苹果M4算力机密被曝光,Claude立新功新智元
Claude立大功!开发者靠它剖析MIL语言与E5二进制,绕过CoreML直达硬件,证明NPU训练从来不是硬件不行,而是苹果不让用。
AI界再迎地震,LLM训练未来或从此改变!
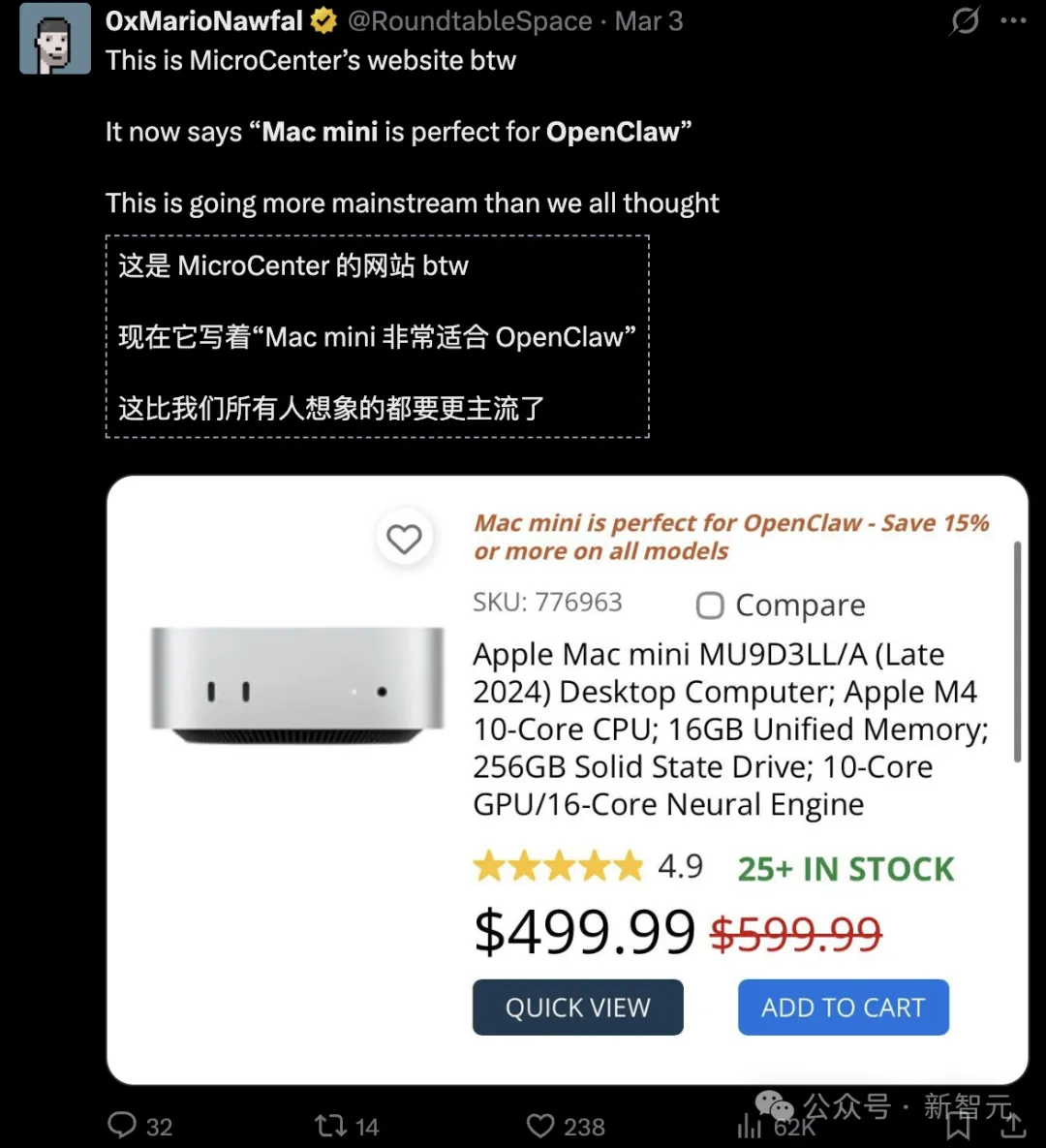
OpenClaw引起全球AI龙虾热潮,意外让苹果Mac mini卖爆——
美国百强连锁店之一的microCenter,本来主打的个人消费级PC,最近甚至宣称「Mac mini和OpenClaw天生一对」!
还有好消息:MAC mini养完小龙虾,不用吃灰了——
刚刚,苹果神经引擎(Apple Neural Engine,ANE)被破解,可能引爆AI训练革命!
工程师Manjeet Singh用Claude逆向工程Apple Neural Engine了,还训练了一个单层Transformer。
想象一下:不用GPU,不用TPU,就在M4芯片上完成的。
这并不意味着现在任何人都能构建LLM。还没到那一步。但现在你已经可以在自己的MacBook上用一个小数据集做家庭实验了。
无需CoreML,无需Metal,无需GPU。纯粹利用高速运行的ANE芯片。
如果属实,这无疑意义重大——
而且Claude深度参与了破解全程,包括整个逆向工程、基准测试以及训练代码的开发——由人类的直觉引领探索方向,由AI进行数据推理并撰写分析报告。
Manjeet Singh直言一切都靠Claude,他只是引导方向:
我们认为,这种人机协作是进行系统研究的一种新颖且自然的方式:
一个伙伴扮演富有直觉的架构师,另一个则充当编写代码和设计实验的工程师。
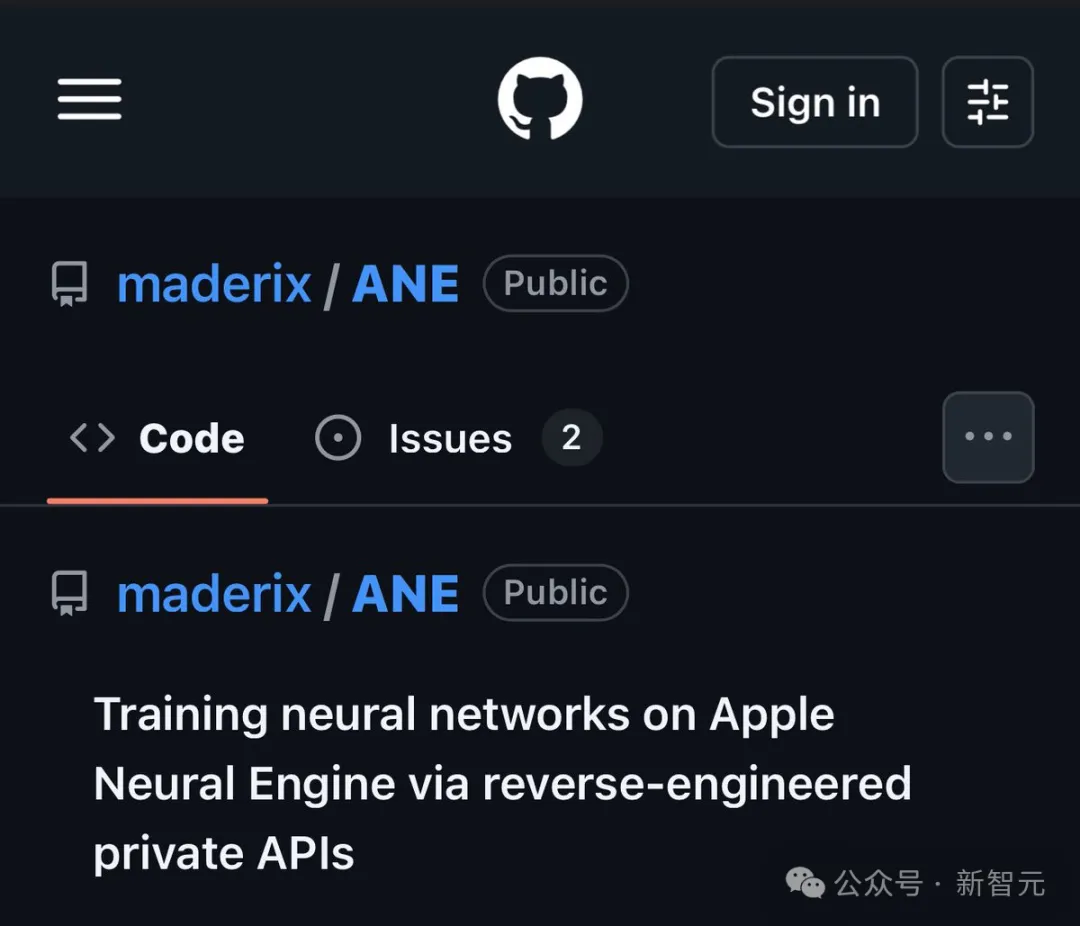
链接:http://github.com/maderix/ANE
Mac就能训单层Transformer!
Claude在这里扮演了关键角色。
通过Claude的智能分析,开发者钩住了私有方法、剖析了MIL语言的秘密,并拆解了E5二进制的迷雾,最终绕过CoreML框架,直接操控ANE硬件实现前向和反向传播。
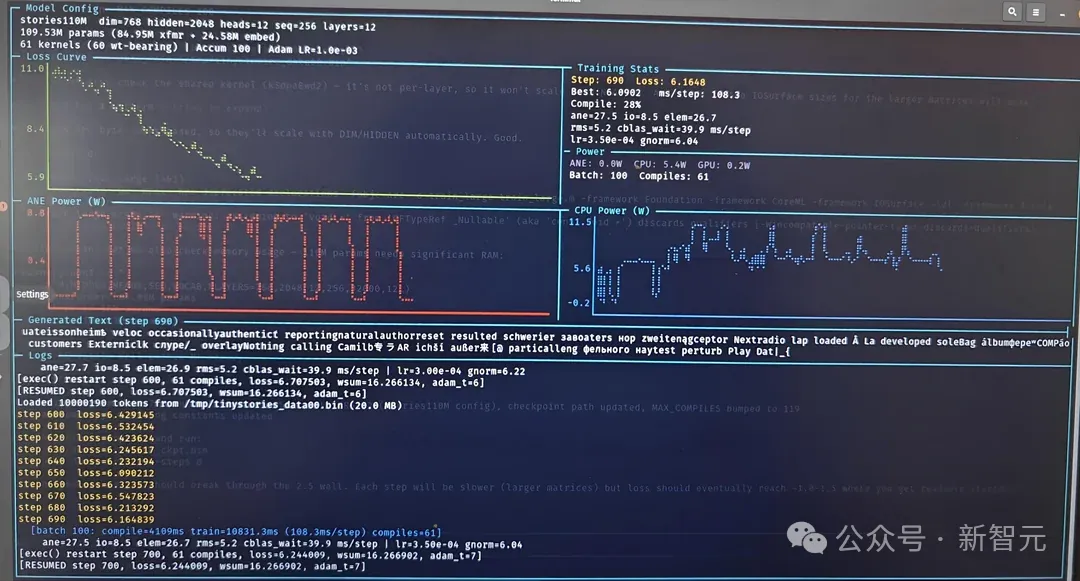
一个单层Transformer(dim=768, seq=512)仅需9.3毫秒一步,峰值效率高达6.6 TFLOPS/W——
这是A100的80倍,H100的50倍以上。
这一发现让无数人的算力账单显得像个笑话。
更惊人的是,最新更新已实现完整Stories110M模型(109百万参数,12层Llama-2架构)在TinyStories数据集上的训练,损失实时下降,功耗低到「小于一瓦特」。
你的桌面Mac,从此不再是消费工具,而是AI训练的超级电脑,成本暴降至电费的零头。
这将改变世界。
首次,任何拥有Mac的人都可以在本地、私密地以远低于云GPU的成本微调、训练或迭代大规模模型。
不再租用4万美元的A100集群。不再排队等待。不再留下巨大的碳足迹。
过去动辄数万甚至数十万美元的训练成本?如今暴跌至几乎只需几美分——基本就是你那台闲置Mac本就在消耗的电费。
AI革命刚刚从耗资数十亿美元的数据中心转移到了你的桌面。
我们才刚刚起步,但大门已经敞开——今天是单层,明天就是完整模型。
超低成本的设备端训练时代已经到来。
未来不是即将来临,它已经在你的Mac上运行。不过,我们西岸看一下什么是ANE?
什么是苹果神经引擎ANE?
大多数新款iPhone和iPad都配备了神经引擎,这是一种能极大加速机器学习模型的特殊处理器,但关于这款处理器实际工作原理的公开信息并不多。
苹果神经引擎(简称 ANE)是一种NPU,即神经网络处理单元。
NPU类似于GPU,但GPU加速图形处理,而NPU则加速卷积、矩阵乘法等神经网络运算,是一种定制化的固定功能加速器。
它接收的是已经编译好的神经网络计算图,然后将整张图作为一个原子操作一次性执行完毕。
你无法像操作CPU或GPU那样逐条发出乘加指令(multiply-accumulate)。你提交的是一份描述完整计算图的编译程序,而硬件会从头到尾一次性跑完。
ANE并非唯一的NPU——
除了神经引擎,最著名的NPU当属谷歌的TPU(张量处理单元)。
2017年,Apple在A11 芯片中首次引入Neural Engine,当时是双核心设计。