MIT博士在Transformer里造计算机新智元
炸裂!就在刚刚,一位MIT博士,在Transformer里造出个计算机。现在,模型一举洗刷「9.11与9.9哪个大」的耻辱,几秒内运行数百万步程序,世界最难数独准确率100%!大模型的能力边界,从此彻底改变。
就在刚刚,AI圈被一项暴力美学般的突破,彻底震碎了三观。
一位MIT博士,在Transformer里,直接造出了个计算机!
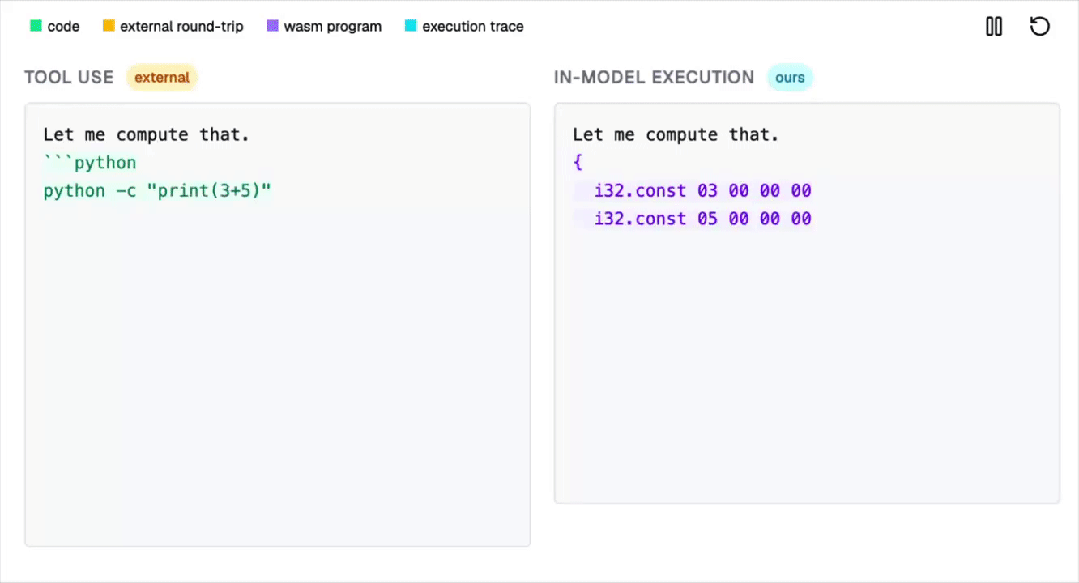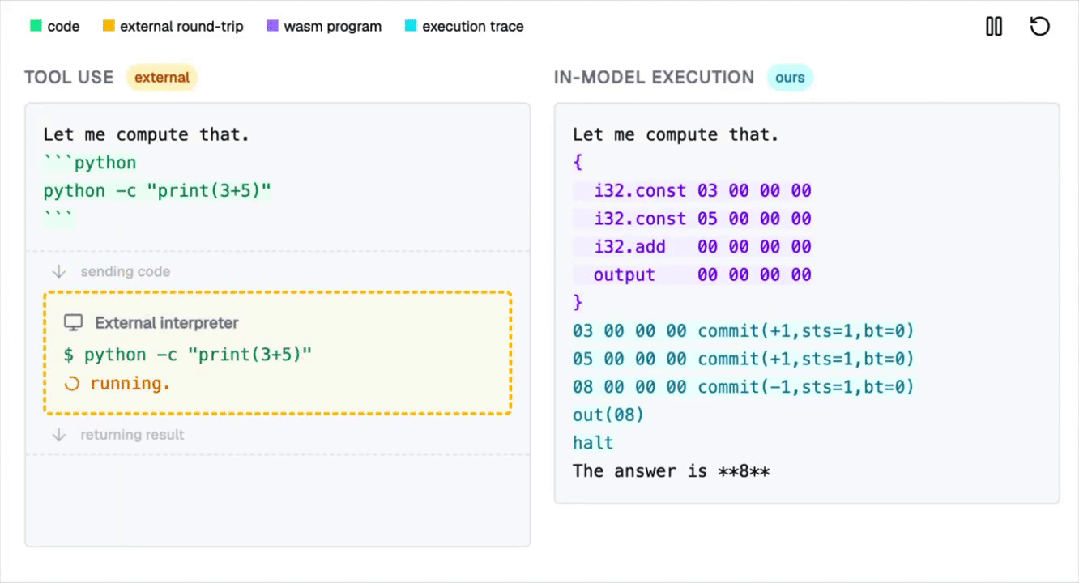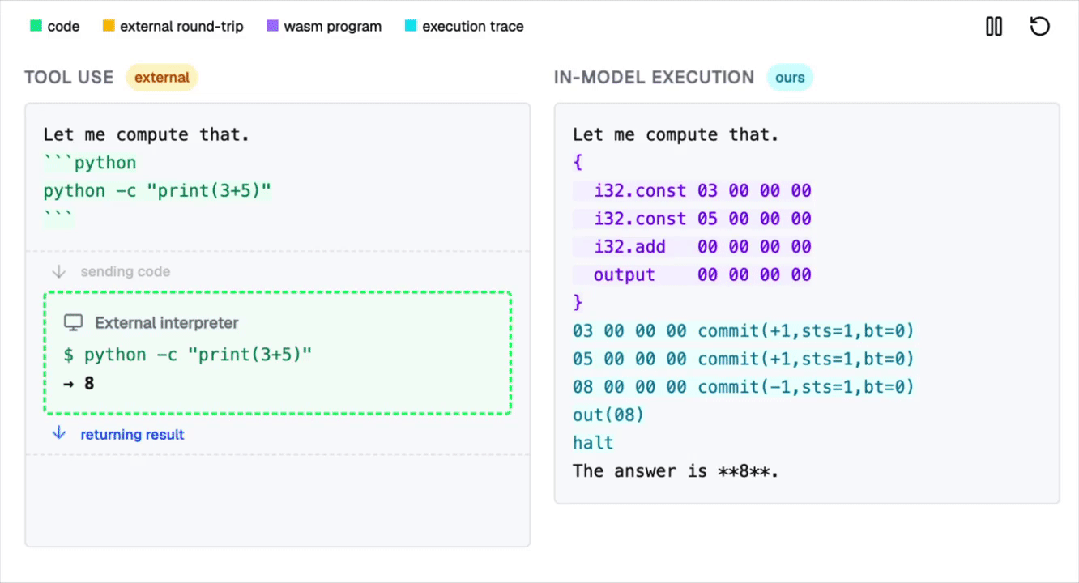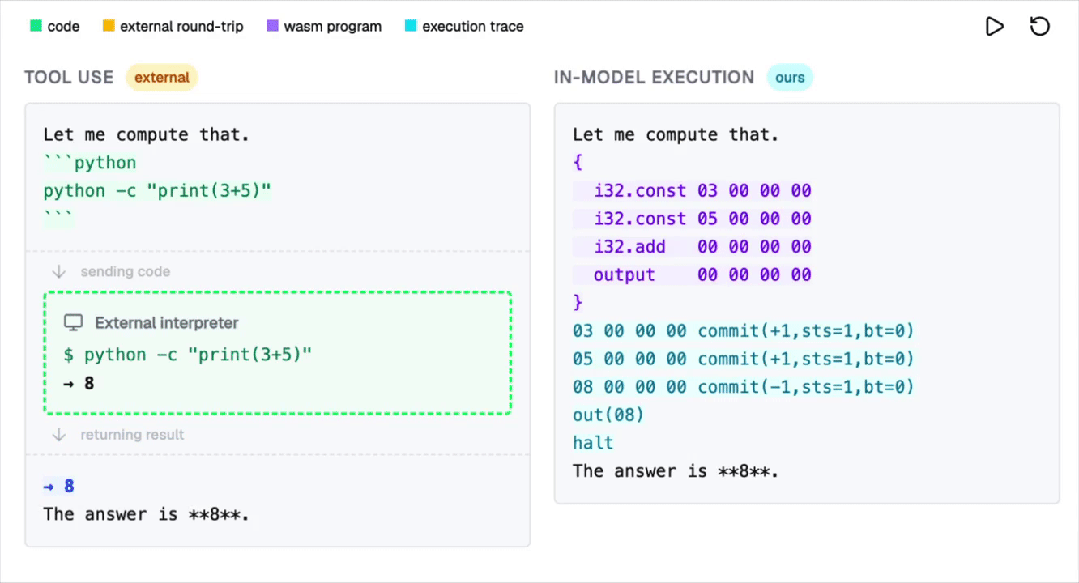
注意,不是外挂插件,不是调用工具(Tool Use),而是通过一种近乎疯狂的硬编码方式,将一个WebAssembly (WASM) 解释器无损地(Losslessly)嵌入到了Transformer模型的权重之中。
这位博士老哥,是真的把LLM玩出硬件感了
这意味着,从此LLM不再是靠概率预测下一个智元(Token)的文字游戏机,而是进化成了一台真正的数字计算机。
如果你以为,LLM现在还算不清「9.11与9.9哪个大」,现在,你的认知将被彻底粉碎!
现在,这篇帖子已经在X上热转,引来众多开发者大神的疯狂点赞。
可以说,它一举洗刷了大模型3年以来的「耻辱」。
「Vibe Coding」之父、大神Karpathy直接惊呼:这项研究太棒了,实在是令人深受启发!
LLM终极弱点,被彻底攻破
作为一种新类型的智能,大模型能解研究级难题,但不借助外部工具,却几乎不可能完成两个数相乘或解个小数独。
那么,如何让LLM本身变得像计算机一样可靠高效?
答案是:在Transformer内部实实在在地构建一台计算机。
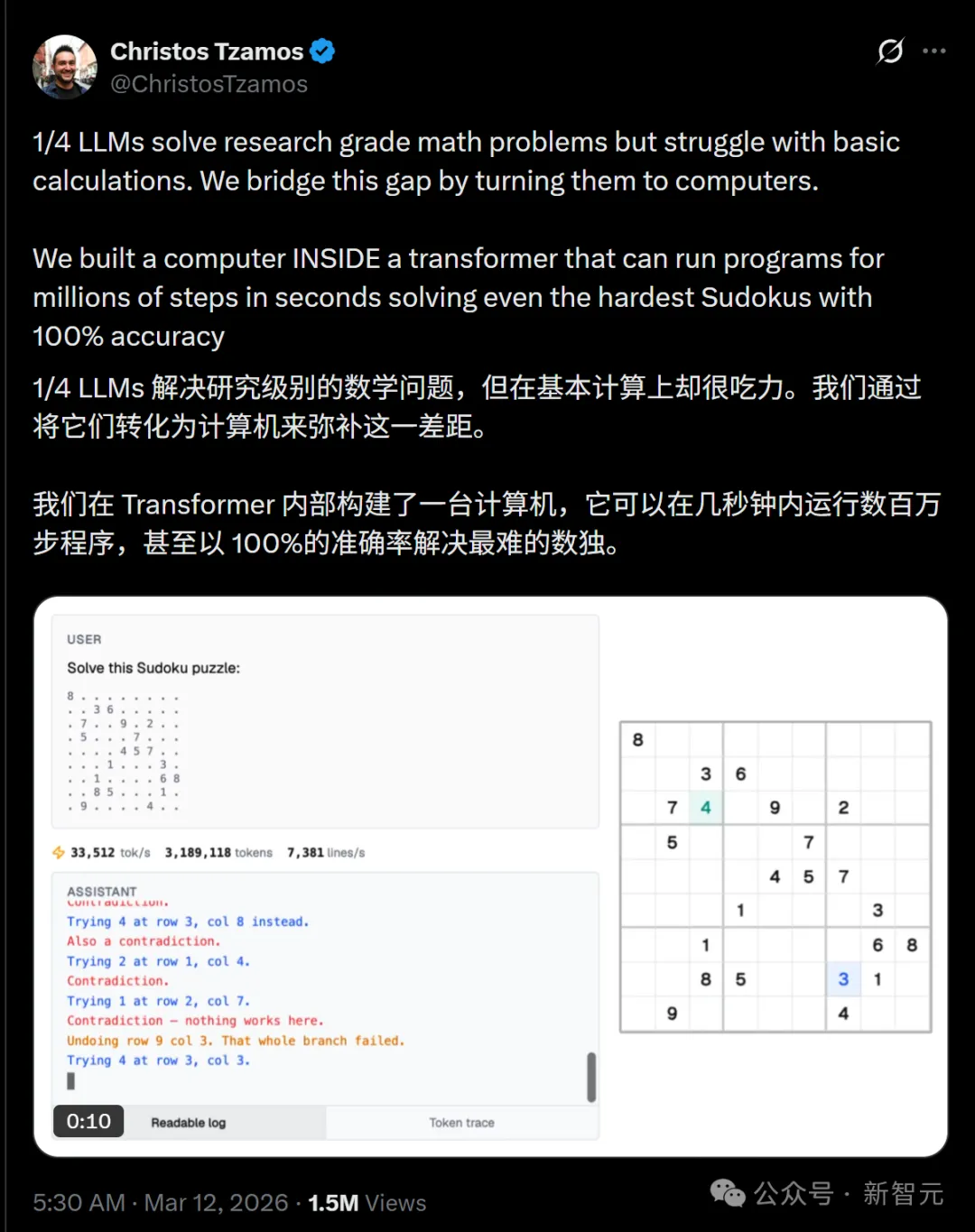
雅典大学副教授、MIT博士Christos Tzamos及其Percepta团队将任意C代码转化为智元(Token),让模型自己能可靠执行,在几秒内运行数百万步。
链接:https://www.percepta.ai/blog/can-llms-be-computers
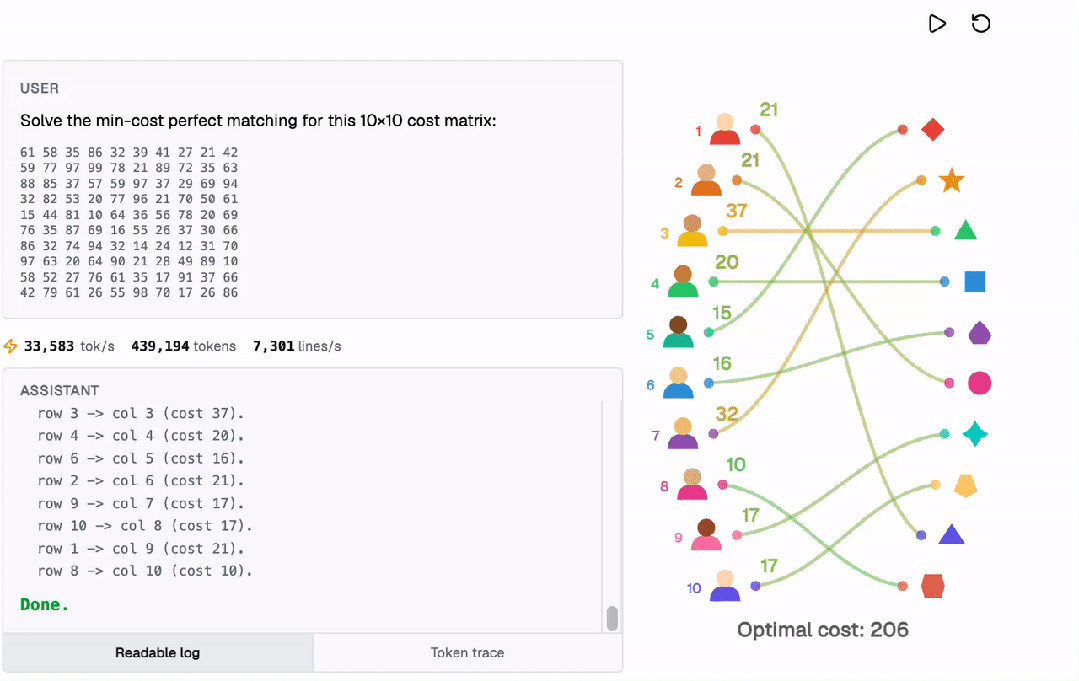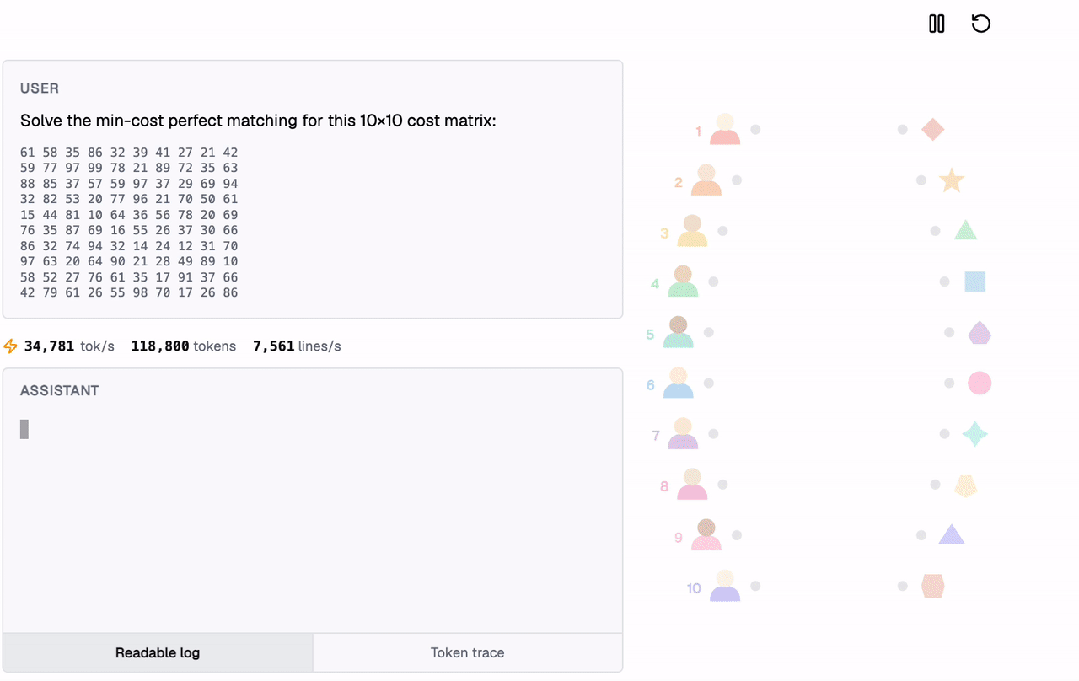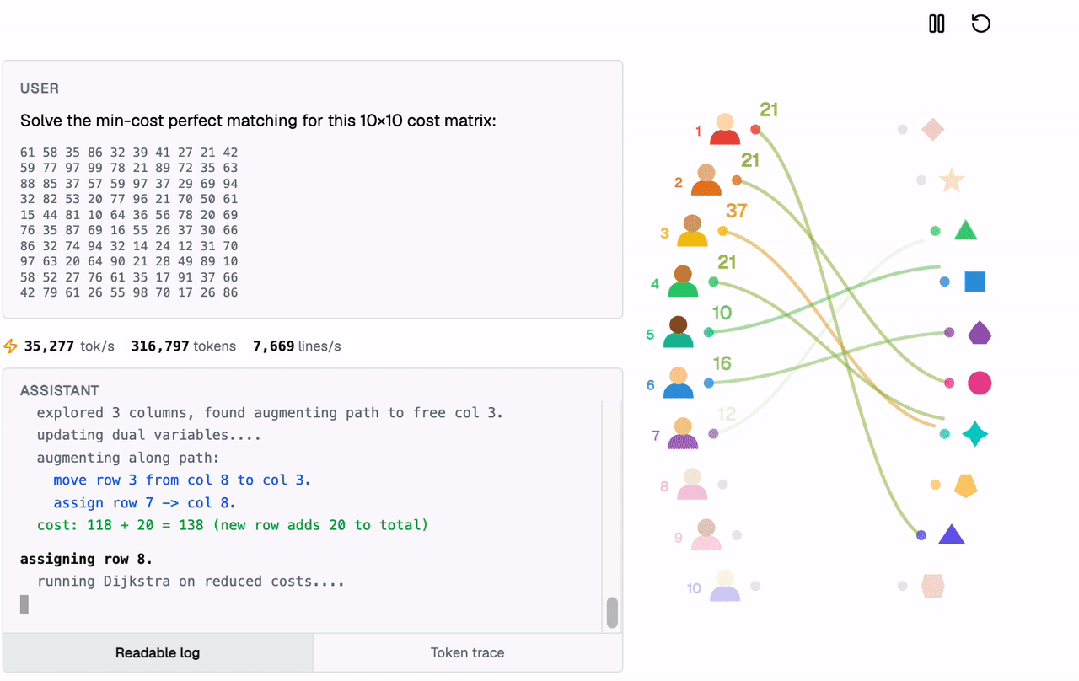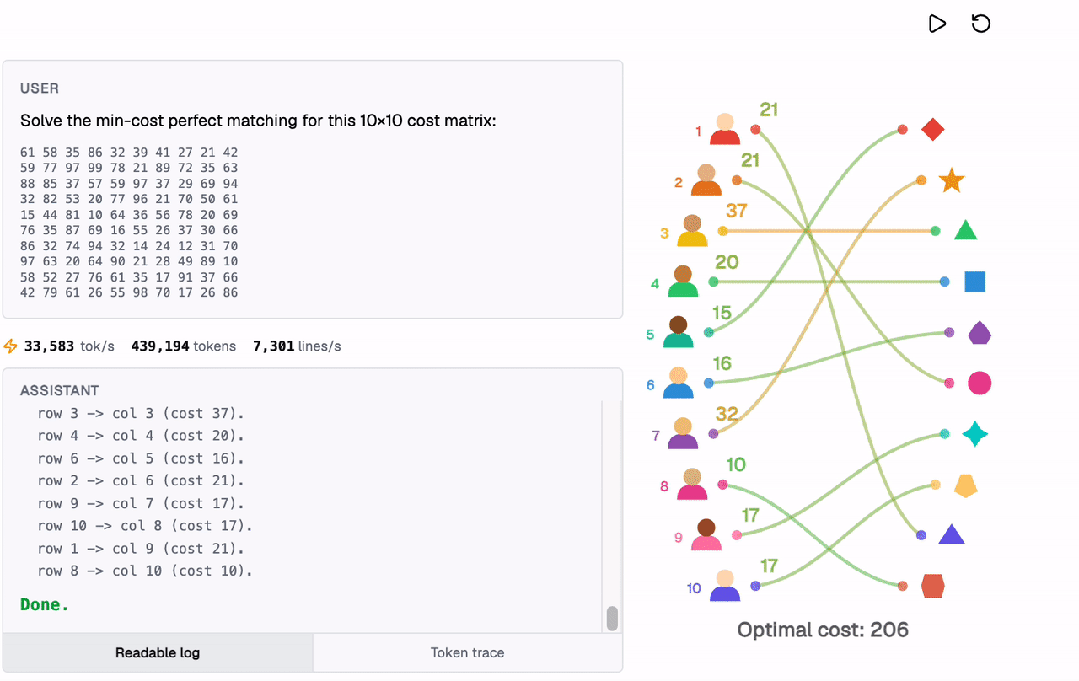
通过匈牙利算法,它解决了一个多步优化问题,即求解最小成本完美匹配,运作方式如下。
在这个过程中,AI并不调用外部工具。
所有计算都是在Transformer内部以自回归的方式完成的!
这里的难点在于,对于任何实际计算来说,LLM的标准注意力机制太慢了。
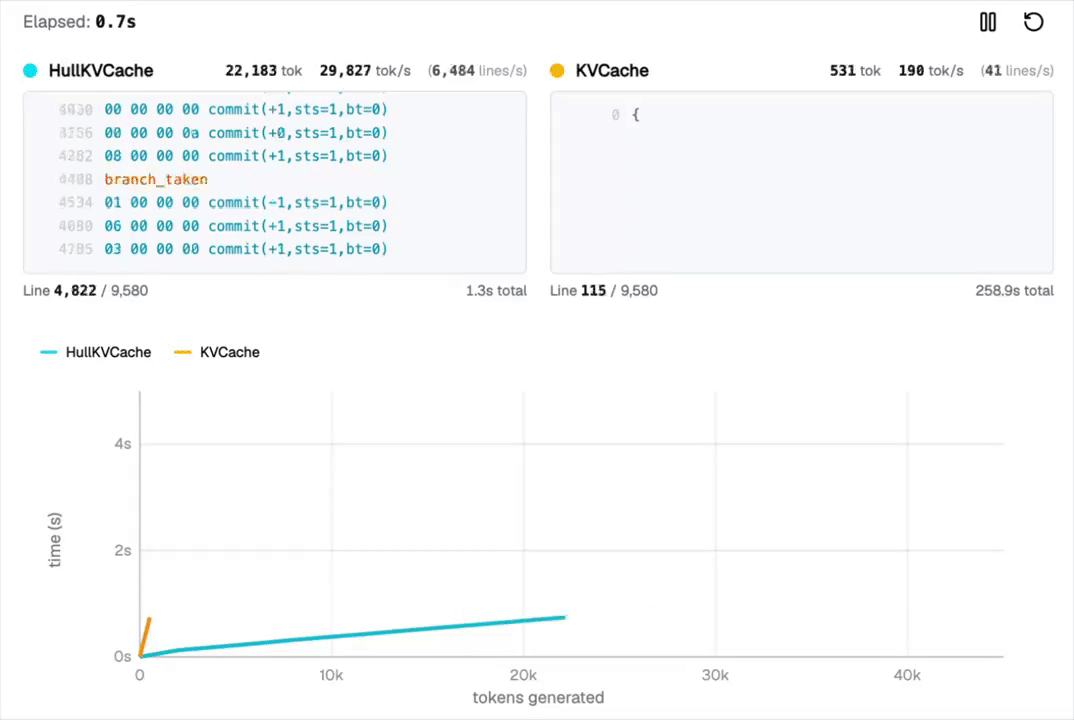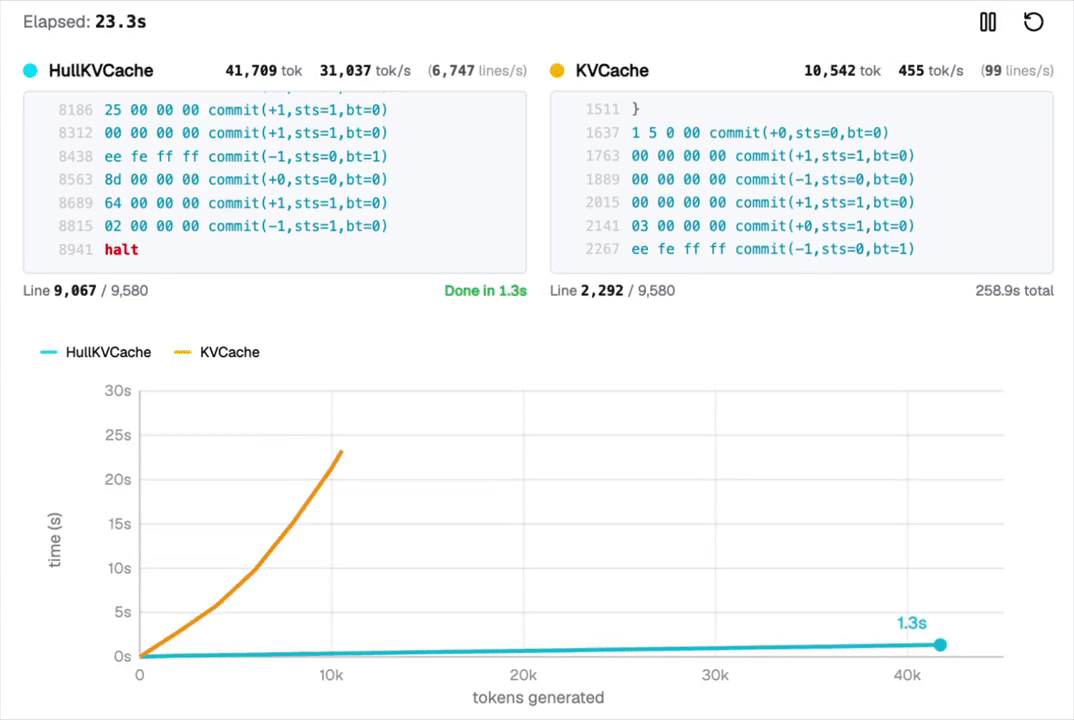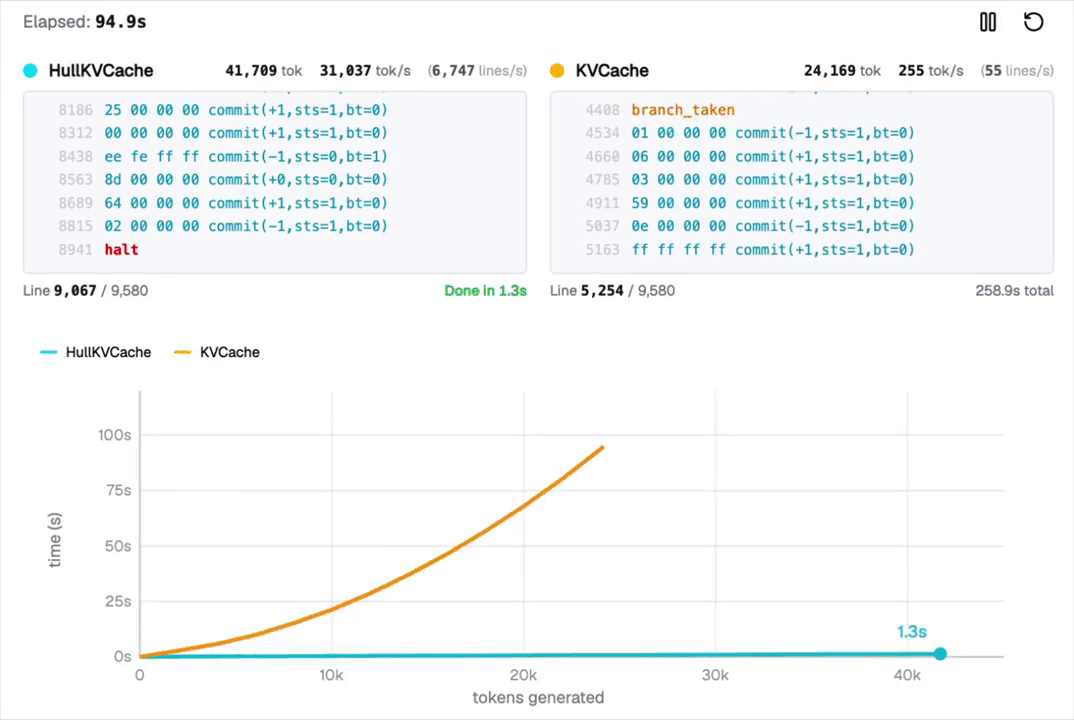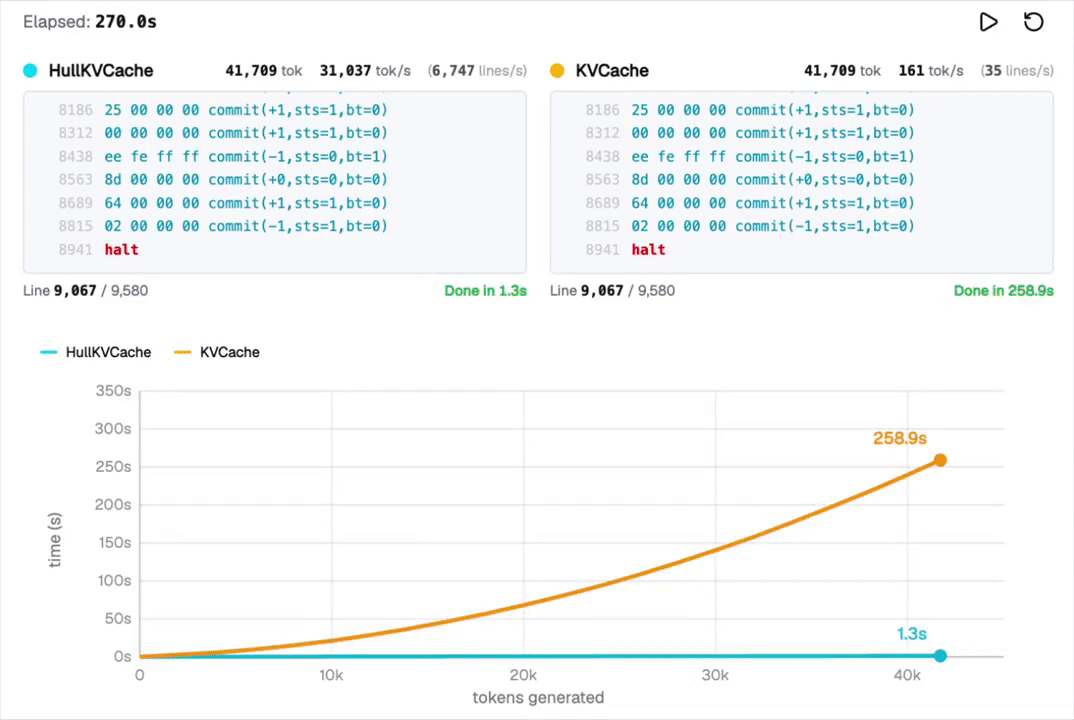
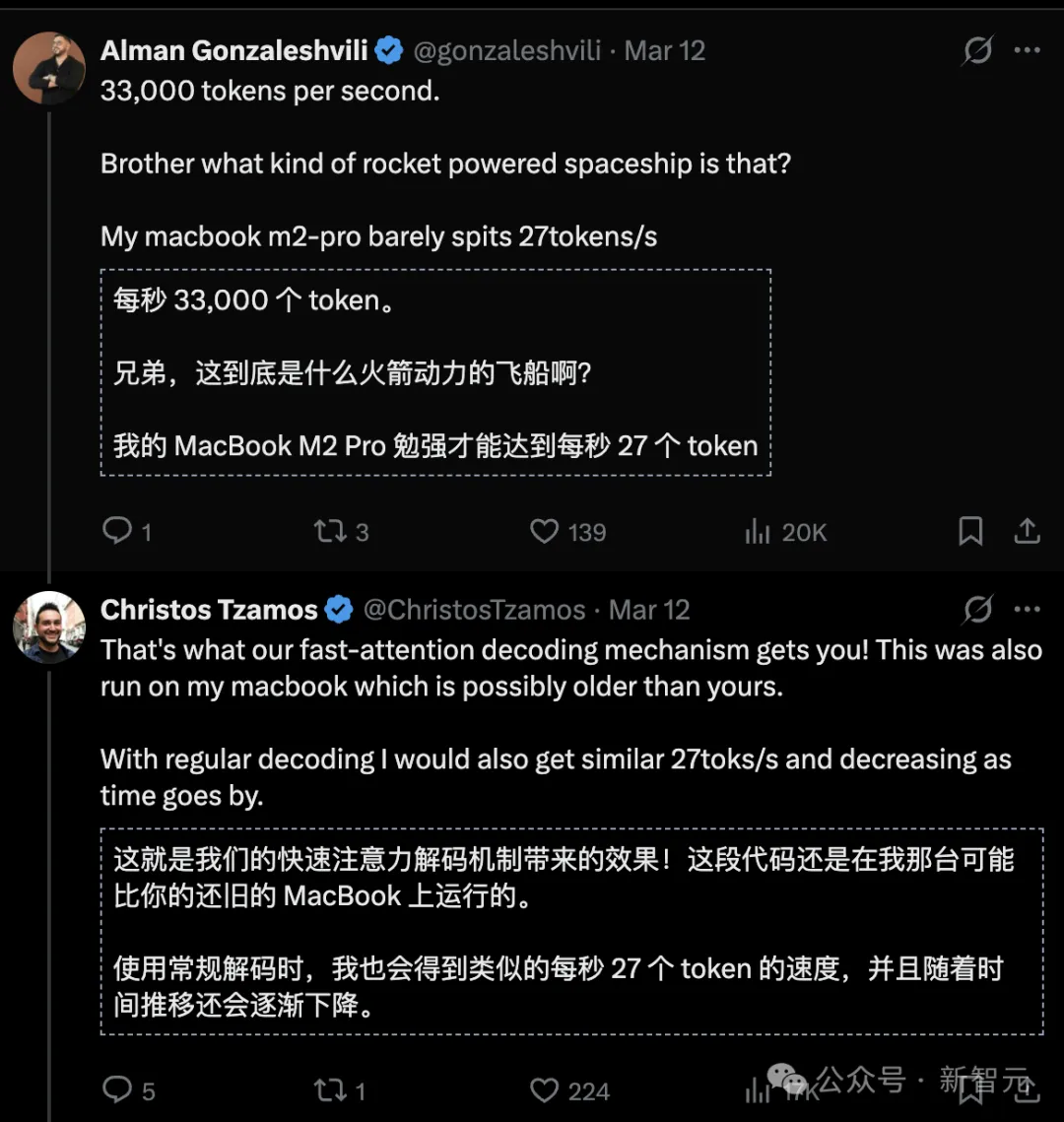
为了绕过这一限制,他们发明了一种新的解码路径,实现了指数级加速的注意力机制,让每智元(Token)生成所需的几乎所有计算量智元(Token),并在CPU上以超过每秒3万个智元(Token)的速度流式输出结果。
要知道MacBook M2 Pro的解码速度才每秒27个智元(token),每秒33000个智元(Token)堪称火箭般的速度,让人难以想象!
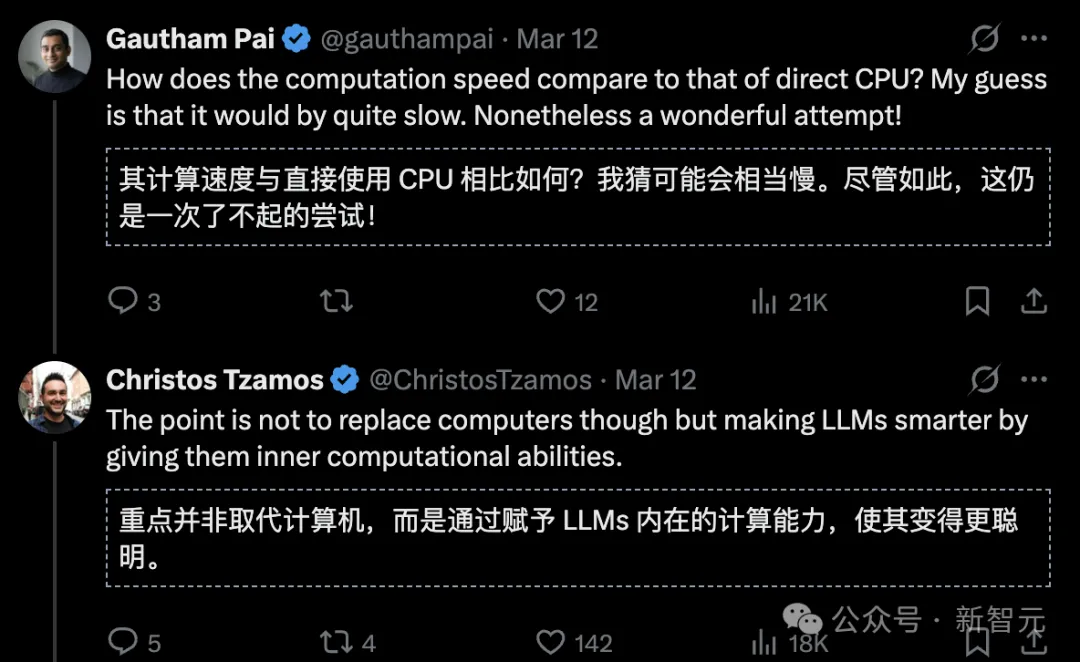
当然,用LLM的计算速度无法与CPU相比,这项研究的关键意义在于赋予LLM内在计算能力,真正教会AI算数,让它更聪明。
而这项能力与自动研究相结合,未来探索空间更是远超想象。
网友赞叹:这才是真正的原生智能!
传统attention
可以退出历史舞台?
注意,这项工作,并不是让模型更会算,而是让模型在内部真正执行程序!
不靠外挂,不调用Python,所有计算,都发生在Transformer里。