杨立昆:AI对齐是个伪命题大顺AI商业流量
“把人类水平的AI称为AGI实际上是一个误导。”
“现在的AI对齐是一种错误的思维方式。”
“目前最好的开源模型来自中国。”
前段时间,图灵奖得主、深度学习奠基人杨立昆在达沃斯论坛上近乎“拆台”地重审了当前AI领域的三大共识。
他不是在修正技术路线,而是在否定整个认知前提。
如果你仍相信“大语言模型=智能”,或认为“对齐”是AI安全的核心解法,那么你正站在一座即将崩塌的认知高地上——而多数人浑然不觉。
本文将从第一性原理出发,系统拆解一个被严重误读的问题:
什么是真正的智能?
以及,为什么我们关于AI安全的全部讨论,可能都建立在一个错误的假设之上?
1. 重新定义智能:
语言 ≠ 智能,预测世界才是核心
你可能觉得,能写诗、编程、辩论的AI已经很聪明了。
但这些能力只是语言统计的副产品,而非真正意义上的智能。
杨立昆指出:
“真正的智能来源于对现实世界的理解。”
这句话看似简单,却直指当前AI范式的根本缺陷。
1.1 语言世界的局限性
大型语言模型(LLM)的本质,是在海量文本中学习“下一个词”的概率分布。
它擅长的是模式匹配与语言生成,而非因果推理与物理建模。
LLM无法理解“球被抛向空中后会下落”这一物理规律,除非有人用文字描述过。
它无法预测“如果我推倒这张桌子,杯子会摔碎”这一连锁反应。
它甚至无法区分“猫坐在沙发上”和“沙发坐在猫上”在物理世界中的不可能性。
语言只是智能的表层输出,而非智能的底层机制。
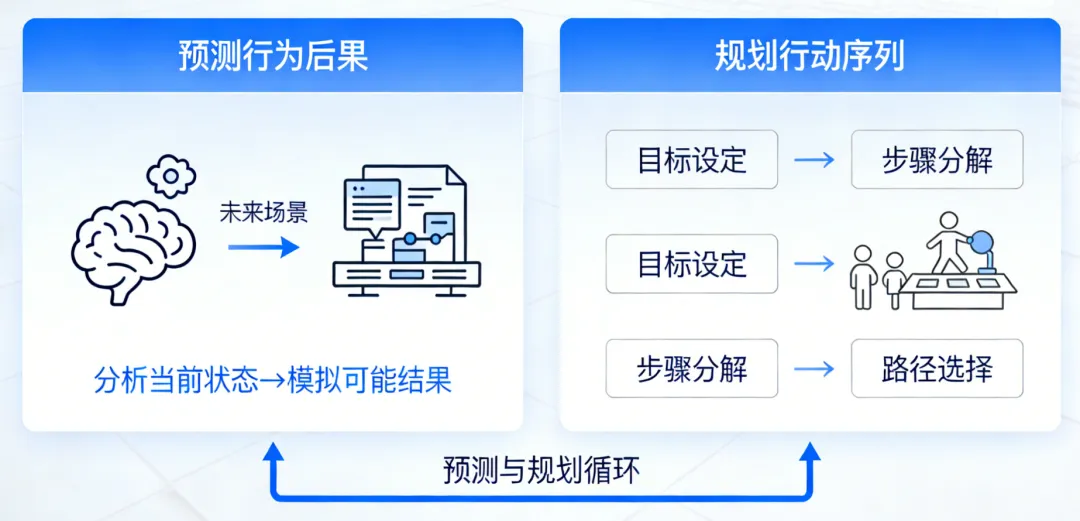
1.2 真正的智能:预测行为后果 + 规划行动序列
杨立昆举了两个极具反差的例子:
一个10岁孩子第一次面对新任务(如组装玩具),通常能在无训练的情况下完成。
一个17岁少年学开车,10小时内就能掌握基本驾驶技能。
而我们的自动驾驶系统,即便用数百万小时的真实道路数据训练,仍未实现L5级自动驾驶。
关键差异在于:
人类拥有“世界模型”(World Model)——一个内在的、可模拟物理与社会动态的心理表征系统。
它允许我们:
预测自身行为在现实中的后果;
在脑中“试错”而不付出实际代价;
规划多步行动以达成目标。
LLM没有这个能力。
它只能“回放”过去见过的语言模式,无法“想象”未发生的情境。
智能的本质,不是回答问题,而是解决问题;
不是复述知识,而是构建对世界的可操作理解。
2. “AI对齐”是错误的思维方式:
你对齐的是谁?对齐什么?
现在,让我们直面一个被政策制定者、媒体和公众广泛接受的“常识”:
我们必须让AI与人类价值观对齐。
而杨立昆的回答是:
这是完全愚蠢的逻辑。
2.1 对齐的误区:把LLM当作未来AI的模板
当前“AI对齐”讨论几乎全部围绕LLM展开:
如何防止它输出冒犯性内容?
如何让它遵守道德准则?
如何用RLHF(人类反馈强化学习)微调其行为?
但杨立昆尖锐指出:
未来的AI不会基于LLM架构。
因此,用LLM的安全问题去推演通用智能的风险,是典型的“类比谬误”。
就像19世纪的人担心蒸汽机是否会“背叛主人”,却完全没意识到电力、内燃机、计算机才是真正的变革力量。
2.2 目标驱动系统 vs. 语言模仿系统
杨立昆提出,真正的智能系统将是目标驱动的(goal-driven):
它被设计用于完成特定任务(如“安全驾驶到目的地”);
它通过世界模型预测行动后果,并规划最优路径;
安全约束可作为硬性规则嵌入其推理过程(如“不得违反交通法规”)。
这种系统不需要“对齐价值观”,因为它根本没有“价值观”——它只有目标和约束。
对齐问题的本质,是把AI拟人化了。
而真正的AI,应该像工具一样可靠、可预测、可控制。
2.3 谁的价值观?谁来决定?
更深层的问题是:
“人类价值观”本身就是一个模糊、冲突、文化依赖的概念。
美国保守派与进步派对“公平”的定义截然不同;
中国、印度、沙特的社会规范存在巨大差异;
即使在同一国家,代际、阶级、地域的价值观也千差万别。
试图让一个全球部署的AI“对齐”某种统一价值观,要么导致文化霸权,要么陷入逻辑瘫痪。
杨立昆的解决方案是:
不要对齐,而要开放。
让不同社区基于开源模型构建符合本地需求的AI系统。
3. 开源是AI的必然归宿:
杨立昆断言:
所有AI最终将走向开源。
过去10年AI的爆炸式发展,核心驱动力不是某个天才的突破,而是研究的开放性:
论文公开(arXiv);
代码开源(GitHub);
模型共享(Hugging Face)。
这种“集体智慧加速器”使得创新呈指数级扩散。
杨立昆强调:“贡献越多,发展越快。”
然而,近年来趋势逆转:
Anthropic极度封闭;
Google从开放转向保守;
Meta的FAIR实验室也逐渐收紧。
西方正在自缚手脚。