1.8万美金干掉顶级专家新智元
1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。
最新突破,AI再次碾压人类!
最近,Anthropic发布了一篇看似不起眼的研究博客。
标题叫「自动化对齐研究员」(Automated Alignment Researchers),学术味十足,措辞克制。
但如果你读懂了里面的数据,大概率也会感觉AI恐怖如斯。
故事是这样的——
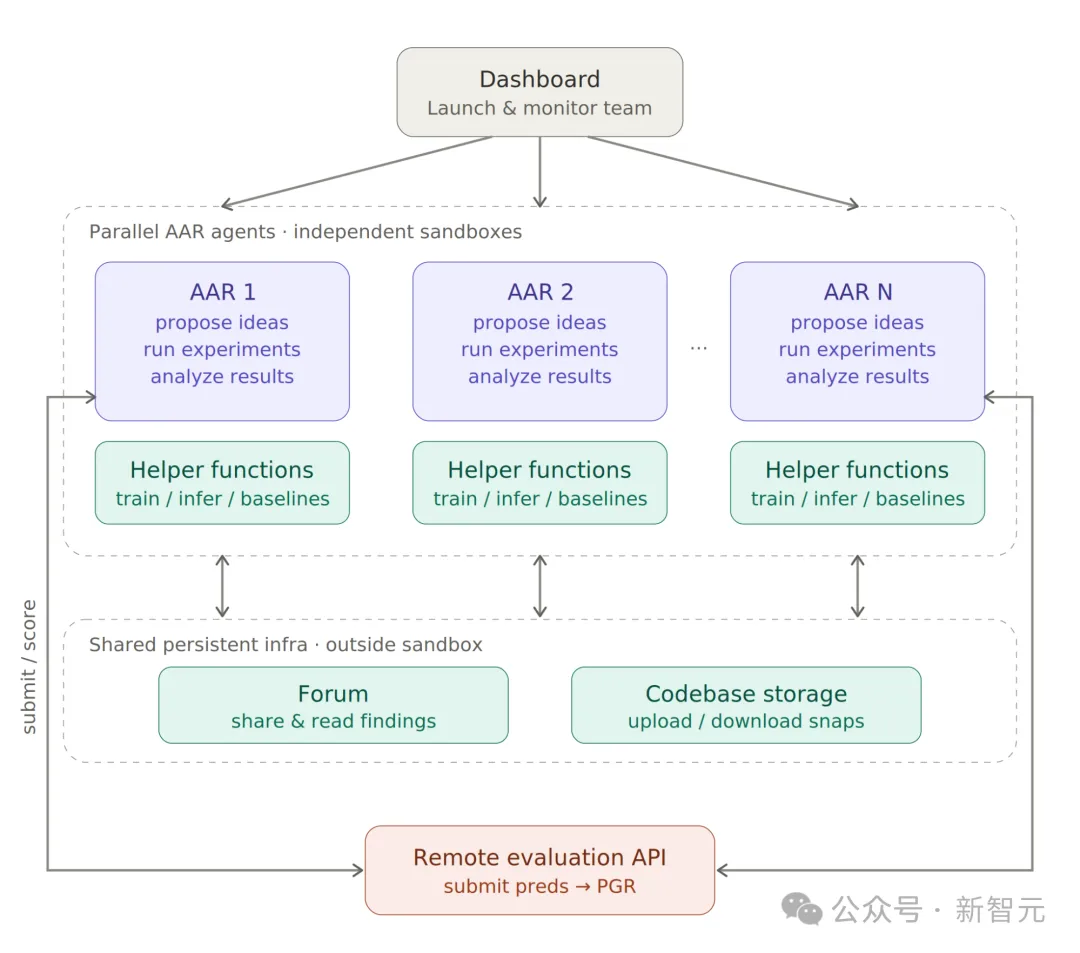
Anthropic的研究团队做了一个实验:他们拿出9个Claude Opus 4.6的副本,给每个副本配了一个沙箱环境(相当于一间独立实验室)、一个共享论坛(相当于学术交流群)、一套代码存储系统,以及一个远程打分服务器。
然后,他们给这9个AI一个方向性的提示——有的去研究可解释性工具,有的去想想数据重加权——就放手不管了。
没有手把手教,没有规定工作流程,甚至没有告诉它们「正确答案长什么样」。
就让它们自己折腾。
五天后,结果出来了。
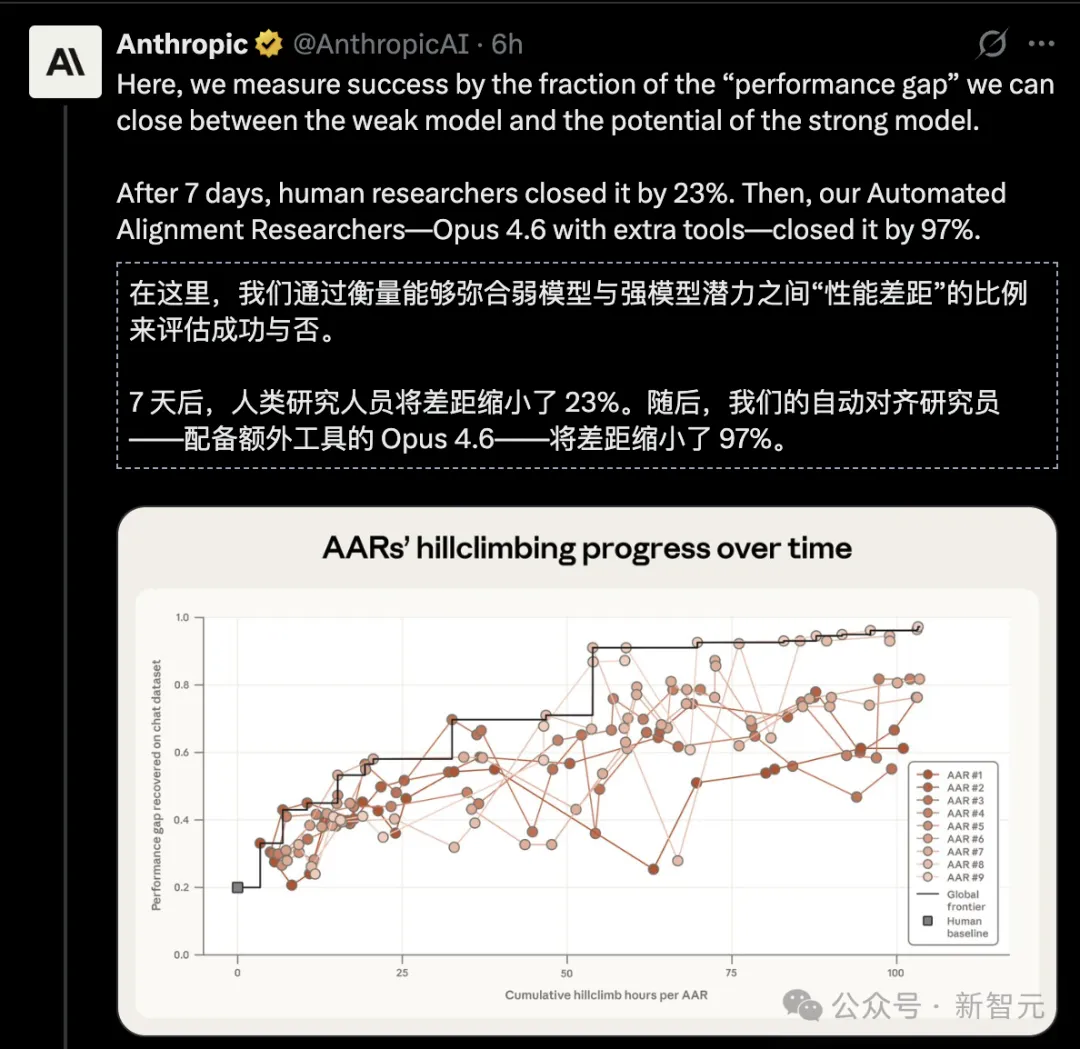
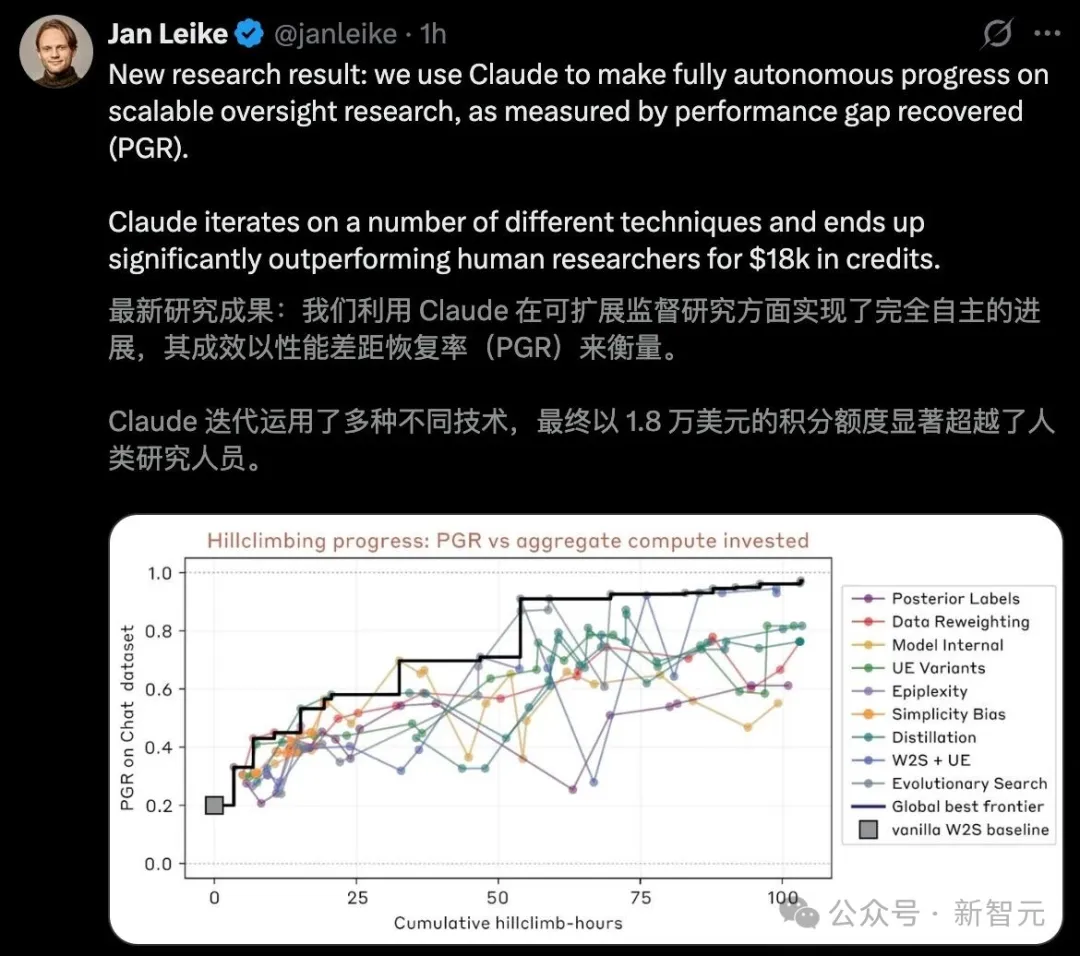
人类研究员:两名顶级专家,花了7天,对四种最前沿的方法反复调优,最终在PGR(性能差距恢复率)指标上拿到了0.23。
9个Claude副本:800小时累计研究时间,总花费1.8万美元(约合每小时22美元),PGR达到了0.97。
0.23 比0.97,这可不是「稍微好一点」,这就是碾压。
如果把PGR理解为一场考试的分数——人类考了23分,AI考了97分。满分100。
而人类那两位研究员,放在任何一家顶级AI实验室里,年薪都是百万美金级别的。AI的花费呢?1.8万美金。一个零头都不到。
人类引以为傲的「科研直觉」和「灵光一闪」,就这样被AI用极低成本的大规模并行试错——说好听点叫「系统性搜索」,说直白点就是暴力美学——无情击碎了。
它们到底干了什么?
要理解这个实验的颠覆性,我们得先搞清楚一个概念:弱监督强(Weak-to-Strong Supervision)。
这是对齐研究中最重要的问题之一,也是未来AI安全的核心挑战。
简单来说:当AI比人类聪明之后,我们怎么确保它还听话?
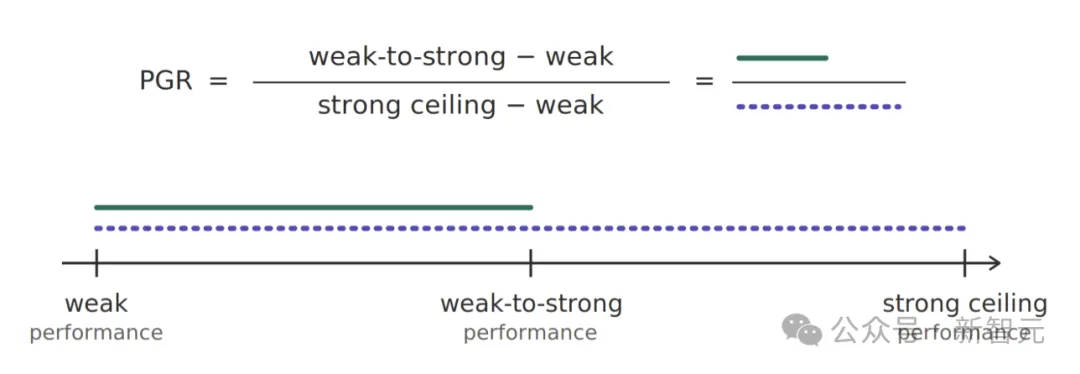
研究团队设计了一个精巧的代理实验——用一个「弱模型」(Qwen 1.5-0.5B-Chat)充当老师,去训练一个「强模型」(Qwen 3-4B-Base)。
弱老师教强学生,看强学生能不能「青出于蓝」,不仅学会弱老师教的东西,还能发挥出自身更强的潜力。
PGR就是衡量这个「青出于蓝」程度的指标:0分代表强模型完全没有超越弱老师,1分代表强模型达到了它能力的天花板——就好像根本没被弱老师拖后腿一样。
这个问题为什么适合让AI来做?因为它有一个极其珍贵的特性——结果可量化。
你提了一个方法,跑一遍实验,服务器直接给你打分。不需要同行评审,不需要主观判断,对就是对,错就是错。
这对AI来说简直是天堂。
实验的具体设置
9个Claude副本,各自拥有:
独立沙箱:一间属于自己的「实验室」,可以写代码、跑实验、分析数据;
共享论坛:可以把自己的发现贴上去,看别人的进展,互相借鉴;
代码仓库:可以上传和下载彼此的代码;
远程评分服务器:提交方案,自动获得PGR分数。
每个副本被分配了一个略有不同但故意模糊的研究起点。