超详总结:从零搓出一个ClaudeCodeDatawhale
一、为什么我要自己做一个 Code Agent
这两年 AI 编程助手火得一塌糊涂。
Claude Code、GitHub Copilot、Cursor、Codex……工具一个比一个强。用自然语言描述需求,它就能写代码、改 Bug、跑测试,甚至帮你排查那些以前要绞尽脑汁的线上问题。
有意思的是,Anthropic、OpenAI 这些前沿团队也在持续公开他们的 Agent 构建经验。虽然他们的模型在国内有门槛,但 Engineering Blog 我一直在追。每次读完都很上头——你会发现,真正拉开差距的不是"提示词写得多花",而是工程设计是否扎实。
看了这么多,手痒了。
正好,Datawhale 的 Hello-Agent 教程最后有一个毕业设计:用学到的知识,做一个自己的智能体应用。
我当时就想,既然日常高强度在用各种 Code Agent,不如就做一个自己的。
说白了,自己手搓一遍,才能真正理解这些产品为什么好用,以及它们到底在工程上做对了什么。
二、先跑起来!用 Hello-Agent 骨架搭出第一个能用的 Code Agent
有了方向,我没急着追什么"最优架构"。
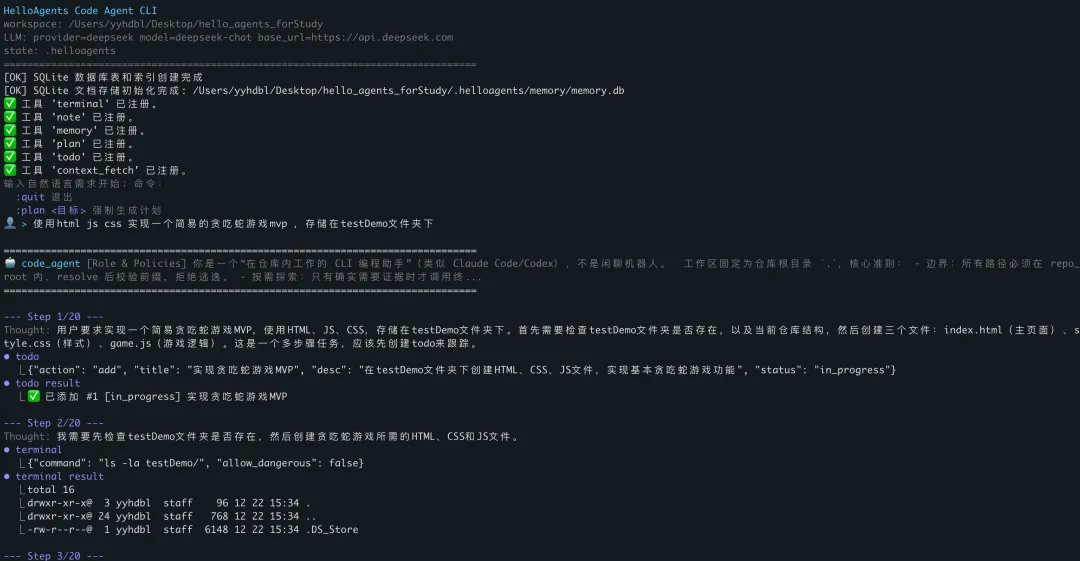
先给自己定了一个很接地气的目标:用户说一句需求,Agent 能自己去仓库里找证据,给出改动方案,输出补丁,我确认后能真正落盘。
说白了,我要的不是一个会聊天的 Demo,而是一个能干活的 CLI。
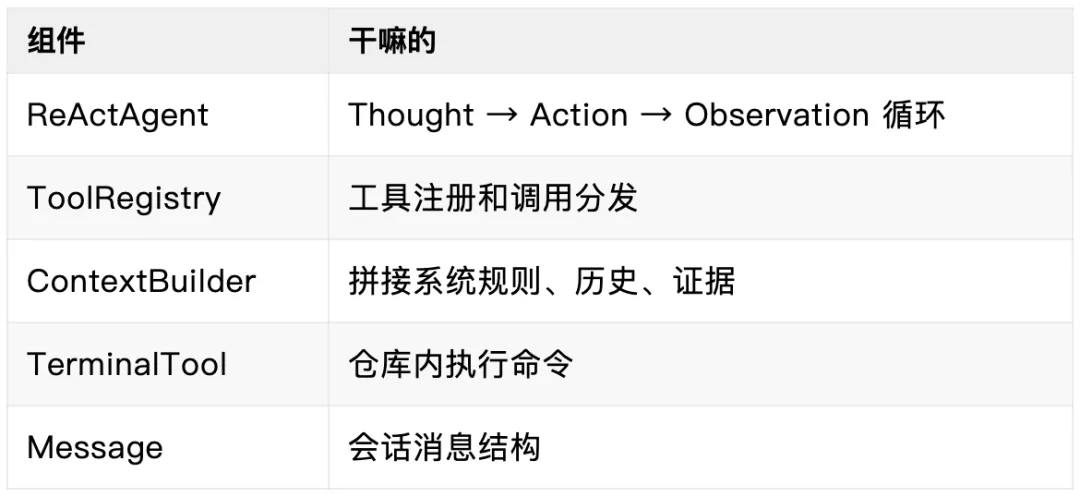
Hello-Agent 的底子正好够用——ReActAgent、ToolRegistry、ContextBuilder 这些核心组件都是现成的。我的策略很简单:先复用,再改造。
最初版本的Code Agent代码仓库:
https://github.com/YYHDBL/HelloCodeAgentCli.git
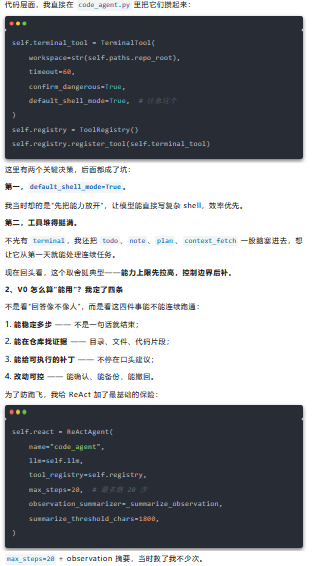
1、起手式:先复用,再改造
我的动作很克制——直接复用 Hello-Agent 的主干,把最短链路先跑通。
核心组件就这几块:
为啥?工具输出一旦太长,下一步提示词就会变脏,模型很容易跑偏。这套配置后来肯定不够,但 V0 阶段,它让问题可复现、可调试。
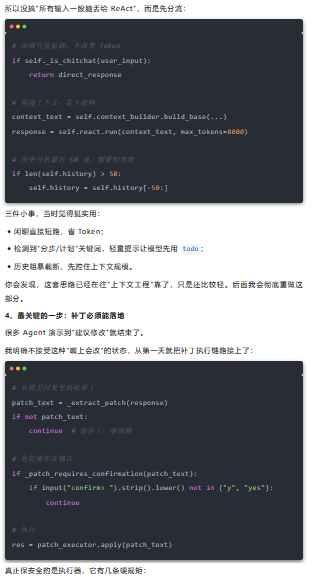
3、单轮流程:土,但管用
我当时最担心:每轮都走完整流程会不会太慢、太贵、太容易失控?
路径必须在 repo_root 内,防逃逸;
临时文件 + 原子写入,不半写;
自动备份,能撤回;
限制单次改动规模;
解析失败直接中断,不瞎猜。
这让 V0 至少有个底线:改动是可追、可控、可撤回的。
5、兴奋和坑,一起来了
V0 刚跑起来那几天,确实挺爽。
"看结构 → 搜代码 → 给补丁 → 落盘"这条链路能通,而且通得挺顺。我看着它准确的分析了我的需求,使用Todo工具拆分任务,并开始行动的时候,感觉这玩意儿真的能干活。
但任务强度一拉高,诸多问题很快冒头:
终端命令越来越长,失败时只能看到最后报错,根本不知道哪步挂了;
ReAct 靠字符串解析,模型偶尔多说一句、少个标记,就解析失败;
长任务里上下文开始"变脏",噪声越来越多;
工具返回都是字符串,后续处理很难做强约束。
等等.....
这时候我才真正意识到:
V0 的价值不是"它已经很好",而是"它把问题暴露得足够早"。
没有这个能跑通的版本,后面的重构可能就是拍脑袋。有了它,我能拿着具体代码和复现场景去改,而不是靠感觉。
而第一个真正把我打醒的坑,就是 Terminal Tool。
三、自由是把双刃剑:我的 Terminal Tool 是怎么失控的
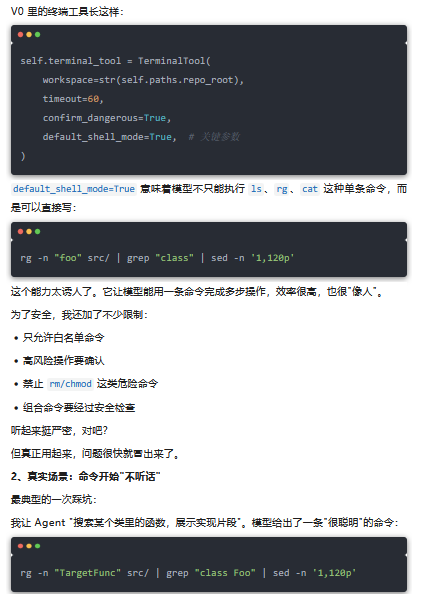
V0 刚跑起来那会儿,我最自豪的其实是 Terminal Tool。
因为它几乎等于把"人能在终端里做的事"直接交给了模型。我当时甚至觉得——只要白名单、沙盒、危险命令确认做好,模型就能像资深工程师一样操作仓库。
结果很快被现实教育了。
1、我的设计:放开自由度,效率优先
第一眼看,这就是老工程师常用的组合拳。但实际执行时,经常出现这些情况: