中国具身模型狂揽全球第一量子位
还得是这届00后,强得可怕!一出手,具身智能就被“整顿”得底朝天。
当别人还在Sim2Real打转时,这支00后带队的灵初智能,已经开始用近10万小时人类数据暴力拆解。
这个数字就是放到整个行业里看,也是遥遥领先。
毕竟目前人类操作数据集大多还都集中在几千到几万小时量级,最大的也不过是英伟达的EgoScale,包含2万小时人类第一视角视频数据。
灵初这次直接上了个新台阶,10万+数据,其中1000小时还开源。
而且发布形式也够潮——直播show time~
AI博主弗兰克和灵初智能的00后联合创始人陈源培,直接手把手给你剖析的那种。(techblog指路:https://www.psibot.ai/from-human-skill-to-robotic-mastery/)
言而总之,整场直播我们复盘下来,就讲两件事:给具身智能喂什么吃、让具身智能长什么样的脑子。
说人话就是,灵初给的,是一条与众不同的务实路径——
不整虚的,直接对齐人类数据,再用Psi-R2和Psi-W0双系统架构平稳落地具体场景。
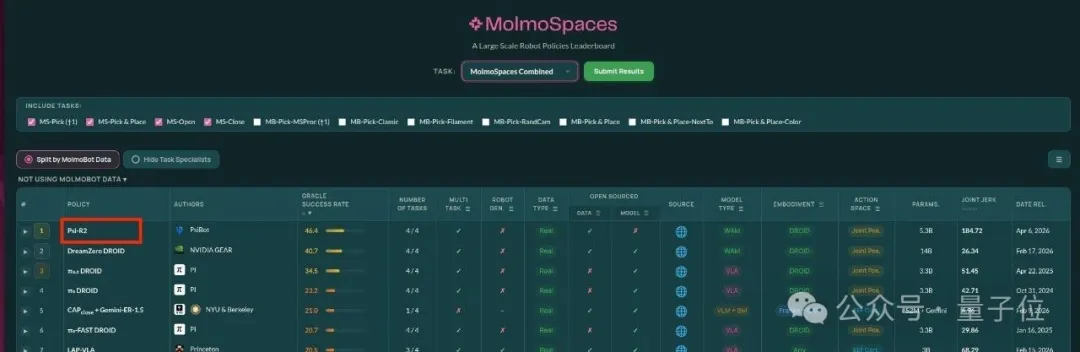
结果也很直观,灵初Psi-R2迅速登顶MolmoSpace榜单。
MolmoSpace由美国艾伦人工智能研究所(AllenAI)发起,是全球具身智能领域权威基准评测平台,NVIDIA、PI等全球顶尖团队均参与本次评测。
而灵初Psi-R2在评测中一举超越PI、DreamZero等国际知名模型,表现也显著优于其他基线模型,妥妥的行业第一梯队。
在成功率这块,也比同类VLA模型要高出近10倍。
情况就是这么个情况,灵初一来就整了个大活,具身智能终于迎来首个直接能用的大规模人类手部操作全模态数据集。
下面就让我们回到直播间现场,一一复盘拆解。
10万小时,让具身智能吃个顶饱
“为啥偏偏具身智能会数据荒?”弗兰克化身观众嘴替,率先给出这句经典灵魂拷问。
要回答这个问题,首先需要厘清一点,具身智能和自动驾驶、大语言模型这些AI领域存在原生的数据差异。
后者基于现实场景和互联网,长期积累沉淀形成了海量存量数据,然后通过简单粗暴的算力Scaling law就能实现性能稳步提升。
但具身智能则截然不同,物理世界复杂的情况让它几乎没有可用的成熟数据集,也很难像互联网产品那样边用边攒数据。
可以说,影响具身智能发展的关键之一就是数据卡脖子。
那咋办呢?以灵初在内的具身智能公司纷纷将目光投向人类数据。
仿真数据还需要迁移处理,才能在真实机器人上使用,但人类数据就是最优秀的参考对象,数据量大而且质量高。
但事实上,这里也同样存在一个无法忽视的问题:人类和机器人之间存在本体差异(embodiment gap)。
直接复用显然不行,机器人必定会出现运动学结构、动力学特性不匹配种种问题。
其次,现有的人类数据要直接给到预训练,也是万万不行的。因为要么都是些小规模开源数据,要么就是网络上一些低质量的第一人称视频。
但除去人类数据,也几乎没有其它更好的路径可走。灵初给出的判断是:
具身智能要想面向真实商业化场景落地,纯人类数据训练是必要的。
一方面,使用人类数据能够让机器人抢先学习到人类一线的标准作业流程(SOP),而这些都是得到商业实际验证过的,即拿即用且行之有效。
换言之,真实场景的无缝衔接能够将数据成本降至最低,比如人类的触觉数据收集成本,就仅为机器人的1/10以下。
另一方面,人类数据的SOP也可以使操作速度达到机械臂物理运动上限(如1200),远超遥操作可达的800,也更适配商业工厂的高节拍要求。
所以灵初最终选择了人类数据,并造出了首个可用于预训练的大规模人类操作数据集。
其中,在人类数据和机器人数据的融合处理中,灵初遵循的是一条化繁为简的思路:Raw Data In,Raw Data Out(原生数据进,原生数据出)。
舍弃人工设计的复杂数据处理,直接进行人类关节与机器人本体的运动学对齐,让模型在海量数据中自行探索。另外,Auto Labeling也会替代人工进行数据质检和标注,最后再交由人工审核。
最终模型预训练使用的数据集将包括真机数据(5417小时)和人类数据(95472小时)两部分,总计10万小时数据。
目前其中1000小时已开源,到年底整个数据集还将Scaling到百万量级。
具体来讲,人类数据包括灵初自研外骨骼手套采集数据与裸手操作数据,覆盖294种场景、4821种任务与1382种物体。
至于为什么要强调触觉数据呢?归根结底,还是为了更好地弥补人机之间的embodiment gap。
虽然人类与机器人在多个方面差异明显,但二者在接触信号上却保持了惊人的高度一致,能够有效补偿动力学差异,以及在显著提升世界模型能力的同时,还能更好地预测机器人与物体之间的交互情况。
这样一整套高质量数据预训练下来,机器人的泛化能力、长流程操作能力和操作精度都会有所突破,后续也仅仅只需要不到100条轨迹的真机数据就能完成微调。
另外值得关注的是,灵初在此期间,还发现了另一处华点:
数据信噪比才是决定人类数据能否有效支撑预训练的核心因素。低信噪比的数据甚至还会起到反作用。
如果要想判断数据信噪比,可以从两方面看:
1、数据集分布:操作任务多样性>物体多样性>>场景多样性。
泛化能力其实是模型最难学会的能力之一,但如果在预训练阶段可以见到更多任务和操作对象,自然而然模型接手新任务速度就越快。
2、感知模态:精准3D位姿>>触觉模态>2D图像特征。
在全模态信息中,人手全域3D位姿追踪是2D到3D模型转化的关键,也和机器人动力学特性匹配度最高。
简单来说,灵初认为无论是精准采集的可复现数据,还是舍弃部分精度的粗糙泛化数据,都缺一不可。