OpenAI新模型Day0就被嫌弃量子位
OpenAI刚推出的GPT-5.4 mini,Day0就已经被嫌弃了。
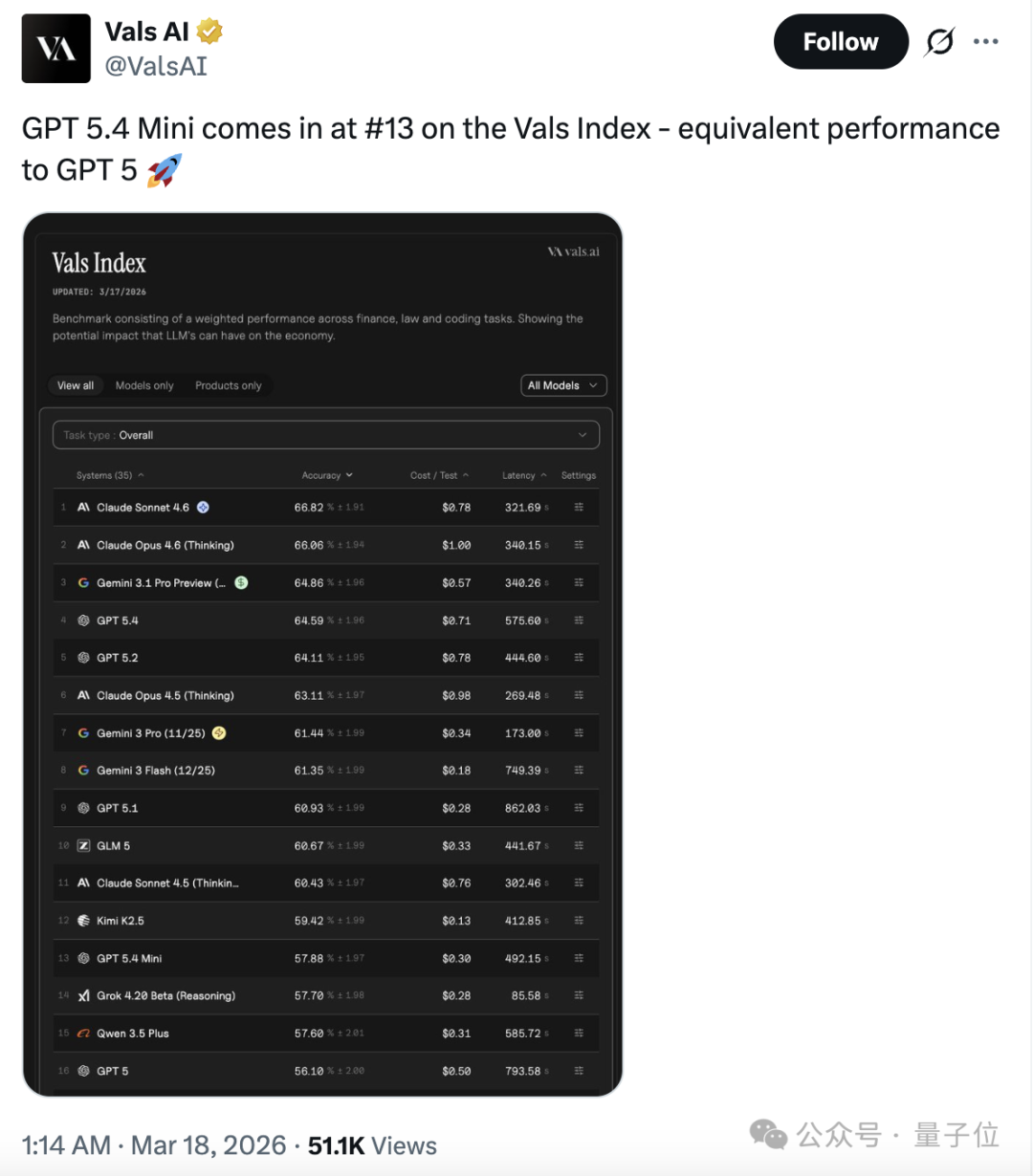
根据公开的大语言模型评测基准Vals,今天新出的GPT-5.4 mini仅排行第13名,优于OpenAI半年前发布的GPT-5。
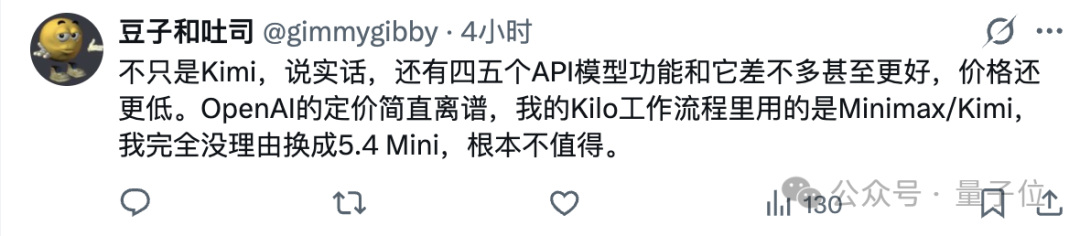
值得一提的是,排行第12的是一月底出的的Kimi 2.5,而Kimi 2.5比新出的5.4mini便宜一倍多,延迟还更低。
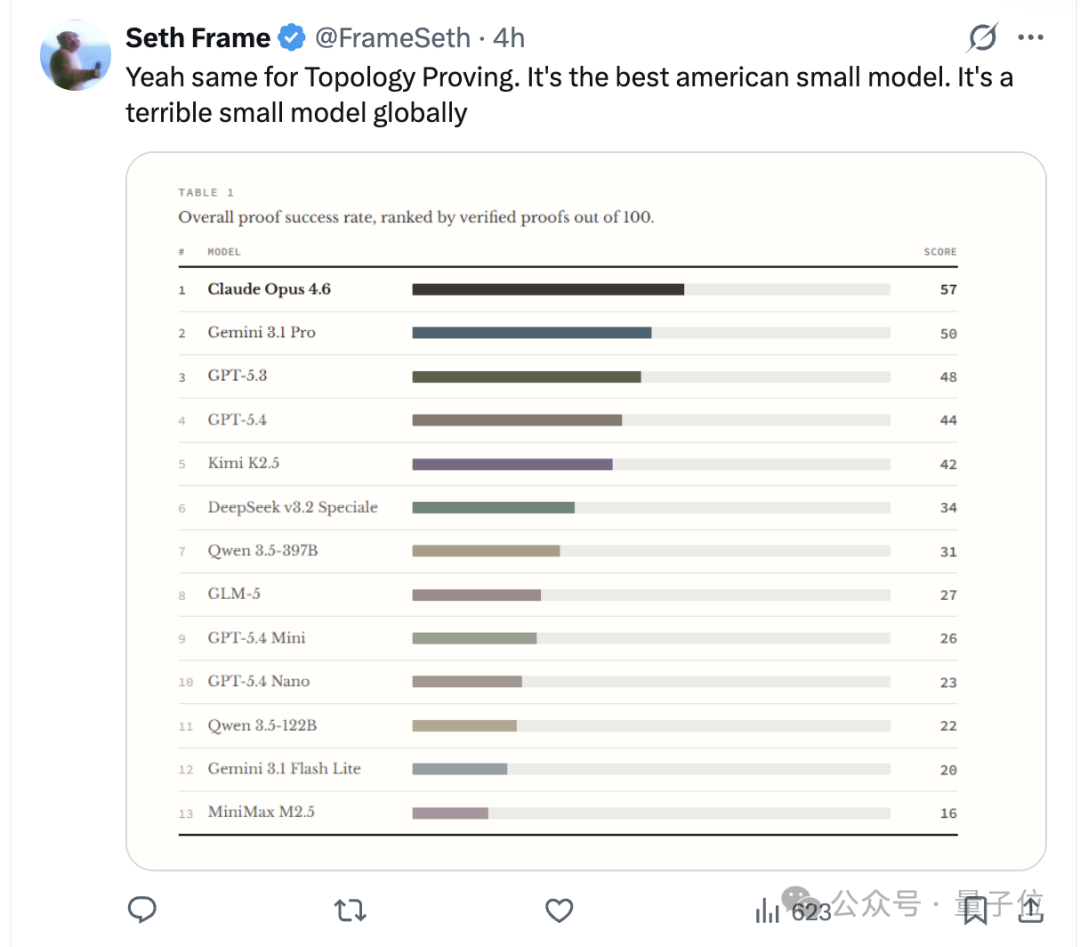
在同步的拓扑证明中,新出的mini和nano模型在全球范围内表现也只是中规中矩,分别排行第九第十,不如早前发布的Kimi、Qwen、DeepSeek等模型。(OpenAI后来居下这一块)
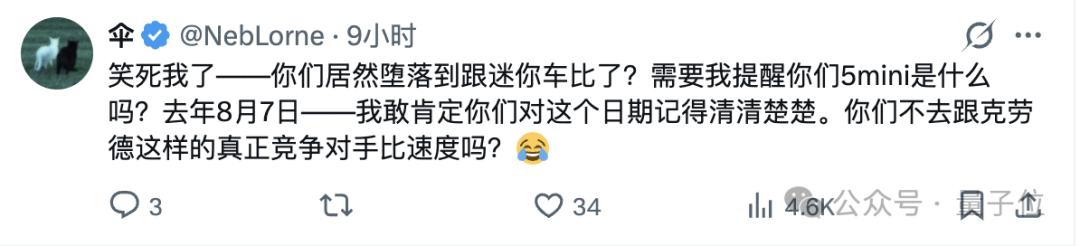
还有人指出,这次GPT‑5.4 mini的baseline对比的是老GPT‑5 mini(运行速度快两倍),也就是大半年前的版本,而不是其他厂家的新模型。
不少网友甚至直言,换新GPT‑5.4 mini“还真没必要”。
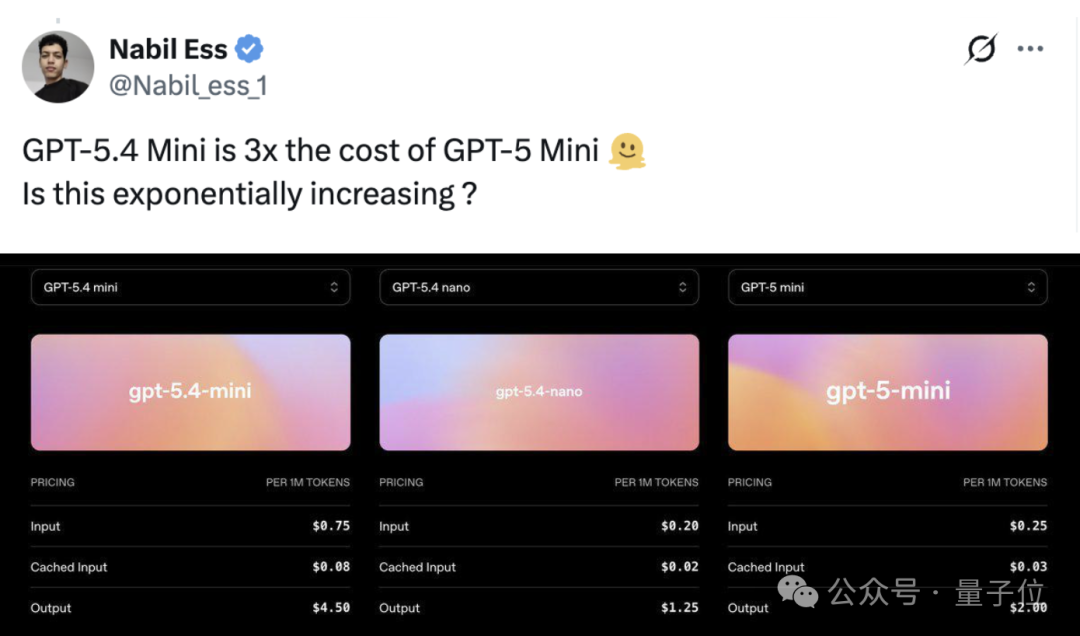
虽然OpenAI的博客表示,在输出tokens 上,性能近似的mini版本比GPT‑5.4便宜三倍,nano版本则几乎便宜十二倍。
但如果你拿GPT‑5.4 mini与旧版GPT‑5 mini对比,会发现同为mini档的模型,价格却上涨了大约三倍。
可以说,在龙虾热中,全球所有模型厂家都在涨价,奥特曼这么精的小子自然也没放过。
所以,这是拿着专门优化过编程和agent的小模型就来了?
新版mini和nano模型
今天,OpenAI推出主打快速和经济的GPT-5.4 mini和nano模型,专门针对编程、计算机操作、多模态理解以及子代理(subagent)做了优化。
相比前代GPT‑5mini,新版mini和nano在性能上有不错的提升,同时运行速度提升超过两倍。
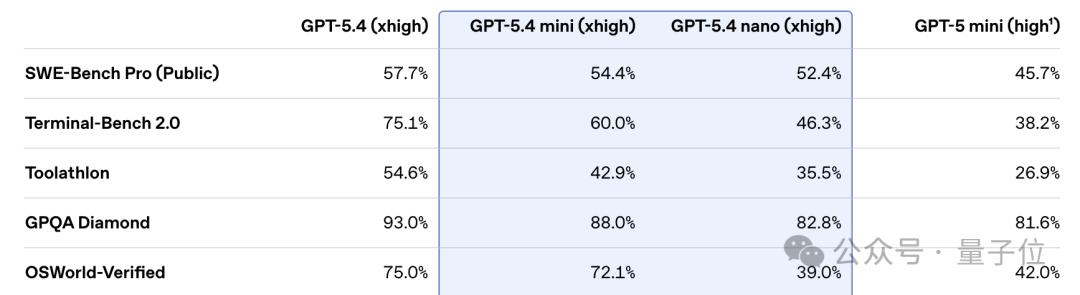
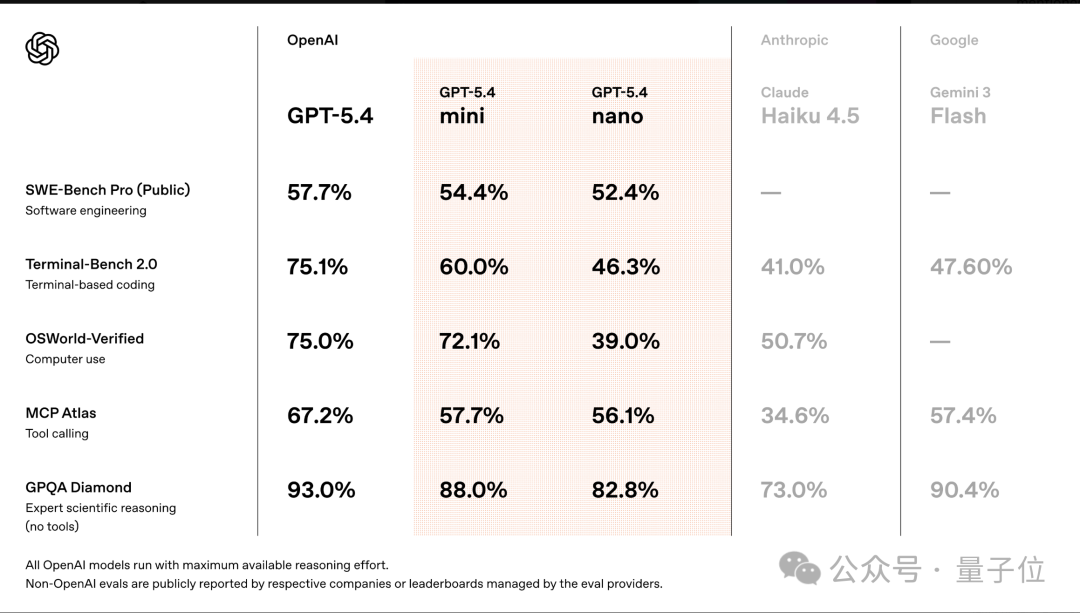
值得注意的是,在多个评测中,mini/nano模型与满血版GPT‑5.4的差距已经不大,性能上也基本与谷歌,Anthropic的轻量模型持平。
根据OpenAI官方博客,新模型主打编程和子代理。
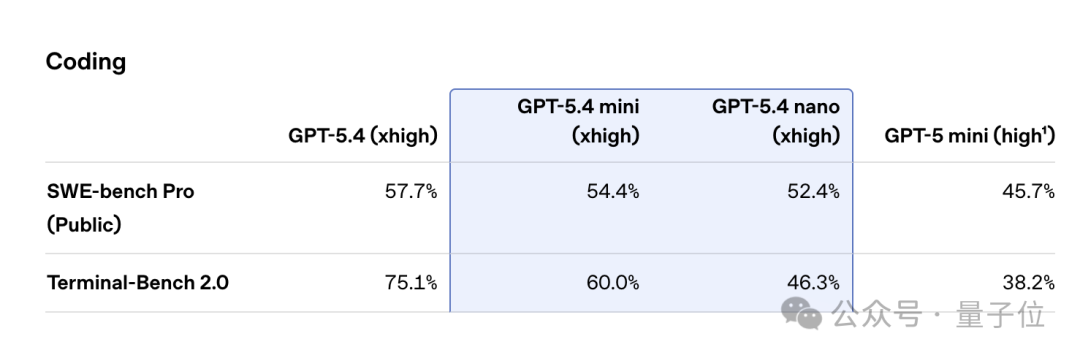
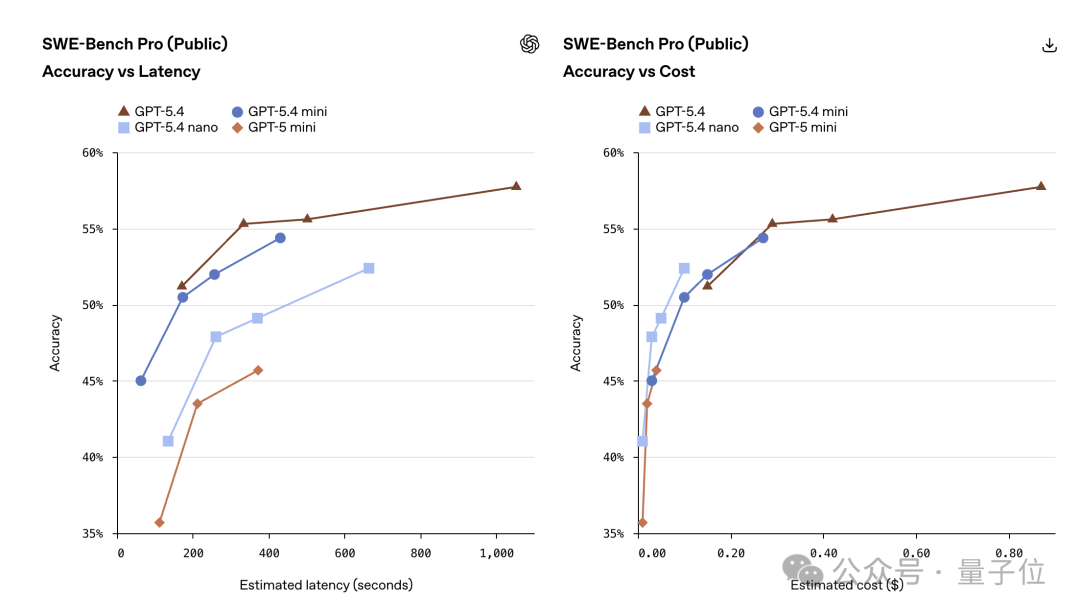
其中,GPT‑5.4 mini在编程、推理、多模态理解和工具使用方面进行了优化,运行速度提升超过两倍,在SWE-Bench Pro和OSWorld-Verified等评测中表现接近满血版GPT‑5.4。
GPT‑5.4 nano则是GPT‑5.4系列中最小、最经济的版本,适合速度和成本敏感的任务,例如分类、数据提取、排序,以及处理较简单的辅助编程任务。
总的来说,这俩新模型适合延迟直接影响产品体验的工作负载,比如编码助手、子代理、屏幕截图解析、多模态应用。
说白了就是龙虾这类已经抽象出skill的agent,部署在mini/nano这类反应快速,能力够用的小模型就更实惠。
在具体的使用上,GPT‑5.4 mini可在API、Codex和ChatGPT中调用,而nano仅能通过API使用。
价格方面,mini版本每百万输入tokens0.75美元,每百万输出tokens4.5美元。Nano版本在API中费用更低,每百万输入0.2美元,每百万输出1.25美元。
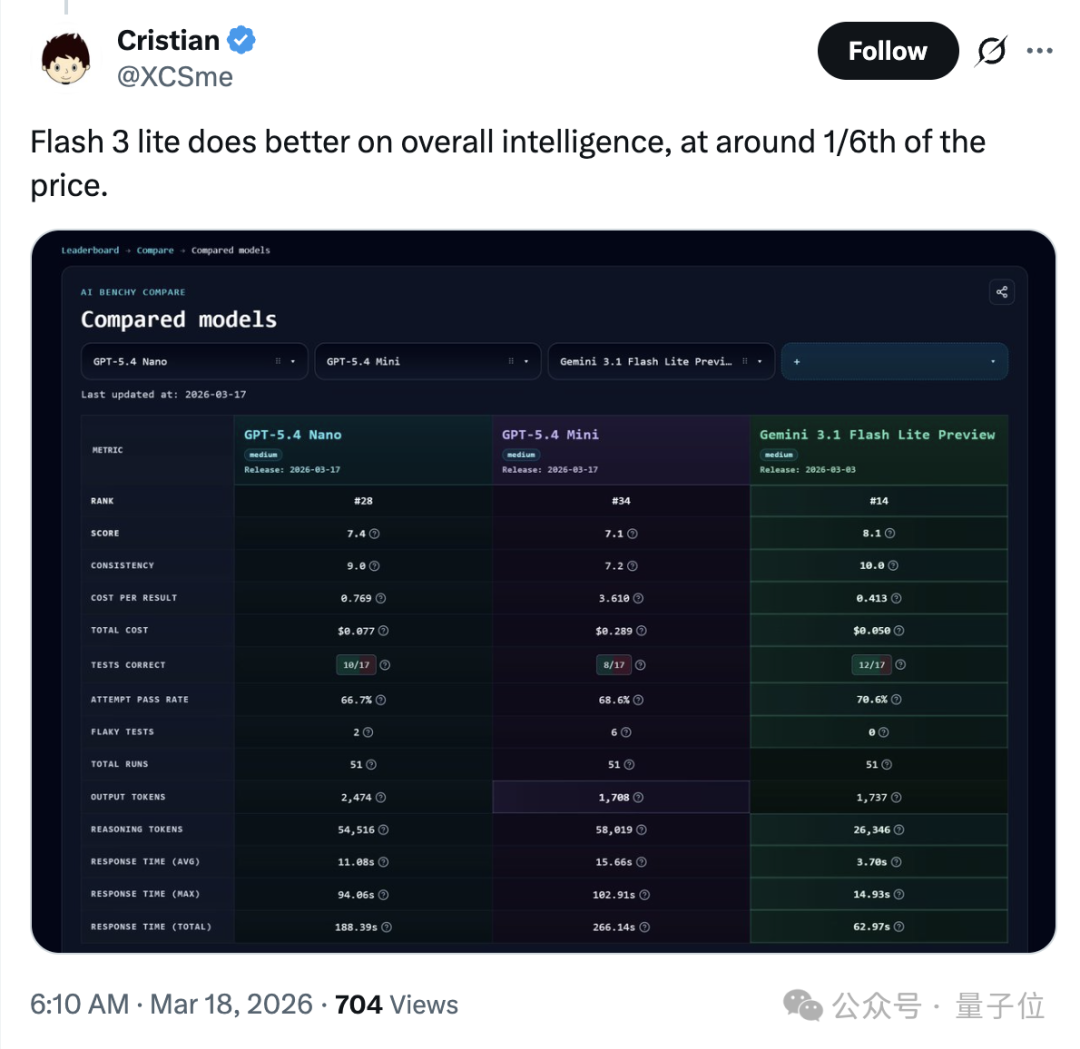
不过,横向对比来看,有网友指出,Gemini Flash 3 lite则更智能,而且总体要便宜六倍多。
在实际评测中,mini和nano主要是针对编程和Agent任务做了优化。
在编程任务中,它们能够低延迟完成代码修改、调试循环和库导航,快速迭代,高效处理需要速度和成本兼顾的工作流程。
Mini的通过率接近GPT‑5.4,同时速度更快。
在子代理场景中,开发者可以让大模型负责决策和规划,同时将较小的任务并行委派给mini子代理,比如搜索代码库、处理文档或辅助操作。