为什么对比学习是核心根基?AI算法之道
当你第一次使用视觉语言模型(Visual Language Models, VLMs)时,它们简直像魔法一样。你上传一张特定汽车零件或某种稀有热带水果的照片,用普通的英文问一句“这是什么?”,它就能立刻给出答案——毫不犹豫,也不会弹出“不支持此类别”的错误提示。
但说实话,这种看似智能的表现背后,其实是一个相当简洁的核心理念。它并非通过像素级记忆来识别物体,而是通过对比来学习。它理解的是事物之间的关系,而非僵化的定义
这个理念就是对比学习,它正是驱动现代人工智能的真正引擎。若想理解我们如何从只能识别1000种物体的“笨拙”图像分类器,进化到能探讨抽象艺术的GPT-4o等智能模型,就必须读懂这场变革。
旧范式:基于固定类别的视觉训练
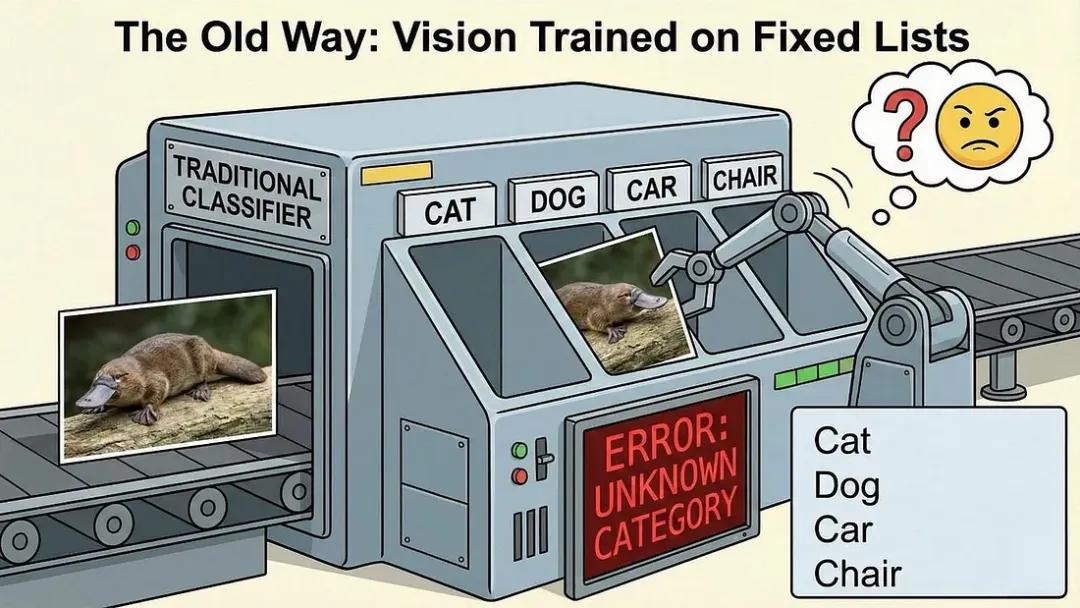
在过去(比如2018年,这在AI领域堪称远古时期),传统的计算机视觉模型以一种极为受限的方式学习。这基本上就像是为计算机准备的单项选择题测试,只不过计算机永远无法跳过问题或回答“我不知道”。
你输入一张图片,它就会输出一个标签。
该模型对世界的全部理解,都被限制在这些预定义的类别中,这些类别通常来自像包含大约1000个标签的ImageNet这样的数据集。可以把它想象成一个恰好有1000个插槽的邮件分拣机,每个插槽都在出厂时被编号和贴好标签。如果你寄出一个“鸭嘴兽”,但分拣机只有“海狸”和“鸭子”的插槽,机器就会不知所措。它会选择看起来最接近的那个,即使两者都完全不正确。
这种方法在处理特定、狭窄的任务时效果尚可,比如在自动驾驶中识别停车标志等。如果你的问题恰好符合那些预定义的类别,大家甚至可以获得95%以上的准确率。
但它无法扩展到现实世界。现实世界是杂乱无章、无限且不断演变的。你不可能为存在的每一个物体、场景、概念、风格或变体都列出其类别清单。那么“一个涂满涂鸦的生锈停车标志”呢?一幅“罗斯科风格的抽象表现主义画作”呢?或者一个“显示困惑的猫看着沙拉的迷因”呢?
旧范式之所以失效,是因为世界本身就没有固定的标签。而且,人类当然也不是以这种方式来体验视觉的。当你看到新事物时,你不会因为它在你的心理目录中不存在而认知失败。你会描述它,将它与你已知的事物进行比较,并通过上下文来理解它。旧的模型根本无法将鸭嘴兽识别为鸭嘴兽,因为它根本没有为它设置相应的插槽。
转变:学习关系而非标签
对比学习彻底颠覆了问题本身,这种方法事后看来似乎显而易见,但在当时却是革命性的。
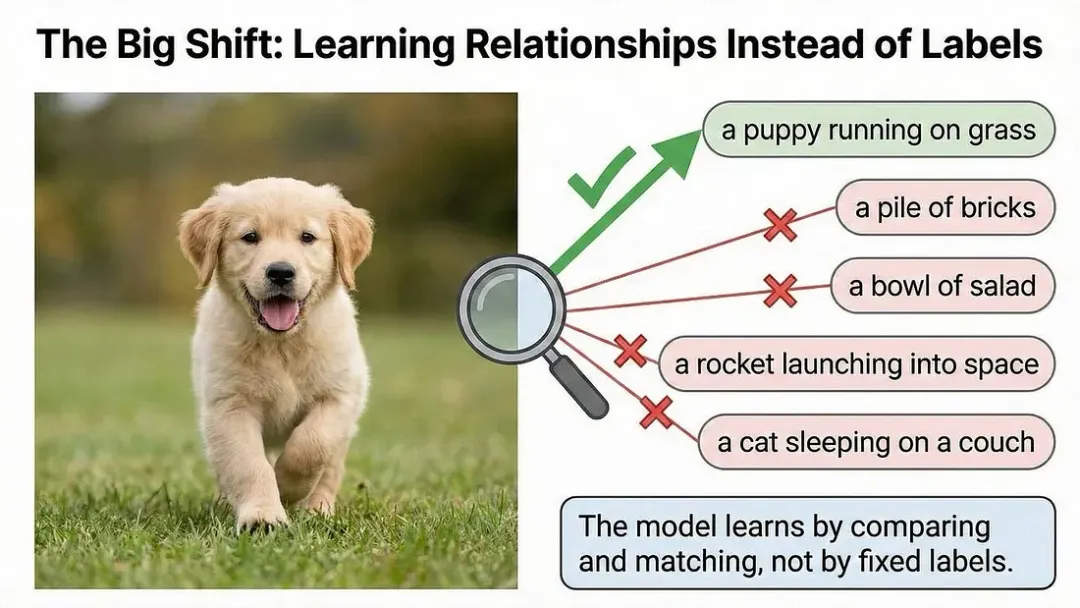
它不再问“这张图片属于哪个标签?”,而是让模型思考:“哪段文本描述与这张图片最匹配?”
同样重要的是,它还会问:“哪些文本与这张图片不匹配?”
它将学习过程变成了一场“找不同”或“配配对”的游戏,而不是死记硬背。模型会观察一张图片和一堆文本片段,然后试图弄清楚哪些是天然匹配的,哪些则不匹配。
这之所以至关重要,是因为它模仿了人类(作为儿童时)实际学习语言和视觉概念的方式。你并不是在记忆一个查询表。你是在看着狗的时候,反复听到“那是一只狗”,在不同情境下(大狗、小狗、奔跑的狗、睡觉的狗)听到数十次,然后你的大脑通过与“不是狗”的事物进行对比,学习到了模式,即“狗”的本质。
这里的洞见非常深刻:意义源于关系,而非定义。狗之所以是狗,并非因为它带有某种内在的“狗身份标签”,而是因为它与其他狗的相似度,要高于它与猫、马或自行车的相似度。语言也是如此。“狗”这个词的意义,源于它如何使用得与“猫”、“小狗”、“狼”等词语不同。
对比学习在大规模层面上实现了这一洞见。
具体工作原理
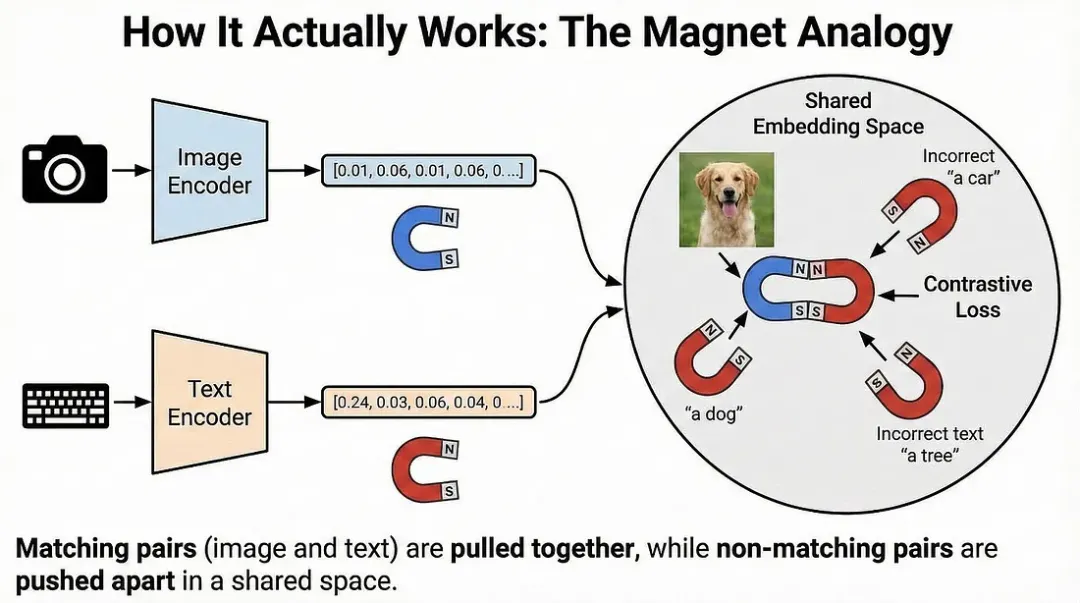
大家无需了解复杂的数学原理也能理解其核心思想,不过我们稍后还是会稍微深入探讨一下。现在,不妨把它想象成磁铁的作用。
从高层抽象来看,像CLIP(对比语言-图像预训练)这样的模型使用了两个编码器:
图像编码器:将图片转换成一串数字(一个向量)。可以把它看作是图像的512维或1024维。
文本编码器:将文本转换成位于同一维度空间中的一串数字。
为什么需要两个独立的编码器?
这两个编码器之所以从不同的架构开始,是因为图像和文本本质上是不同的数据类型。视觉处理通常使用针对二维结构调整的卷积网络或Transformer,处理按网格排列的像素。而文本处理则使用为序列化词元构建的Transformer模型,按顺序处理词语。
但关键在于:它们最终会投射到同一个共享空间中,这使得比较成为可能。训练过程迫使这两种截然不同的数据类型使用同一种数学语言。这就好比让一位西班牙语使用者和一位普通话使用者,都通过学习一种通用的中间语言来进行沟通。
“维度”到底意味着什么?
当我们说“512维向量”时,这意味着什么?每一个维度都捕捉了图像或文本的某个学习到的特征。有些维度可能大致对应我们能够识别的概念——比如“毛茸茸的程度”、“金属感的程度”或“户外的程度”——但大多数维度代表了我们难以命名的抽象模式。这些维度是模型通过训练自行发现的。可以把它们想象成512种衡量和描述图像或文本内容的不同方式。
投影头:最后的转换层
在编码器创建了它们的初始表示之后,这些向量会经过一个额外的小型神经网络,称为“投影头”。这最后一层将表示映射到实际发生比较的共享嵌入空间中。可以把它想象成一个翻译器,确保两种模态最终使用完全相同的“方言”,拥有相同的词汇和语法规则。
图像编码器可能自然地产生强调视觉纹理和颜色的向量,而文本编码器可能强调词语之间的语义关系。投影头则将它们重新塑造成一种可以直接进行有意义的比较的通用格式。
魔力在训练中发生
模型选取一张图像(比如一张金毛幼犬在草地上奔跑的照片),并将其与正确的标题配对:“一只在草地上奔跑的幼犬”。这是一个正样本对。
训练目标简单而强大:将这些向量拉近。就像磁铁的南北极相互吸引一样,模型调整其内部参数,使得图像的数值表示与文本的数值表示变得更加相似。
与此同时,它看着这张幼犬照片,并将其与批次中其他图像的随机标题(如“一堆砖头”、“一碗沙拉”、“一枚发射入空的火箭”)进行比较。这些是负样本对。
模型将这些向量推远,就像两个北极相互排斥一样。你希望不匹配的事物之间的距离最大化。
批处理如何创造规模化
这就是其效率变得显著的地方。在一个比如包含32,768张图像及其对应标题的训练批次中,你会自动获得32,768个正样本对(每张图像与其正确的标题)。但同时,你也会获得32,768 × (32,767) = 超过10亿个负样本对——批次中的每张图像都与所有其他标题进行比较。
这种海量的比较是并行发生的,这就是为什么现代对比学习需要强大的计算能力,但扩展效率却如此之高。模型并不是在进行数十亿个独立的训练步骤。它只处理一个批次,而在这个批次中,数十亿次比较会同时影响学习过程。
迭代式的精细化过程
这不是一次性的比较。模型在每个批次后,会按照减少损失的梯度方向,对数百万个内部权重进行微调。损失是衡量当前预测错误程度的数学指标。经过数千个批次和数十亿个示例的处理后,一个非凡的事物涌现出来:一个共享的嵌入空间。这是一个图像和语言能够共存的数学领域。
在这个空间里,一张金毛猎犬的照片最终会出现在短语“一只在外玩耍的狗”旁边。这个簇附近还有“小狗”、“寻回犬”、“宠物”等概念。它距离“跑车”、“摩天大楼”或“量子物理”则非常遥远。
模型并不是在死记硬背。它是在通过纯粹的对比,构建一幅意义的语义空间。
如果你好奇其内部机制,这里有一个简化的版本。
其核心函数被称为对比损失,通常特指InfoNCE损失。不用纠结这个名字。它的作用如下:
对于批次中的每张图像,模型会使用一种相似度度量方法(通常是余弦相似度,它衡量的是两个向量之间的夹角)来计算该图像与每一个文本描述的相似程度。
为什么偏偏用余弦相似度?
余弦相似度测量的是向量之间的角度,而忽略它们的长度(模长)。这之所以重要,是因为我们关心的是嵌入空间中的方向,而不是绝对大小。
想象两个向量指向不同方向的箭头。如果它们指向相同方向,就表示相似(余弦相似度为1)。如果指向相反方向,则表示不相似(余弦相似度为-1)。如果它们互相垂直,则表示不相关(余弦相似度为0)。
这种归一化处理至关重要。这意味着模型不会被诸如图像亮度(可能使所有像素值变大)或文本长度(可能使文本向量变长)等无关因素所迷惑。我们只关心语义方向。
模型希望正确的图像-文本对具有高相似度,而所有不正确的配对具有低相似度。每当一个正确配对的相似度不够高,或者一个错误配对的相似度太高时,损失函数就会惩罚模型。
这就产生了一种推拉动态。在训练过程中,模型不断进行调整,以最大化匹配对与非匹配对之间的差距。它正在学习判别性特征。是什么让狗明确地成为狗,不仅是在一般意义上,而且是特别地通过与“非狗”事物进行对比来体现的。
对比损失是对称的——它既将图像拉向文本,也将文本拉向图像。这种双向性至关重要。这意味着你之后可以在任一方向进行搜索:寻找与文本匹配的图像,或者寻找与图像匹配的文本。这种对称性正是逆向图像搜索、视觉问答和文本到图像检索等功能的基础。这种关系是双向的。
温度参数:控制置信度
还有一个显著影响学习过程的调节旋钮:温度参数(论文中通常记为 τ)。
模型使用这个“温度”设置来控制它需要达到的置信度。低温度意味着模型被迫做出尖锐的区分——正确配对必须比错误配对相似得多。模型会变得非常果断,其判断几乎是黑白分明的。
高温度则更为宽容,允许存在较模糊的边界。模型可以更加不确定,接受某些错误配对可能与正确配对有一定程度的相似性。这在训练初期,当模型仍在摸索时很有用。
这个看似不起眼的旋钮对模型的学习内容有着巨大影响。温度过低,模型可能会过度关注细微细节。温度过高,它学习到的表示可能过于粗略,从而错过重要的区分点。
这与传统的监督学习不同之处在于,你并不是在教模型一个单一的“正确答案”。你是在教它如何对选项进行排序。对于给定的图像,它更像“日落时分的海滩”还是更像“拥挤的地铁车厢”?模型通过数百万次这样的比较判断来学习。
这种排序方法出奇地稳健。即使标题并非完美(比如,一张严格来说是狼的图片,标题却写着“一只狗”),模型仍然能学到有用的东西,因为“一只狗”远比“一架直升机”要正确得多。