华为清华联手:研发28nm混合存内计算芯片芯东西
2月26日消息,2月15日-19日,在被业界誉为“芯片设计国际奥林匹克会议”的国际固态电路大会(ISSCC 2026)上,清华大学、华为、字节跳动等大学与公司的研究人员发表论文,首次提出一款基于HYDAR框架的28nm混合存内计算(CiR)芯片的推荐系统(RecSys)加速器。
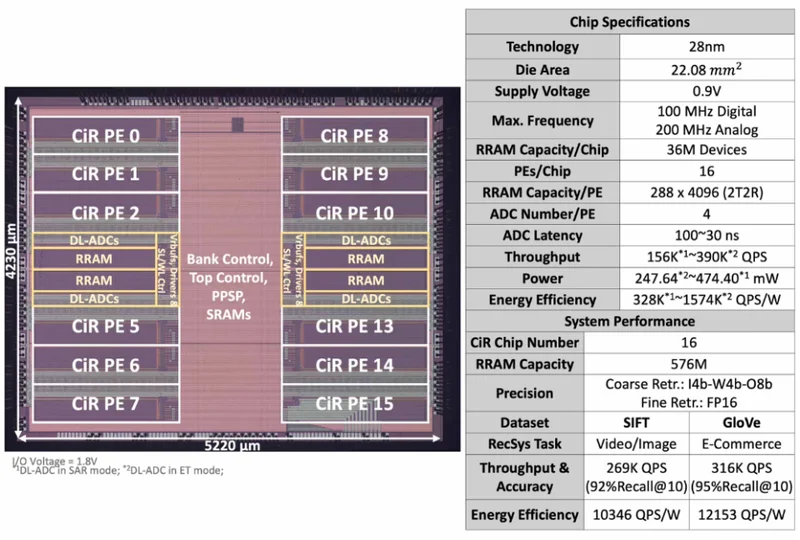
这款36M RRAM CiR芯片能实现390K QPS的吞吐率与1574K QPS/W能效比。其构建的多芯片系统可实现百万级实时端到端推荐系统(RecSys)。
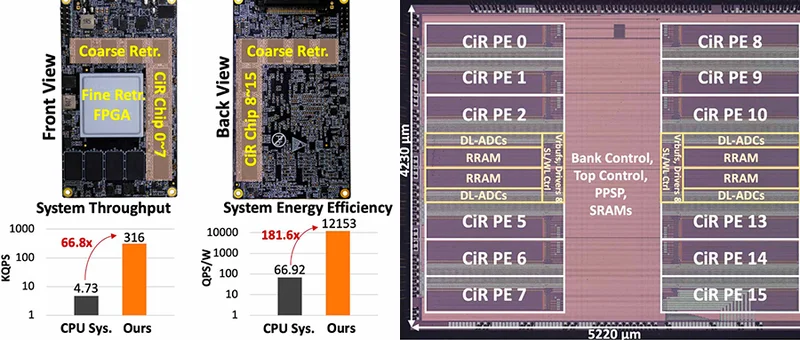
▲芯片显微照片与系统概述
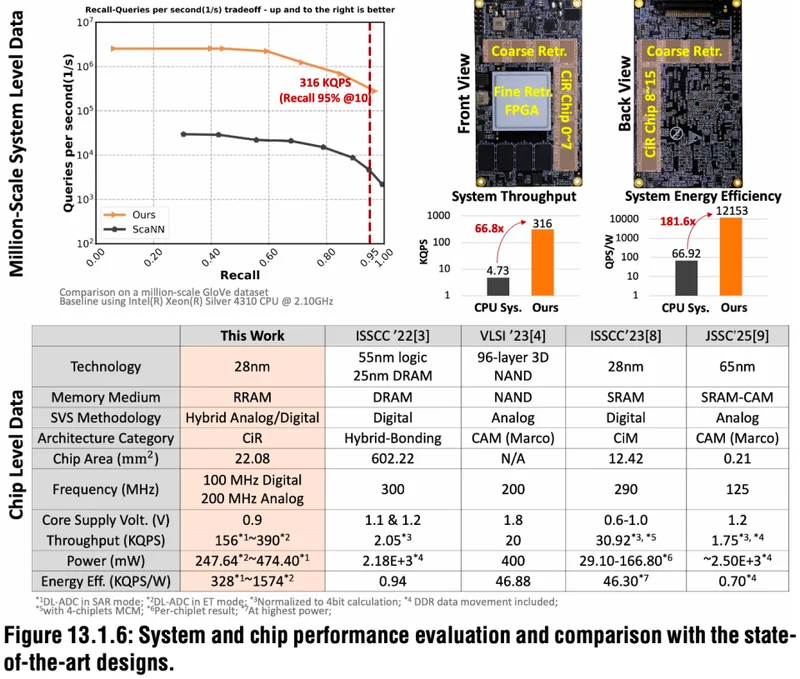
在实际推荐系统任务中,CiR通过扩展至576M规模的多芯片系统,QPS提升了66倍,QPS/W提升181倍,准确率与CPU相当。
▲芯片性能与当前顶尖设计的对比
该芯片的核心优势包括:采用DL-ADC实现非Top-K计算的早期终止;基于预测的预取调度流水线(PPSP)数据流提升不规则工作负载的吞吐量;由粗到细的检索架构(coarse-to-fine)在保证系统召回精度的同时,可扩展至大规模应用。
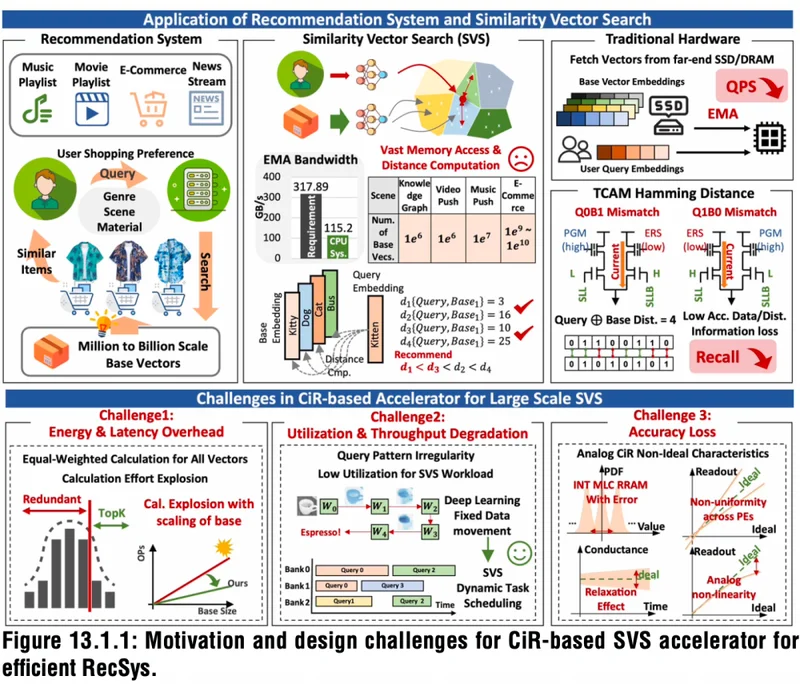
一、引入CiR,实现高吞吐、高能效、高精度相似向量检索推荐系统中的核心运算单元是相似向量检索(SVS),该方式通过计算查询向量与大规模向量库之间的距离,检索出Top‑K最邻近向量。
SVS会占据推荐系统绝大部分的计算时间与功耗,主要原因是外部存储器访问(EMA)开销。其中,采用混合键合技术的DRAM加速器成本高昂,基于NAND TCAM的加速器存在读取延迟高、数据与距离表示精度有限等问题。
针对上述痛点,研究人员提出一种基于RRAM的数模混合存内计算加速器HYDAR,可实现高吞吐量、高能效、高精度的SVS。
基于RRAM的存内计算(Compute-in-RRAM,CiR)因能最大限度减少数据移动、存储密度高、并行度极大,已被公认为深度学习加速的极具前景的技术路线。但将CiR应用于SVS仍会带来额外挑战,如能耗与延迟急剧增加、降低PE利用率与吞吐量、精度降低等。
▲面向高效推荐系统的、基于CiR的SVS加速器的研究动机与设计挑战
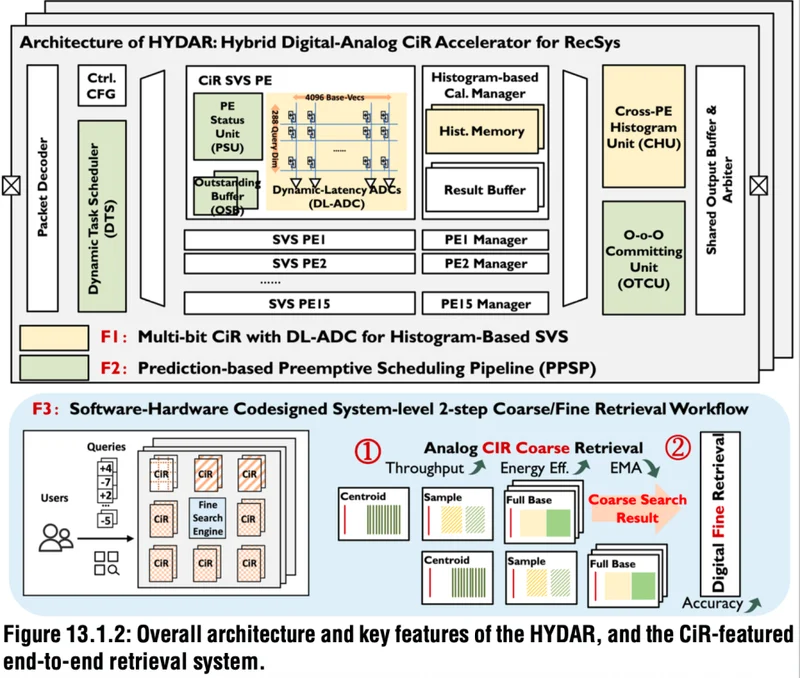
HYDAR通过CiR PE(存内计算处理单元)、混合芯片设计与多芯片系统架构协同优化,解决了上述挑战:
首先是带动态延迟ADC(DL‑ADC)的CiR PE,其通过多位模拟CiR PE集成DL‑ADC,用于基于直方图的相似向量检索,可提前将距离与检索阈值比较,并跳过非Top‑K向量,从而降低延迟与功耗。
其次是基于预测的抢占式调度流水线(PPSP),通过这种混合芯片机制,预测每个PE的运行时间、中断不平衡任务、插入短任务来平衡负载,以适应动态SVS工作流,提升利用率与吞吐量。
最后是两步由粗到精的检索架构,其软硬件协同设计框架,先在CiR PE上进行粗粒度检索以保证高吞吐量,再在数字SVS引擎上进行精粒度检索,在保证召回精度的同时最大化吞吐量。
在此基础上,基于HYDAR框架,研究人员采用28nm工艺流片实现了一款CiR原型芯片,包含36M RRAM单元,分为16个并行PE,每个PE包含一个288×4096阵列
▲HYDAR整体架构与核心特性及基于CiR的端到端检索系统
二、采用基于DL‑ADC的SVS高效过滤机制,降低60%延时、71%功耗具体来看基于模拟存内计算单元(CiR PE)的直方图相似向量检索(SVS)实现,以及支持计算提前终止的DL‑ADC设计。
其通过查询向量与基础向量之间的距离分布直方图来确定Top‑K检索的截断阈值(CK)。在欧氏距离框架下,距离超过CK的基础向量由双模DL‑ADC过滤,该ADC可动态监测比较结果,实现非Top‑K向量的计算提前终止。
欧氏距离计算可在288×4096的CiR阵列上完成,其中每个2T2R单元表示一个4位维度,每一列代表一个256维基础向量及32维偏置。
本设计中,CiR PE在计算过程中将直方图存入本地直方图存储器,随后同步至跨PE直方图单元(CHU),合并分布式结果以生成CK。该论文设计了三条定制指令来执行该流程。
在DL‑ADC方面,基于逐次逼近寄存器(SAR)的结构支持提前终止模式(ET),将预生成的CK作为输入,与每个周期生成的SAR码一同送入按位比较器。