英伟达放弃GPU上LPU:OpenAI第一个吃螃蟹量子位
世界第一也着急!据悉,在即将开幕的 3 月 16-19 日圣何塞 GTC 大会上,黄仁勋将发布一套全新的 AI 推理系统,核心是一颗专为推理优化的新芯片,而芯片的首位大客户已敲定 —— 刚刚完成 1100 亿美元巨额融资的 OpenAI。
更引人关注的是,这款芯片的底层架构并非英伟达自研,而是来自原 Groq 团队打造的 LPU(语言处理单元)架构。这意味着,英伟达在核心 AI 算力产品线上,首次大规模引入外部架构设计。
这一 “不自造” 策略的背后,是去年震动行业的一笔交易:英伟达斥资约 200 亿美元,完成对 Groq 核心技术与团队的 “acqui-hire”(收购式招聘),如今这枚推理芯片,正是该笔投资的首次落地。典型的黄仁勋式打法 —— 买下成熟方案快速部署,追求极致 ROI(投资回报率)。
是 LPU,而非 GPU:推理场景的架构革命
据《华尔街日报》披露,英伟达这款新推理计算系统将整合 Groq 设计的芯片,与 OpenAI 最新融资文件中的规划形成呼应:OpenAI 将扩大与英伟达的长期合作,包括使用 3GW 的专用推理算力(dedicated inference capacity),以及在 Vera Rubin 系统上获得 2GW 的训练算力,而这部分 “专用推理算力” 被普遍认为将基于该新芯片。
英伟达选择 LPU 而非延续 GPU 架构,核心原因在于推理场景的适配差异:
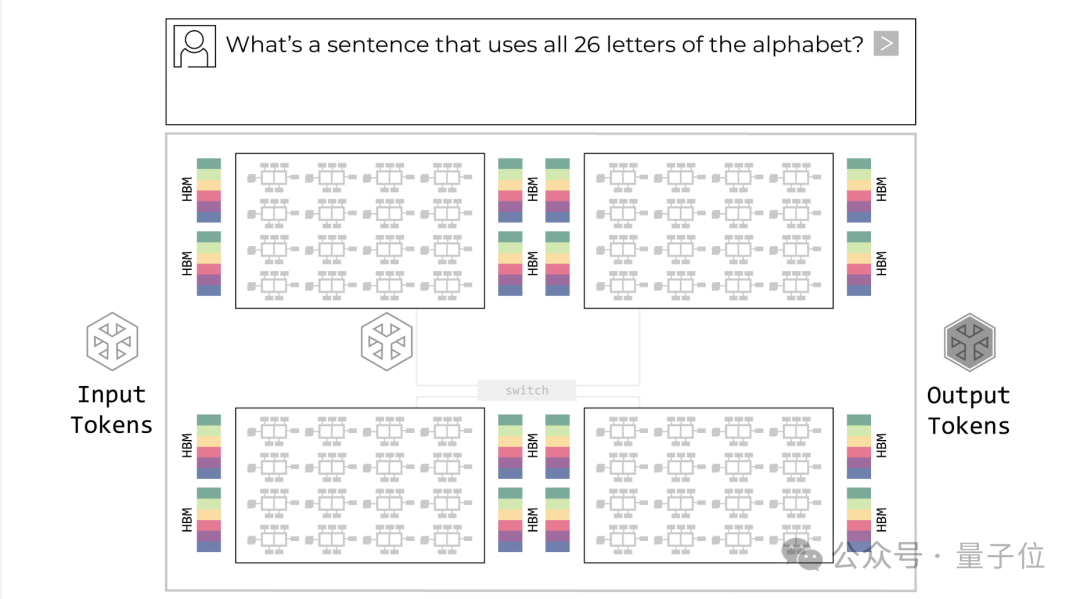
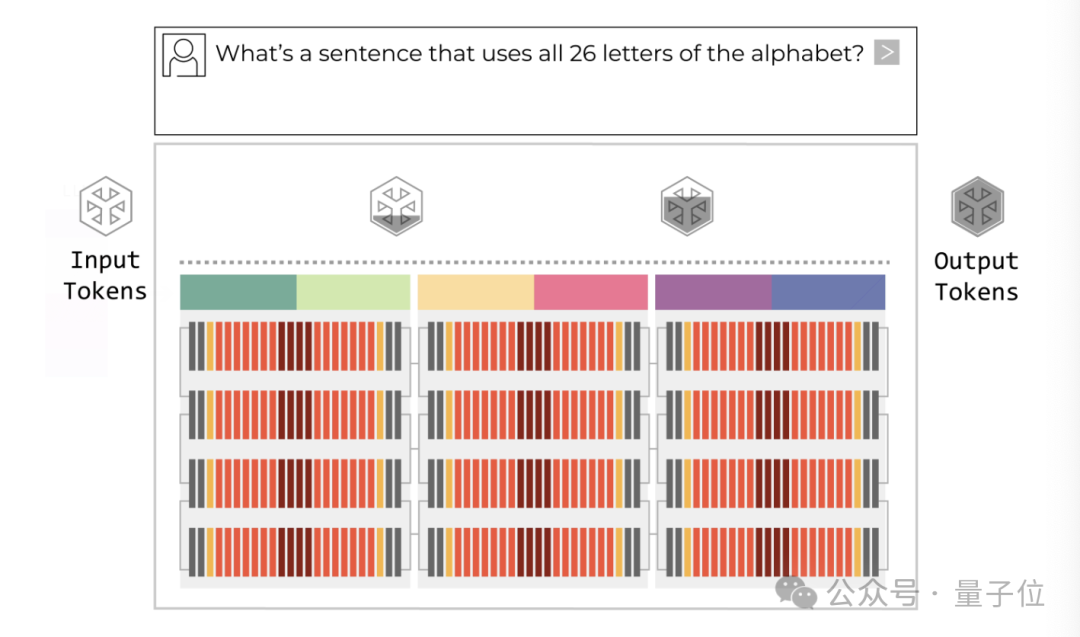
GPU 的短板:GPU 通常将大量模型参数存放在外部 HBM(高带宽内存)中,计算核心与内存间需频繁数据搬运。训练阶段可通过大规模并行摊薄搬运成本,但在推理尤其是 decode(逐 token 生成)阶段,批量变小、延迟敏感,系统瓶颈更多来自数据移动而非算力本身;
LPU 的优势:Groq 的 LPU 架构采用高密度片上 SRAM,将数据 “贴着算力跑”,极大缩短数据路径,从架构层面降低延迟与能耗,更适配低延迟推理场景,理论最高速度可比 GPU 快 100 倍。
随着 Agent 应用普及,AI 算力结构正从 “训练优先” 转向 “推理优先”,推理不再是训练后的补充环节,而是规模更大、频率更高的长期负载。英伟达将 LPU 纳入核心产品线,正是对这一算力重心转移的直接回应,也解释了其为何高价收购 Groq 团队,甚至引入创始人 Jonathan Ross(谷歌 TPU 之父)等核心成员。
推理战场狼烟起:英伟达面临全方位冲击
过去一年,Agent 应用的爆发推动算力需求结构剧变,市场重心向推理转移,成本成为核心变量,众多客户开始 “训练用英伟达,推理找替代”,英伟达的推理芯片业务迎来多重冲击:
海外巨头分流:OpenAI 与 Cerebras 签署数十亿美元计算合作协议,Cerebras 首席执行官 Andrew Feldman 直言其芯片在特定场景下快于英伟达 GPU;Anthropic 更多依赖 AWS 与 Google Cloud 的自研芯片;Meta 与 AMD 达成大规模订单,联合优化推理 GPU 架构以减少对英伟达的依赖;
国产替代崛起:DeepSeek 将 DeepSeek V4 早期访问权限独家授予华为,并完成昇腾平台模型迁移;寒武纪等国产厂商也在推理赛道加速突围。据 Bernstein Research 预测,2026 年华为在中国 AI 芯片市场份额可能达 50%,英伟达则或将降至个位数;
自研潮夹击:谷歌持续深耕 TPU,亚马逊计划用 Trainium 芯片支持 Agent 等高频推理场景;国内字节、阿里、百度等也纷纷下场自研 AI 芯片,行业趋势清晰 —— 推理成为主战场,客户开始分散风险。
之所以出现这一局面,核心在于 GPU 与推理场景的适配矛盾:训练追求 “大规模并行” 和总体吞吐量,推理则侧重 “单 token 速度” 和稳定响应。推理的 pre-fill(处理用户输入)和 decode(逐 token 生成)两个阶段中,决定用户体验的 decode 阶段,瓶颈在于频繁的数据存取与搬运,而 GPU 为并行设计,LPU 则针对性调整了存储与计算路径,更贴合推理负载。《华盛顿邮报》评论称,这是 AI 浪潮以来,英伟达首次在核心硬件层面面临架构挑战。
尽管英伟达仍占据全球 GPU 市场超 90% 份额,Hopper、Blackwell 及即将登场的 Rubin 系列仍是训练主力,但面对推理需求暴涨,这枚 LPU 芯片成为其守住市场的关键答案。
One more thing:GTC 还将有 “前所未见” 的新发布
除了这款神秘 LPU 推理芯片,黄仁勋此前已官宣,今年 GTC 大会还将发布 “世界前所未见” 的新系列产品。外界普遍猜测,新品可能包括 Rubin 系列新一代 GPU、Feynman 系列全新架构芯片,甚至是备受期待的跳票消费级显卡。