你听说过「世界模型」吗?Tony博客
让我从一个问题开始:
如果你让ChatGPT描述「一个人捡起一个装满水的玻璃杯」,它能写出一段优美的文字。
但如果你问它:「捡起这个杯子的时候,手指需要施加多少力,才不会把它捏碎?」
它……不知道。
这不是ChatGPT笨,而是因为大语言模型压根就没有被设计来理解「力」「重力」「材质」这些物理概念。它懂语言,但它活在一个没有重力的世界里。
而「世界模型」,正是为了解决这个问题而生的。
这篇文章,我想用最通俗的语言,跟大家聊聊这个还没有进入大众视野、但可能深刻改变未来十年的AI技术——世界模型(World Model)。
一、什么是「世界模型」?
先从一个小孩学走路说起。
一个两岁的孩子,从来没人教过他「如果我往前迈一步,脚会踩到地面,地面会给我一个反作用力,让我保持平衡」。没有人教过他牛顿第三定律。
但他学会走路了。
为什么?因为他在反复跌倒和站起来的过程中,大脑里悄悄构建出了一个「世界的运作规则」——地面是硬的,玩具是会滚的,水是往下流的,如果我推了桌子上的杯子,杯子会掉下去摔碎。
这个存在于大脑里的「世界运作规则」,就是世界模型(World Model)的核心概念。
AI的世界模型是什么
人工智能领域的世界模型,顾名思义,就是让AI也在自己的「脑子」里建立一套对物理世界的理解:
物体受到重力会往下掉。
两个固体不能同时占据同一个空间。
如果用力推一个轻的物体,它会飞出去;推一个重的物体,它可能纹丝不动。
玻璃杯受到超过它承受极限的压力,会碎。
听起来很基础对吗?是的,对人类来说太基础了。但对AI来说,这是一道巨大的技术鸿沟。
大语言模型(比如ChatGPT、Claude)是在互联网的文字上训练的。文字能告诉它「玻璃杯很脆」,但文字里没有「捏碎一个杯子需要多少牛顿的力」这种信息——因为没有人在写文章的时候去标注力学参数。
而世界模型,是在视频、传感器数据、机器人的实际操作记录上训练的——它看到了力和结果的对应关系,因此能学到真实的物理因果规律。
【一句话】 大语言模型懂「说话」,世界模型懂「做事」。
二、为什么现在这个时间点才出现?
世界模型这个概念,学术界讨论了很多年,为什么现在才突然变成了产业焦点?
因为三件事同时发生了。
第一件事:机器人和自动驾驶到了「最后一公里」的瓶颈
过去十年,机器人和自动驾驶的进步速度令人印象深刻。但大家逐渐发现,这些系统在「正常场景」里表现不错,一旦遇到从没见过的情况,就会犯低级错误。
比如自动驾驶汽车,在正常路况下开得很好,但遇到路面上有个纸板箱,或者一个骑自行车的老人做出一个奇怪的手势,它可能就不知道该怎么办了。
原因是什么?因为这类「边缘情况」(Edge Case)太多了,你不可能把所有情况都收集到真实数据里去训练。
而世界模型的解决思路是:让AI在虚拟世界里把这些罕见情况「演练」出来。一秒钟可以生成一万种从未在现实中出现的危险路况,让自动驾驶系统反复练习,直到它能应对。
第二件事:生成式AI的突破让「合成数据」的质量大幅提升
你可能用过AI生成的图片或者视频,质量越来越逼真。这个技术,恰好是世界模型需要的核心能力之一。
世界模型需要生成「物理上合理」的虚拟场景——不只是视觉上好看,而是里面的物体要按照正确的物理规律运动。现在的生成式AI技术,已经让这件事变成了可能。
第三件事:英伟达把这件事做成了工业级产品
英伟达在2025年初推出了Cosmos平台,把世界模型从学术研究变成了开发者可以直接用的工具。这就像是原来只有顶级科学家才能研究的东西,突然变成了任何工程师都能用的「零件」。
这是一个技术商业化的关键时刻。
三、世界模型能做什么?三个最重要的应用
应用一:训练机器人——让机器人先在「虚拟世界」里死一万次
这是世界模型最核心的应用场景,也是最让人兴奋的地方。
想象一下,你要训练一个机器人去工厂里组装电子零件。
传统的训练方式是:让真实的机器人一遍遍去尝试,成功了记录数据,失败了(比如零件掉了、螺丝拧坏了)也记录数据。这个过程慢,成本高,而且很多动作因为太危险、太昂贵,根本无法在真实环境里大量练习。
有了世界模型,训练流程变成了这样:
第一步:在虚拟世界里建立一个数字工厂,里面的零件、机械臂、螺丝,都有真实的物理属性(重量、硬度、摩擦系数)。
第二步:让机器人在这个虚拟工厂里练习,一天24小时、一秒钟演练数千次操作。摔了零件?虚拟世界里重来,不花一分钱。拧坏螺丝?系统自动记录这个失败,让机器人学习如何避免。
第三步:把虚拟世界学到的「经验」迁移到真实机器人上,让它直接开始工作。
这个过程,在行业里叫做「Sim-to-Real」(从模拟到现实)。
效果有多显著?以前训练一个能完成特定工厂任务的机器人需要几个月的真实数据收集,有了高质量的世界模型,可以压缩到几天甚至更短。
中国的做法:值得一提的是,中国在这个赛道走了一条独特的路。全国超过40个国家出资建设的「机器人训练营」正在密集运转——工人操控机器人每天反复练习叠衣服、搬货物、擦桌子,产生大量真实世界的操作数据。这是一种「用人海战术补数据」的策略,和英伟达用虚拟世界生成合成数据的路线形成了有趣的互补。
应用二:训练自动驾驶——模拟那些「不能发生」的事故
自动驾驶的训练难点,不在于正常路况,而在于极端情况。
如果要让自动驾驶系统学会处理「大雪封路+前方突然出现行人」这类复杂情况,你不可能真的去制造这种危险场景来收集数据。
世界模型的解决方案:在虚拟环境里,这类场景可以被无限次生成。
今天练习:大雾天能见度5米,前方突然有行人从停着的卡车后面冲出来。
明天练习:路面结冰,转弯时来了一辆逆行的摩托车。
后天练习:隧道里突然停电,照明全灭。
这些场景在现实中要么极度危险,要么极度罕见,根本无法大量收集真实数据。但在世界模型构建的虚拟环境里,可以随意生成,反复练习。
英伟达的Cosmos平台已经被奔驰、优步等汽车和出行公司采用。奔驰用它来给旗下不同车型快速生成自动驾驶训练数据——一款新车不需要真的上路跑几百万公里,虚拟环境里的数据就可以让它具备相当水平的驾驶能力。
应用三:工业数字孪生——工厂在投产前先「跑一遍」
这个应用可能离我们日常生活最远,但影响却可能最为深远。
想象一家汽车工厂要改造生产线,引入新的机械臂。传统流程是:设计方案→采购设备→安装→调试,发现问题了再修改,再调试。这个过程动辄半年一年,成本极高。
有了世界模型构建的数字孪生工厂:
在开始采购任何真实设备之前,先在虚拟工厂里把所有机械臂、传送带、工人动线全部模拟一遍。
发现机械臂A和机械臂B会在某个特定时刻碰撞?虚拟环境里修改,不花一分钱。
发现某个传送带速度设置会导致产品积压?马上调整。
把虚拟工厂调优到完美,再去真实世界实施。
丰田、宝马等汽车巨头,已经在用这套方法。宝马在匈牙利建设新工厂时,整个工厂在真实施工之前,先在数字世界里完整运行了一遍。
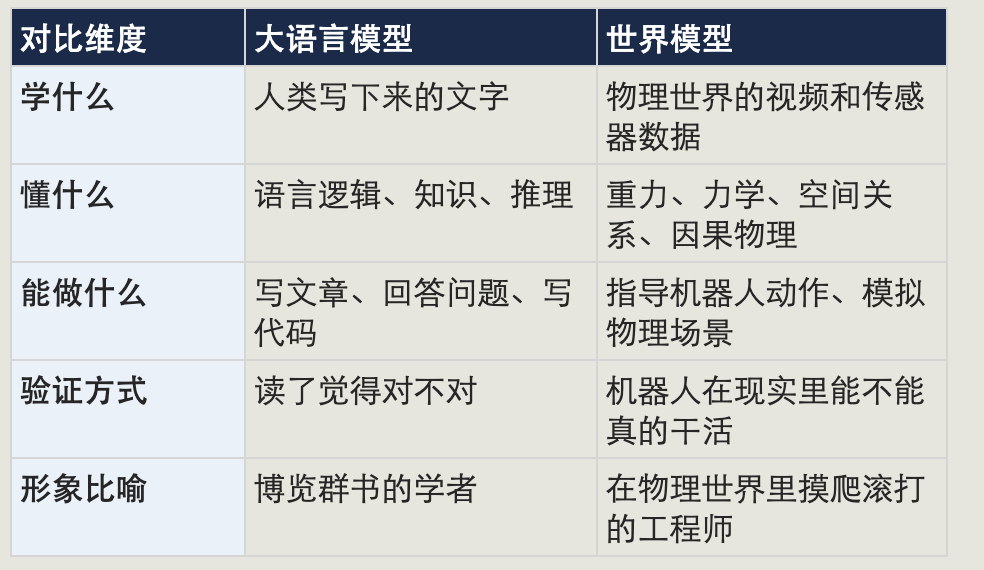
四、世界模型和大语言模型,到底有什么本质区别?
很多人看到「世界模型」这个词,第一反应是:「这不就是ChatGPT再升级一下吗?」
不是的。它们是两种根本不同的东西。用一个比喻来解释:
这里有一个关键点值得强调:大语言模型的进步让机器「能说会道」,而世界模型的进步让机器「能做实事」。
过去几年,AI最让人印象深刻的是它「说」得有多好。未来几年,AI最让人震惊的将是它「做」得有多好。
而那个转折点,就是世界模型开始成熟的时刻。
五、这件事有多难?为什么说它比大语言模型更难?
如果世界模型这么重要,为什么大家不早点做?
因为它比大语言模型难太多了。