50万行代码泄露:揭开Claude好用秘密华尔街日报
Anthropic的一次失误,意外揭开了Claude Code的底层秘密:它会像人一样主动整理记忆;子Agent并行模式让5个Agent成本接近1个。比技术更耐人寻味的,是Buddy——那只守在终端里的电子宠物。Anthropic用这个愚人节彩蛋传递了他们的产品哲学:工具不止是效率的延伸,也可以是情感的连接。
Claude Code 不是一个套了终端界面的 AI 聊天工具。
这件事,Anthropic 的工程师用一个失误证明了。
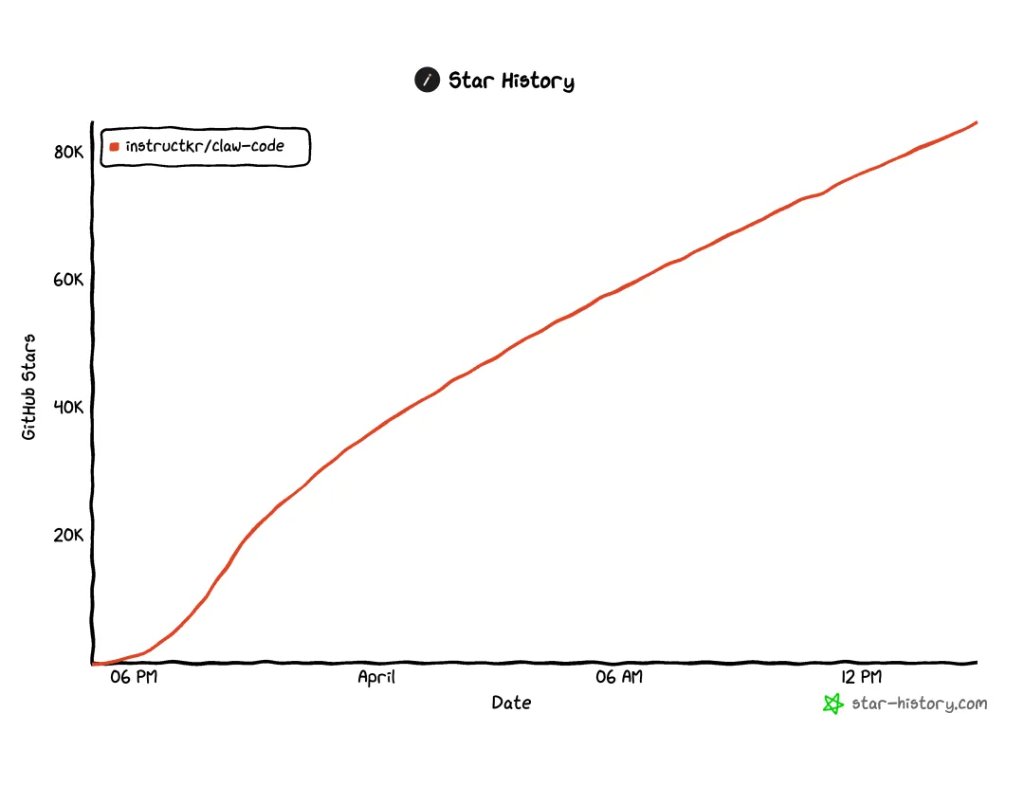
3 月 31 日,他们在发布 Claude Code v2.1.88 的时候,把一个本该留在内部的调试文件,打包进了公开的 npm 安装包。那个文件有 59.8 MB,里面是完整的、从未混淆过的 TypeScript 源代码,约 50 万行,将近 1900 个文件。
凌晨 4 点多,一位在 Solayer Labs 实习的工程师在 X 上发出发现,附上了直接可以下载的存档链接。这条帖子最终获得了近 1000 万次浏览。
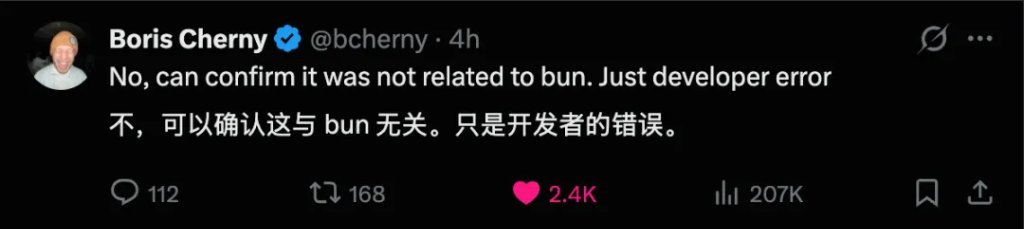
Claude Code 的负责人在 X 上回应:「这不是 Bun 相关的安全漏洞,没有用户数据泄漏,只是开发者的错误而已。」
这个解释没有问题。但他们没提到的是:这次泄漏让我们第一次看清楚,Claude Code 的底层到底是什么结构,以及为什么它在大多数用户群体里的口碑远超其他同类工具。
你在睡觉,模型也在做梦
这是这次代码泄漏事件里被讨论最多的内容之一。KAIROS,一个源代码里出现了超过 150 次的词,古希腊语,意思是「恰好的时机」。
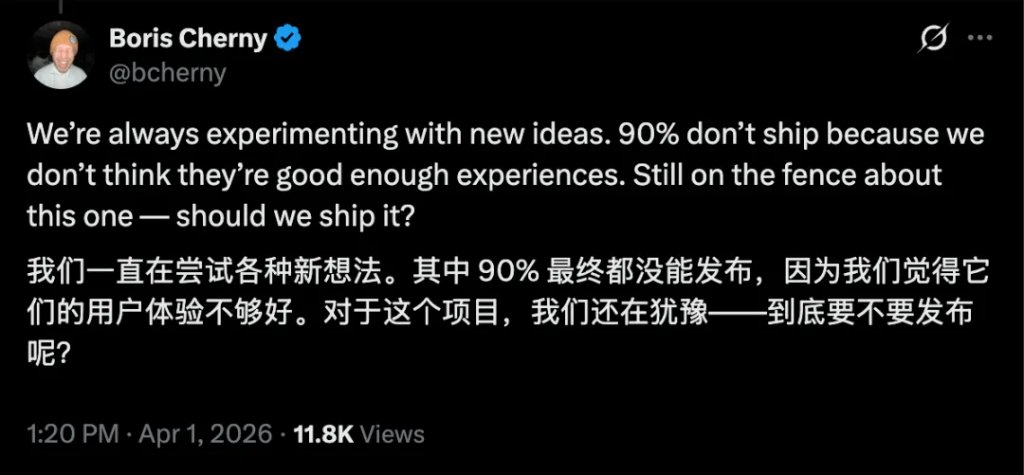
KAIROS 是一个还没有正式发布的功能,但从代码的完成度来看,可能马上就会全量发布。其负责人在 X 上回复网友询问时,提到这项功能还在犹豫要不要发布。
它代表的是一种「后台守护进程模式」,Claude Code 在我们不用它的时候,自动在后台运行,处理任务,整合记忆。
其中有一个叫 autoDream 的逻辑:当用户处于空闲状态时,agent 会执行「记忆整合」,合并分散的观察,清除相互矛盾的信息,把模糊的推断转化成确定的知识。
通俗来讲,当我们在睡眠的时候,大脑并不是完全休息下来,它会自动编排我们的记忆,保留那些重要的,丢掉可以忘记的。而如果睡眠不足,大脑就会记不住事情,不知道什么该记住,工作效率也会下降。
放在 Claude Code 上,对话太多, 上下文长度溢出,就增大出错概率。包括 OpenClaw 在内,这种命令行工具采用的方式都是 compact 压缩,但 compact 效率不够高,autodream 的优化就同时解决了上下文长度有限,和压缩会丢失信息两方面的问题。
这和今天大多数 AI 工具的运作方式完全不同。今天的 AI 工具大多是被动的,我们问它才答,不问它就沉默。
KAIROS 想做的是主动的,在我们离开的这段时间里,它把之前的任务状态捋清楚,自动更新用户角色、具体项目的记忆、工具偏好的记忆,以及主记忆文件,等我们再回来时直接生成一个整洁的起点。
在这次的泄漏事件之前,已经有网友在 Claude Code 能体验到。Claude 会在各个会话中记录每日对话日志,然后在夜间「做梦」,自动将我们的记忆整理成有用的笔记。
Claude Code 睡醒一觉后,回顾梦里做了些什么,更新了用户角色、主记忆等内容
5 个 Agent,成本约等于 1 个
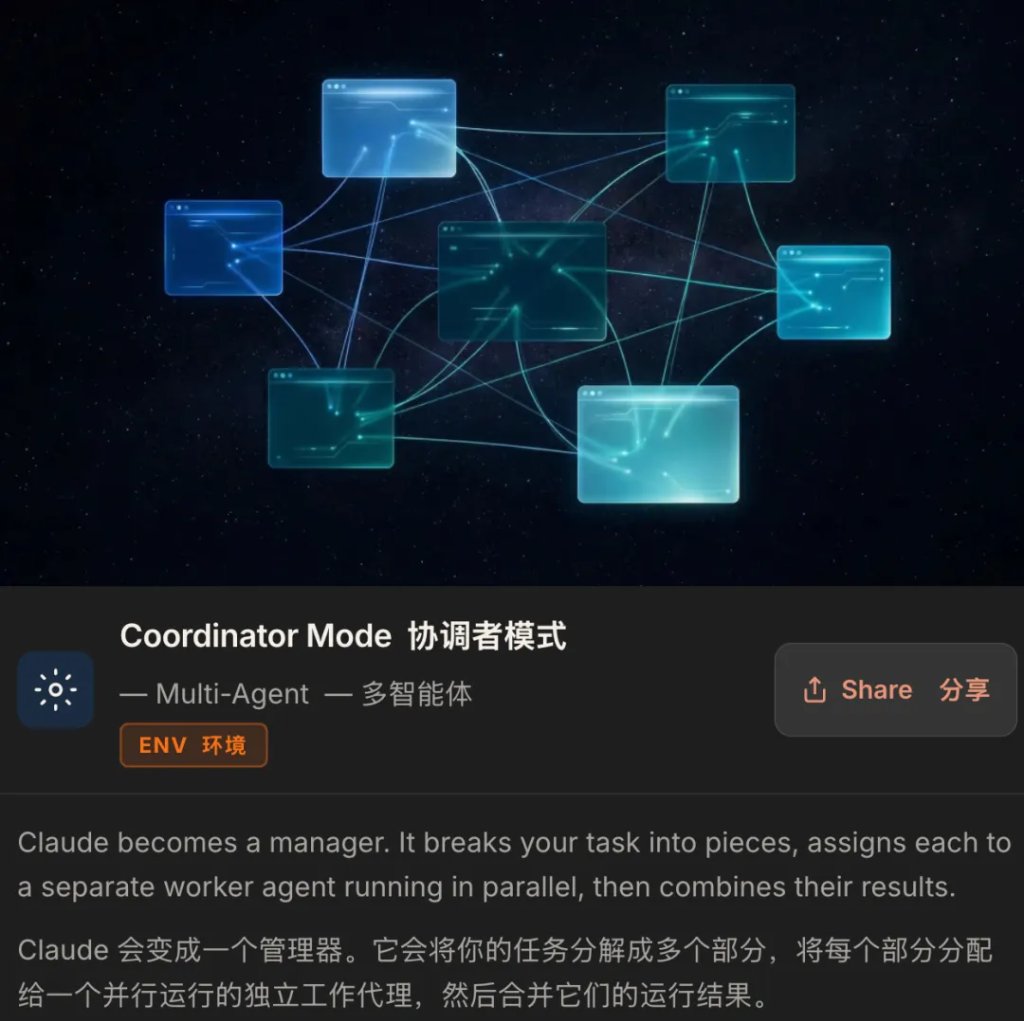
另一个让网友们讨论最多的设计是,subagent 的 fork 模式共享 prompt cache。
当 Claude Code 派生出一个子 agent,它会创建一份和父 agent 完全字节相同的上下文副本。Anthropic 的 API 会缓存这份上下文。所以派生 5 个 agent 并行工作,消耗的 token 成本接近于 1 个 agent 顺序工作,因为 5 个副本都命中了同一份缓存。
源代码里有三种子 agent 的运行模式:fork(继承父 agent 上下文,适合同一任务的并行分支)、teammate(在独立的终端窗格里运行,通过文件通信)、worktree(给每个 agent 一个独立的 git 工作树,互不干扰)。
这意味着我们可以让 Claude Code 同时跑:一个做安全审计,一个重构认证模块,一个写测试,一个更新文档,而由于 Claude Code 内部的缓存命中机制,所需要的费用,可能和按照顺序做一件事差不多。
大多数人觉得 Claude Code 不好用,大概是只把它当成单线程工具在用,而不是一个 Agent 调度平台。
这就像你雇了一个团队,却让他们排队一个一个干活,员工的能力没有被充分释放。