OpenAI内部数据平台的600PB数据,分布在7万个数据集中,想象一下:当OpenAI的工程师需要分析ChatGPT用户增长时,面对数十个相似的用户表,每个表都声称记录「用户活跃度」,但定义却各不相同。
选错表意味着数天的努力付诸东流,更糟糕的是可能基于错误数据做出关键决策。
更令人头疼的是,即使选对了表格,生成正确结果也充满挑战。
下图中展示的一个180多行的SQL语句,像一座难以逾越的大山——复杂的表连接、聚合操作,任何一个细微错误都可能导致整个分析失效。
而现在有了由 Codex 驱动,具有自主学习能力的智能体,工程师不必写上百行的SQL查询语句,只需要提问就能从数据海洋中找到所需的信息,例如下图查询中要求对比两个时间点的活跃用户数。
六层架构的「数据大脑」
将自然语言变成SQL语句,这样的工具很多,而OpenAI内部使用的数据智能体,其核心创新在于其多层上下文架构。
最底层的基础元数据包括表结构、列类型等基础信息,为智能体提供数据图谱的骨架。
在其一层是人工标注,是由领域专家精心编写的表和列描述,捕捉意图、语义、业务含义以及无法从模式或历史查询中轻松推断的已知注意事项。这一层相当于给智能体对每个表的信息进行了基础培训。
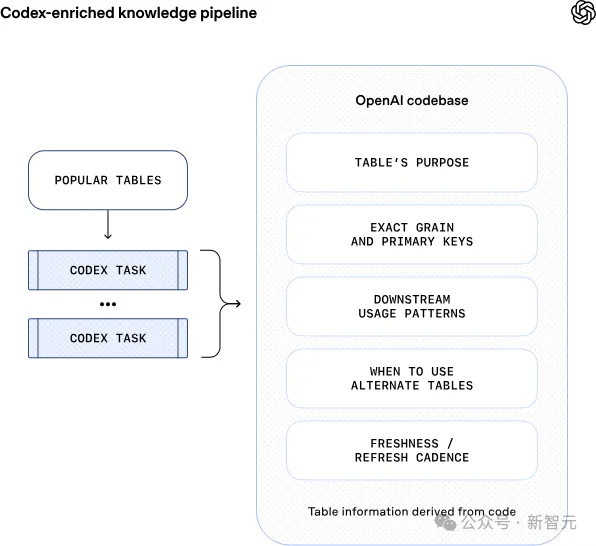
之后的Codex增强通过推导表的代码级定义,让智能体能够更深入地理解数据实际内容。这一层提供了关于值唯一性、表数据更新频率、数据范围等关键信息。这一层的引入,让智能体能够明白不同表在构建,更新上的差异。
再往上的机构知识层,智能体可以访问Slack、Google Docs和Notion,获取关键的公司背景信息,如产品发布、可靠性事件、内部代号和工具,以及关键指标的规范定义和计算逻辑。
有了通过外在文本获取的背景信息,智能体就不会犯下常识性错误。
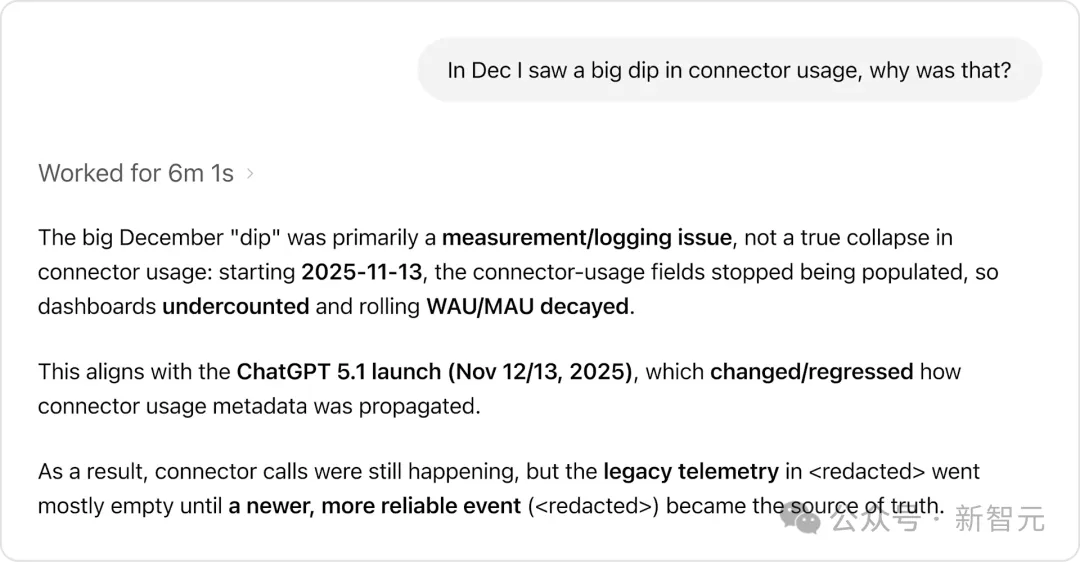
例如,当用户询问「12月连接器使用量为何大幅下降」时,智能体没有简单地报告数字下降,而是通过机构知识发现这主要是测量/日志记录问题,而非真正的使用量崩溃,与ChatGPT 5.1发布导致的数据收集变化相关。
而最关键的第五层学习进化,让智能体拥有持久的记忆。当它从用户那里获得纠正,或发现数据问题的细微差别时,能够保存这些经验供下次使用。记忆也可以由用户手动创建和编辑。可以全局适用,也可以是只独属于某个使用者。
而最上一层的运行时上下文,能够让智能体在没有现有上下文或现有信息过时时,通过实时查询数据仓库,直接检查和查询表。它还能够与其他数据平台系统(元数据服务、Airflow、Spark)通信以获取更广泛的数据上下文。