什么是神经网络?数学模型
人工神经网络(Artificial Neural Network,ANN),简称神经网络,是一种受人脑启发的机器学习算法。这种算法擅长解决传统计算机难以处理的复杂问题,例如图像识别、自然语言处理和机器翻译。
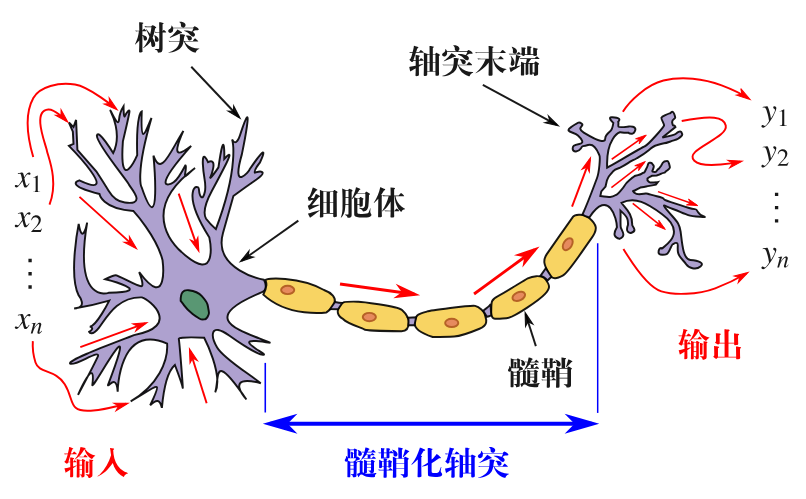
图 1: 神经元信号传输示意图
神经网络最初试图模仿生物神经元的结构(图 1),如轴突、突触和树突的连接方式,但后来更注重通过实验优化来建模非线性关系和复杂模式[1]。
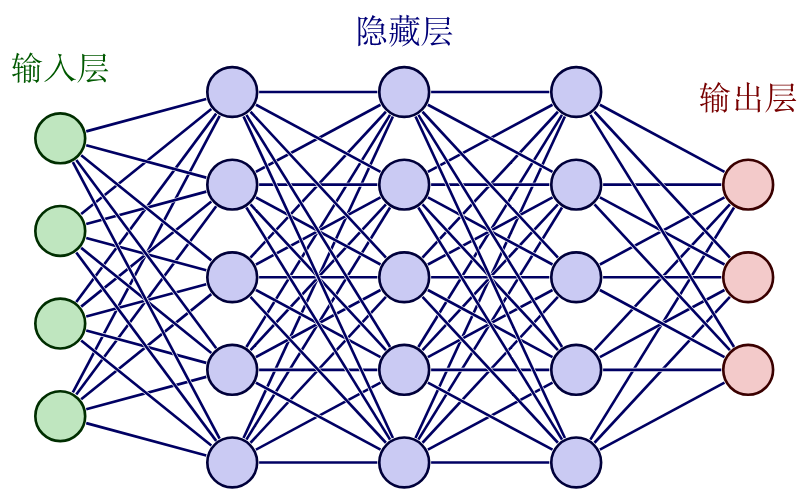
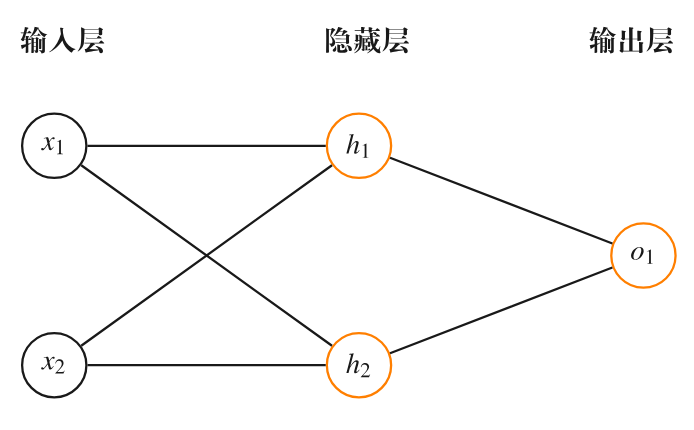
图 2: 一个神经网络示意图
神经网络(图 2)由相互连接的节点(称为神经元)组成,这些神经元分层排列,每个神经元接收输入(如外部数据特征或其他神经元的输出)、进行处理,并将输出传输给其他神经元。神经元之间的连接具有权重,表示信号传递的强度;在训练过程中,这些权重会被调整,以提升网络在特定任务上的表现,从而实现模式识别和预测功能。
尽管神经网络的核心计算单元“神经元”结构相对简单,但大量神经元通过特定方式连接成的网络,却能展现出令人惊叹的复杂信息处理能力。本文将深入剖析神经网络的基本组成单元——神经元,阐述其数学工作原理,并展示如何将神经元组织成多层网络结构,并最终通过“训练”这一过程,使网络能够从数据中学习,完成特定的预测或分类任务[2,3]。
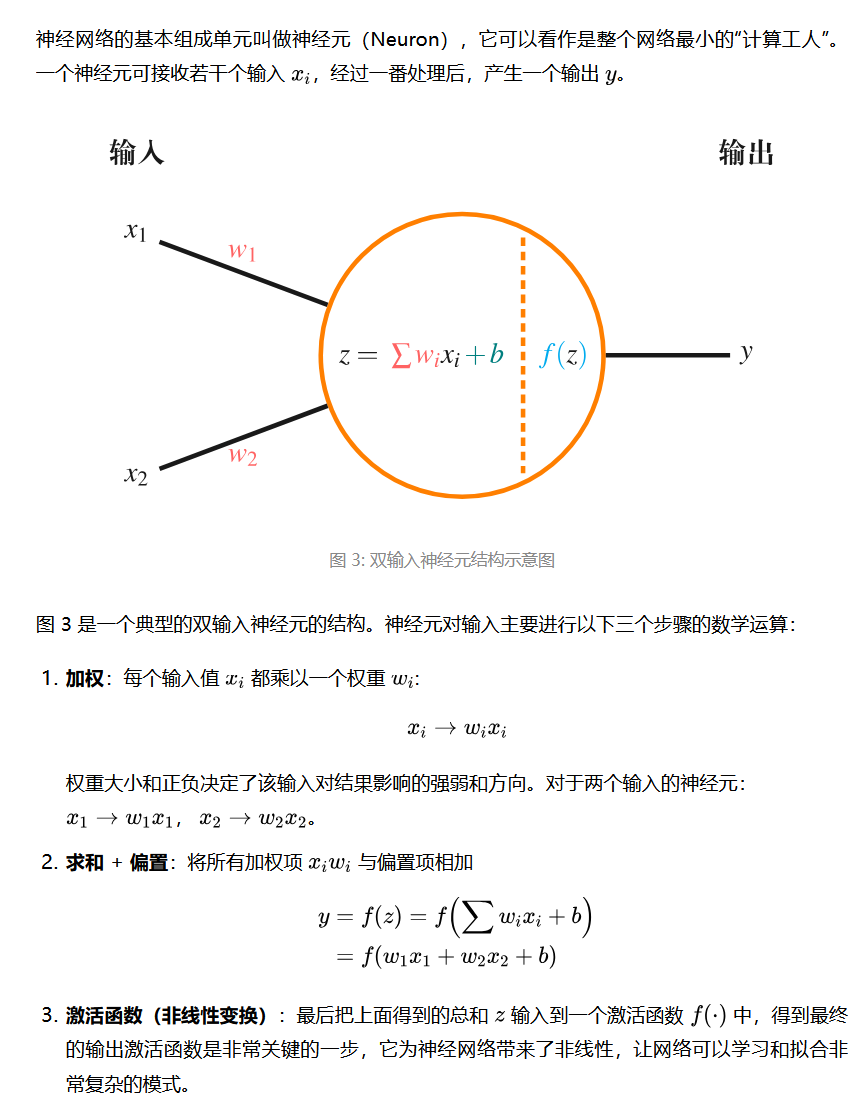
基本组成单元:神经元
将神经元组合成神经网络
神经网络本质上就是许多神经元相互连接而成的系统,这些神经元像“团队成员”一样协作,共同处理输入数据并产生输出结果。
图 5: 一个简单的神经网络示意图
神经网络的训练
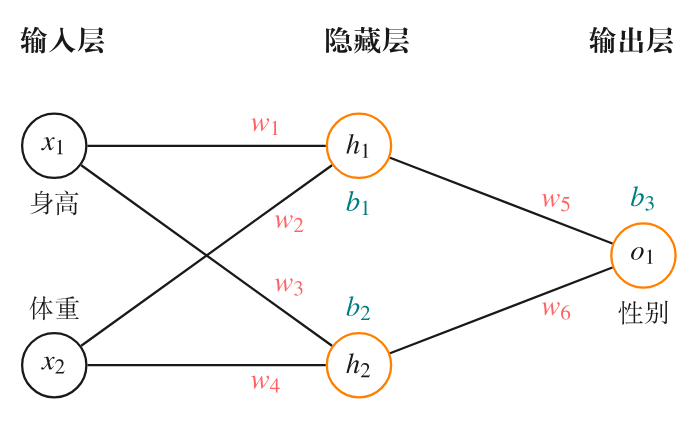
假设我们要构建一个如图 6 的简单神经网络,其任务是根据一个人的身高和体重来预测他的性别。这是一个典型的监督学习示例,身高和体重作为输入特征,性别作为输出标签。
图 6: 根据体重和身高预测性别的神经网
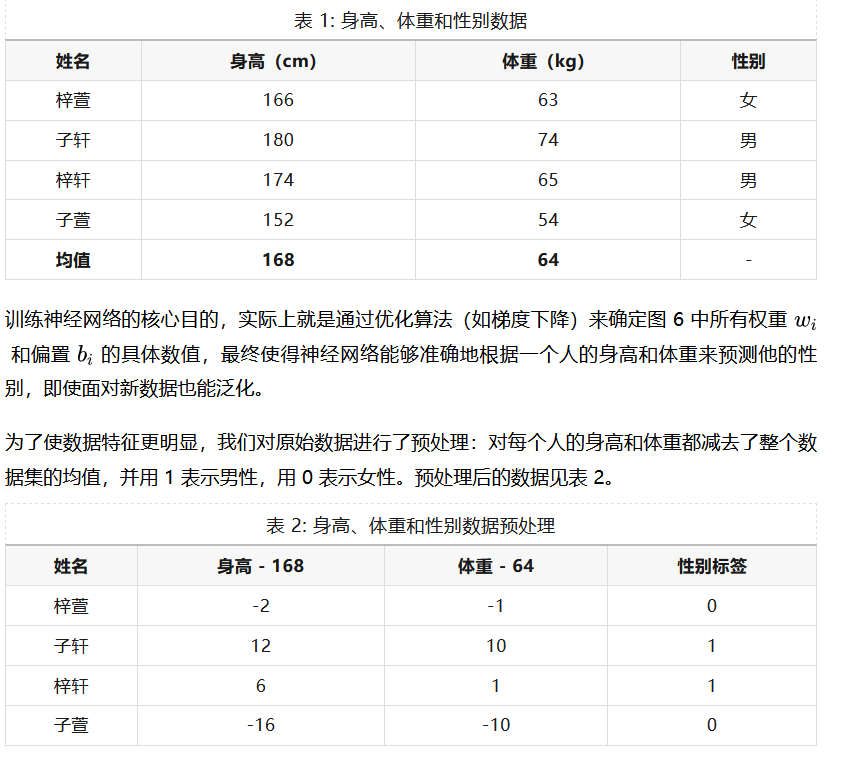
已经收集了一些测量数据,如表 1 所示。每个样本对应一个人的身高、体重及其真实性别。我们将使用这些数据来训练神经网络,让它学习如何从输入特征中推断出性别。