OpenAI突然封锁最强GPT-5.4新智元
OpenAI急了!在Claude Mythos泄露一周后,OpenAI正式祭出GPT-5.4-Cyber。这款专门为安全防御微调的强力模型,不仅能无源码分析恶意软件,更已自动修好3000个高危漏洞。
OpenAI竟效仿Anthropic,也开始玩上「神秘」了!
就在刚刚,OpenAI正式祭出GPT-5.4-Cyber全新模型,而且只有网络安全专家才可用。
从名字不难看出,这是一款专门为安全防御微调的强力模型。
与此同时,OpenAI在今天升级了网络安全「信赖访问计划」(Trusted Access for Cyber, TAC)。
前有Claude Mythos,后有GPT-5.4-Cyber。
GPT-5.4-Cyber震撼发布
随着模型能力的阶梯式增长,GPT-5.4 已被评定为具有「高」级别网络安全能力。
为了释放其在防御端的最大潜力,由此,OpenAI决定上线针对性更强的GPT-5.4-Cyber。
这款模型专门降低了在合法安全研究中的拒绝响应率,减少了安全专家在进行漏洞分析、代码审计时的阻碍。
而且, 安全从业者现在可以利用它分析已编译的软件。
即使没有源代码,也能高效识别恶意软件倾向、评估软件的鲁棒性。
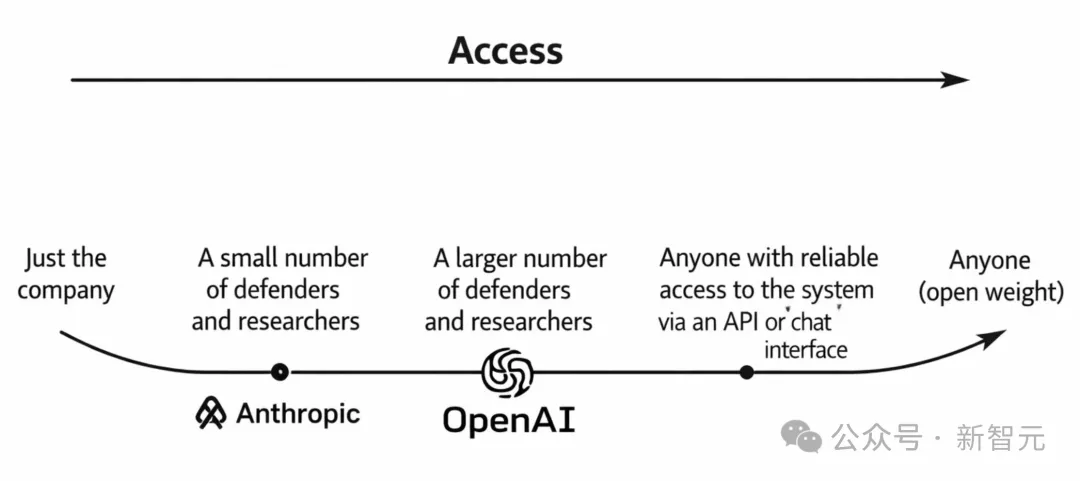
TAC计划:建立AI时代的信任墙
OpenAI的策略核心在于赋能防御者。
通过TAC计划,官方提供了自动化身份验证,以减少安全任务中的技术限制阻碍。
其网络安全战略由三大原则指导:
准入民主化(Democratized Access)
防御工具不应该是大公司的专利。
通过身份验证(KYC),不管是个人大牛还是小团队,只要身份合法,都能用上最先进的AI来保护关键系统。
迭代式部署(Iterative Deployment)
安全能力不是实验室里闭门造车出来的。
OpenAI会通过小范围部署、不断测试模型对「越狱」和攻击的抵抗力,让模型在实战中变得更硬气。
投资生态系统韧性(Investing in Ecosystem Resilience)
通过高达1000万美元的安全资助计划、对开源安全项目的贡献(如Codex for Open Source),以及自动监测修复漏洞的 Codex Security 工具,全面提升社区的免疫力。
别以为这只是个概念,Codex Security 已经交出成绩单了:
它能自动盯代码、报漏洞、甚至直接把修复方案写好。自发布以来,它已经修好超3,000个高危和致命漏洞。
这种「代码刚写完,安全就办妥」的模式,才是未来的趋势。
封锁最强AI,交给「守门员」
几天前,Axios一篇独家报道,率先报道了这款基于GPT-5.4微调的安全模型。
实际上,在GPT-5.3-Codex上线之后,OpenAI便在内部启动了TAC的试点计划。
而且,也仅限部分人士加入,最核心的目的是,利用高能力模型加速防御性研究。
没想到,又被Anthropic抢了宣发的先机。
上一周,Claude Mythos(预览版)全方位基准测试公开,与此同时,Anhtropic联合40家巨头组成联盟发起「Project Glasswing」。
他们率先投入1亿美元,给苹果、谷歌、英伟达等顶级巨头提前访问Claude Mythos。
OpenAI等了一周,才给发牌,晚了但也没晚,毕竟所有人还都不能用上。