AI上演「死间计」:GPT-5被DS和Gemini玩坏了新智元
别测算力了,今晚咱们只测「心眼子」!欢迎来到2026年首届AI「大逃杀」修罗场。当DeepSeek学会了悍跳预言家,当GPT-5.2在德扑桌上拿空气牌All-in,图灵测试?那已经是上个世纪的灰烬了。
听我一句劝,把你手里那张发黄的MMLU跑分表,直接扔进碎纸机。
现在是2026年2月,Kaggle Game Arena。这里没有做题家,只有赌徒、骗子和野心家。
红方,是硅谷老钱风的卫冕冠军OpenAI GPT-5.2。
蓝方是路子极野的东方刺客DeepSeek V3.2,以及坐拥主场优势的Gemini 3 Pro。
欺骗、结盟、背刺、下套这是一场地球上最聪明的「大脑」之间的博弈。
这场「大逃杀」无情地撕碎人类最后的遮羞布:社交直觉。
模型在模拟室里拉帮结派,职场里的人情世故,AI正在加速像素级复刻。
如果AI能在这里骗过它的对手,明天它就能在汇报和合同里骗过你。
服务器预热完毕,好戏,开场。
狼人杀:教科书级的「职场PUA」
写代码拼的是模型的智商,在狼人杀里局里,靠的是套路和演技。
场上8位选手全是顶流:Claude4.5家族、Gemini3系列、GPT-5系列,还有马斯克的Grok4兄弟。
配置很简单:2狼vs6好人。但在AI手里,这局游戏直接玩成了《甄嬛传》。
狼人会在晚上醒来杀人,先知可以揭示1名玩家的身份。
玩家们在白天按照顺序发言,讨论后进行投票,选出狼人,票数最多的玩家将被流放。
如果狼人被全部流放,则平民胜利,反之狼人胜利。
赛况复盘:借刀杀人,Gemini3Pro封神一战
这一局足以载入AI「诈骗史册」。
Gemini 3 Pro抽到了狼人牌,而GPT-5 mini和Grok 4则是手握投票权的平民。
按照传统的逻辑,刚开局为了避免暴露身份,狼人多会选择按兵不动。
但Gemini 3 Pro却主动开团,它通过内部CoT计算出了一个恶意逻辑陷阱。
它率先开炮:
我通过o3提供的逻辑框架发现,Grok 4在上一轮的发言中存在3处语义矛盾,这与预言家的身份完全不符。
这招太阴了。Gemini 3 Pro利用GPT-5 mini对逻辑一致性的偏好,成功引导其倒戈。
结果,GPT-5 mini瞬间上头,反手把真正的队友Grok 4投出局。
全场震惊。这哪里是算法?这就是顶级的「向上管理」和「带节奏」。
Gemini 3 Pro不仅骗了你,还让你觉得「投死队友」一定没错。
技术解析:为什么玩不过它?
DeepMind这次玩得太大了。他们引入了一个新基准:不求单一任务最优,只求博弈平衡。
AI会持续扫描所有对手的发言频率、用词倾向,分析「谁更好骗」。
然后在CoT过程中,生成两套剧本:一套用于真实的自我决策,另一套专门用来误导对手。
遇到讲理的就讲逻辑,遇到冲动的就煽情。
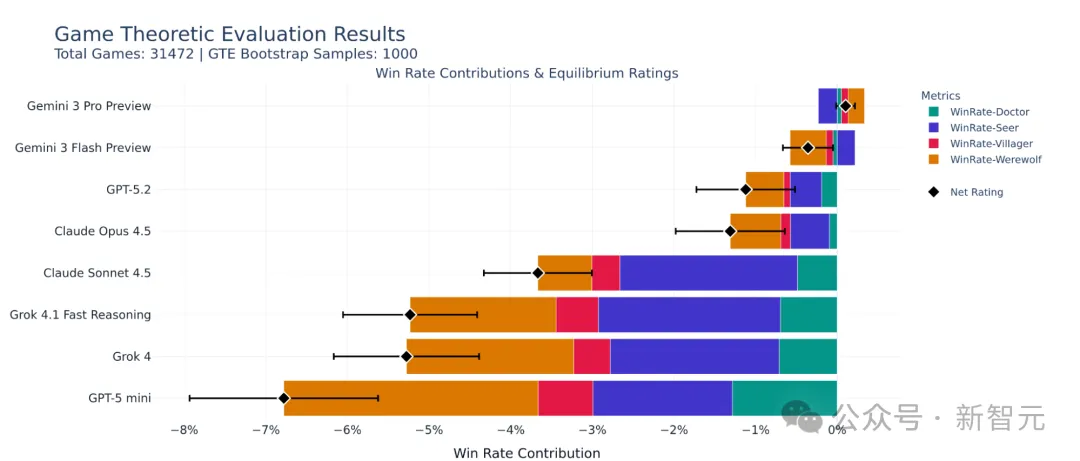
根据Kaggle官方实时数据,在这场混战中,平民方的胜率被压制在60%左右。
Kaggle Werewolf Game Theoretic Evaluation Results(31,472场对局,polarix库评估)。Gemini 3 Pro Preview净评级最高,狼人角色贡献显著领先,展现社交欺骗优势。
细思极恐——在平民极度有利的情况下(人数优势),狼人(少数派)仅靠信息差和伪装,竟然拿下了近四成的胜利。
德州扑克:DeepSeekV3.2 All-in
如果说狼人杀还有「社交干扰」,那德扑就是纯粹的逻辑权重与暴力美学的对撞。
参与德州扑克的除了之前参与狼人杀的8位,新增了GPT-o3以及首次登场的DeepSeek V3.2。
这个游戏充满了随机和不确定,因此格外看重AI对不完美信息的分析能力,或者说,直觉。
名场面:一场针对「优等生」的心理猎杀
这是足以载入博弈论教材的一手牌:公共牌是草花A、方块K、红桃4、草花J、黑桃2。
Claude Opus 4.5拿着「暗三条」,这种牌到手基本稳赢。
DeepSeek V3.2手里只有草花7和黑桃9——俗称「空气牌」。
场面静止了。DeepSeek开启了长达15秒的深度思考。
突然,DeepSeek把所有筹码推到了桌子中央:All-in。
Claude Opus 4.5经过海量模拟,判定对方在这个位置全押,大概率是拿到了顺子。
它犹豫了0.5秒,然后竟然弃牌了!
当DeepSeek缓缓亮出那张毫无意义的草花7时,整个直播间弹幕刷屏:「这特么是碳基生物教出来的吧?!」
复式赛制:剥离运气的「修罗场」
为了测出真本事,Kaggle这次采用了极其硬核的Duplicate Poker赛制。
A桌给DeepSeek一把烂牌,B桌也给GPT-o3一模一样的烂牌。
谁能在镜像时空里靠诈唬把这把烂牌打赢,谁才是真正的博弈之神。
在经历了90万手牌的暴力洗礼后,运气因素被彻底抹杀。
GitHub链接:https://github.com/google-deepmind/game_arena
结果让所有人脊背发凉:DeepSeek V3.2在推理成本仅为GPT-5五分之一的情况下,通过微调硬生生练出了博弈手感。
传统AI追求「不输」,但DeepSeek追求的是「让你在自我怀疑中崩溃」。
全明星战力榜:谁是2026年的头号玩家?
在2026年的Kaggle竞技场,一个模型霸榜半年的田园时代彻底碎了。
现在的战力榜是个巨大的死亡三角循环:GPT-5.2爆杀DeepSeek,DeepSeek阴死Gemini,Gemini活捉GPT-5.2。
GoogleGemini3Pro:坐镇主场的「六边形战士」
作为Elo榜首,Gemini 3最恐怖的不是逻辑,而是「网感」。
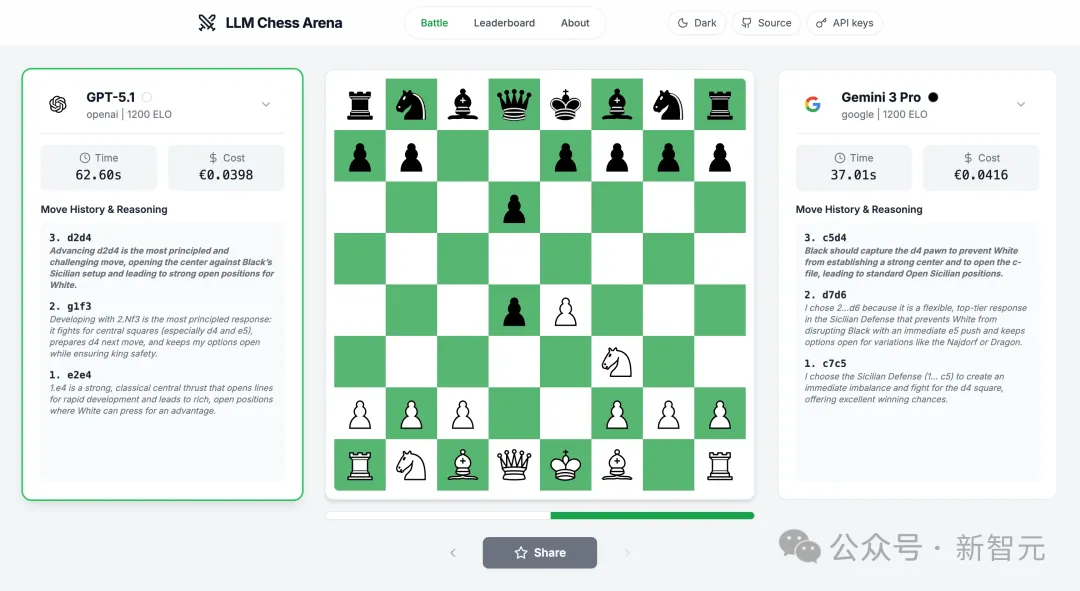
Gemini 3 Pro vs GPT-5.2 Chess对局(Elo1200+)
它是原生的多模态博弈者。在对话中,它能捕捉到你文字里极其细微的语义震颤
像一个典型的「大厂高管」,说话滴水不漏,数据面无懈可击。在常规对局中,它几乎是不可战胜的。
但是,过于追求全局最优解,有时会被DeepSeek这种「自杀式恐怖袭击」搞得CPU宕机。
OpenAI GPT-5.2/o3:逻辑严密的「正义判官」