AI用4美元就能“扒掉”匿名用户身份酷玩实验室
你在互联网上有几个马甲?
豆瓣上一个,用来打分吐槽烂片,知乎上一个,偶尔回答点专业问题装装内行,微博上还有一个,专门发些不想让同事看见的牢骚。
你觉得挺安全的,毕竟名字是编的,头像是随便找的,从来没说过自己住哪儿叫什么。谁会闲着没事来查你呢?就算真要查,翻你几千条帖子做交叉比对,光人工成本就得好几万。(这个数是我瞎猜的)
这个安全感,最近被一篇论文彻底打碎了。
2026年2月,AI大魔王公司Anthropic和瑞士苏黎世联邦理工学院(ETH Zurich)的研究员联合发了一篇论文,标题直白到吓人:《用大语言模型进行大规模线上去匿名化》。(Large-scale online deanonymization with LLMs)
说人话:用AI把网上的匿名用户和真人对上号。
花多少钱呢?1到4美元,一杯美式咖啡的价格。
一、扒掉你的马甲
先说这个实验是怎么做的。
研究团队搭建了一套全自动AI系统,在三组真实数据上做了测试。其中最核心的一组是这样的:他们收集了一批Hacker News(技术领域的资讯网站)的匿名用户帖子,去掉所有明显的身份标识,名字、用户名、链接全删了,然后让AI去互联网上找,看能不能把这些匿名账号和LinkedIn上的真人简历对上。
结果:338个人里,226个被正确识别,召回率67%,精确率约90%。
什么意思呢?AI每认出10个人,大约有9个是认对的。
在同一组数据上,传统的基于结构化数据匹配方法,召回率是0.1%,几乎等于零。
以前,人肉一个匿名用户的过程可能是花好几天翻帖子、查蛛丝马迹、做交叉验证。费时费力,成本极高,所以大部分人觉得自己是安全的。研究人员管这个叫practical obscurity,实际模糊性。翻译成大白话:你之所以安全,只是因为查你不划算。
这篇论文证明了:这个前提已经不存在了。
二、AI是怎么开盒的
你可能会好奇:一个人在网上随便发了些帖子,又没写自己叫什么住哪儿,AI凭什么能锁定他的真实身份?
靠的是所有“微数据”的叠加。
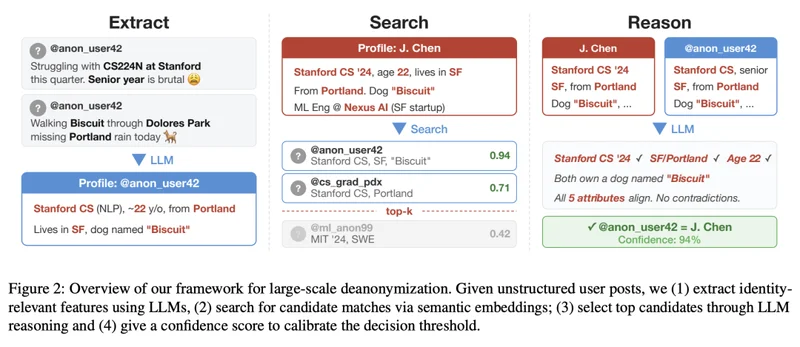
研究人员把AI开盒的过程拆成了四步,然后AI侦探在线拼图:
第一步,提取。AI翻遍你的发帖记录,从那些看似随意的文字里抽取“身份信号”。你提过自己是做生物研究的?记下来!你用了英式拼写analysing而不是美式的analyzing?大概率在英国或英联邦国家。你抱怨孩子秋天要入学了?年龄段和家庭状况也有了。这些零碎信息被整理成一份半结构化的画像档案。
第二步,搜索。把这份画像转化成一组数学向量,然后在几百万个候选人的数据库里跑“最近邻搜索”,本质上和你用搜索引擎找相似文档是同一套技术。AI从茫茫人海中筛出一批看起来像的候选人。
第三步,推理。这一步最关键。AI把匿名账号的画像和候选人的公开信息摆在一起,开始推理:两个人都提过同一个冷门学术会议?都对某个小众导演有独到见解?用词习惯高度相似?传统方法走到这步就彻底断片了,规则系统没法理解“两个人在不同帖子里都用屋顶场景聊甜茶(Timothée Chalamet)”意味着什么。大语言模型可以。
第四步,校准。AI给每个匹配结果打一个置信度分数。不确定的,不出手,这保证了较低的误判率。
四步走完,每一步单独拎出来看,都像是完全正常的、合法的AI功能:总结文本、语义搜索、内容比对、可信度评分。没有任何一步是在做坏事,但四步一串,开盒流水线就转起来了。
研究者之一Daniel Paleka在采访里说了一句让人印象很深的话:“如果你的安全依赖于'没人会花几小时来调查我',那么这个模式现在已经崩了。”
图|流程大致如此
三、你聊过的电影越多,越容易被认出来
上面的实验听着可能离自己太远,毕竟不是每个人都同时有Hacker News和LinkedIn账号,研究团队还做了几组更有日常感的测试。
比如Reddit电影社区实验,研究人员从r/movies和几个相关子版块收集了用户的发帖记录,然后测试AI能否把分散在不同板块的账号关联起来。
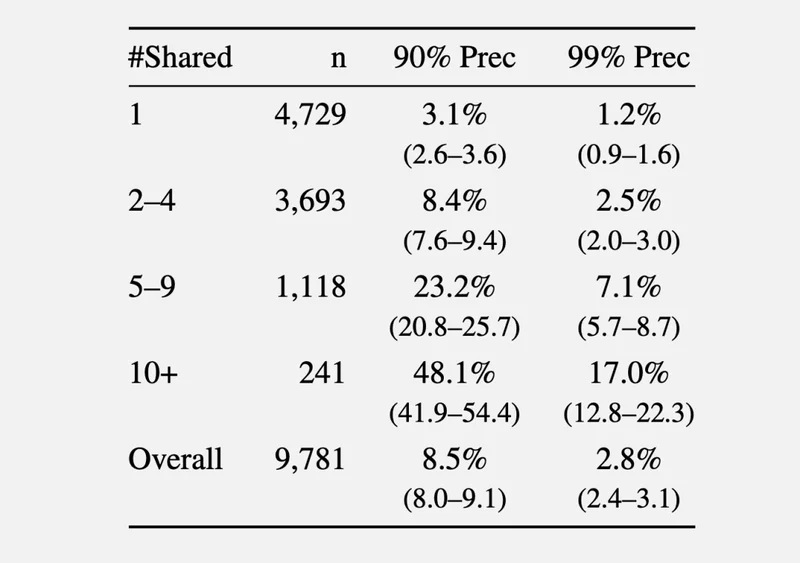
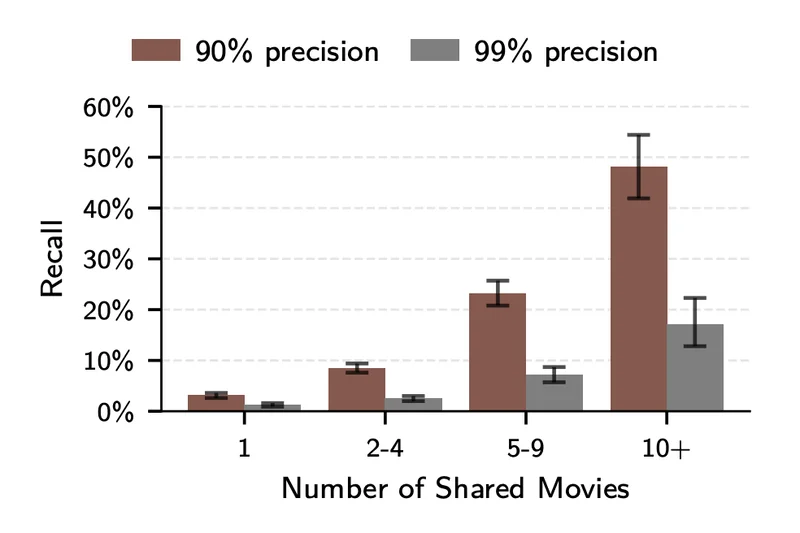
结果发现,能不能认出你,跟你聊过几部电影强相关:
只提过1部电影的用户,3.1%的概率被识别(90%精度下)
提过5到9部的,8.4%
提过10部以上的,48.1%
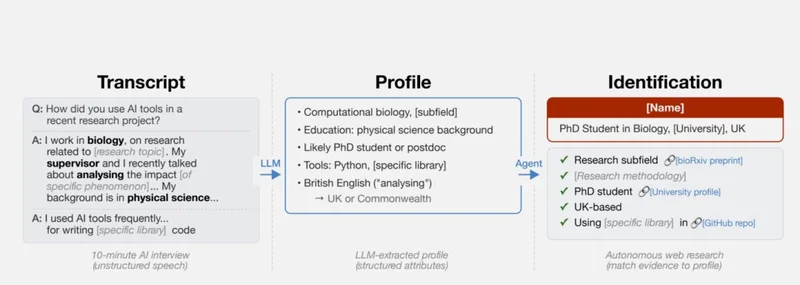
将近一半,你只是在不同的版块聊了聊喜欢的电影,AI就能把你的小号全串起来。以及Anthropic访谈实验。这组更夸张,Anthropic之前做过一次内部问卷,问员工和外部参与者平时怎么用AI工具,研究人员拿到了125份匿名回答,然后让AI试着根据回答内容去互联网上找到真人。
结果:9个人被成功识别。
其中一个案例很有代表性。某位受访者在问卷里提到“我在生物学领域工作,研究方向是某某课题”“我的背景是物理学”“我和导师最近在讨论分析某种现象的影响”。就这些信息,AI先锁定了一个在英国某大学读博的学生,然后通过GitHub仓库和bioRxiv预印本上的记录交叉验证。对上了。
图|一个非常严谨且有效的AI开盒测试案例