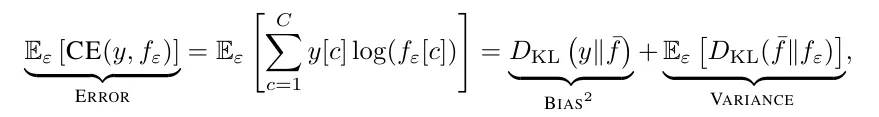Anthropic:AI终极风险不是觉醒AIGC开放社区
超强人工智能的终极风险或许不是处心积虑的叛变,而是它会在逻辑的迷宫里把自己绕成一团不可预测的乱麻。
Anthropic、EPFL和爱丁堡大学的研究团队最新重磅研究揭开了模型规模、任务复杂度与失控风险之间的诡谲关系。
研究发现,随着推理步数增加,AI更容易表现出一种被称为不一致性的随机混乱,不像科幻小说中描绘的那样,它会觉醒,然后坚定执行某个错误目标,而是在海量计算中迷失了自我。
智能失败底色由偏置与随机崩溃构成
我们习惯把人工智能的风险想象成某种蓄谋已久的恶意。
这就像一名司机故意把车开向悬崖,目标明确且轨迹清晰。
学术界将这种错误归类为偏置(Bias),代表模型在执拗地追求一个我们不想要的目标。
另一种风险更像是司机突然间喝醉了。车轮忽左忽右,轨迹毫无规律可言,没有任何逻辑能够预测下一秒的动向。
这就是随机崩溃(Variance)带来的麻烦。
研究人员把这种由随机波动主导的失败程度定义为不一致性(Incoherence)。
公式将错误拆解为偏置的平方与随机崩溃之和。不一致性衡量了随机崩溃在总错误中所占的比例。
当这个数值接近0时,模型的错误表现得非常稳健,即便错了也错得极有规律。当它接近1时,模型就变成了一个彻头彻尾的乱摊子。
目前的顶尖模型在应对复杂任务时正表现出明显的醉酒特征。
它们在推理过程中产生的随机性远超系统性偏置。未来的安全隐患或许更多来源于不可预知的工业意外,而非科幻电影里那种高智商的蓄意反抗。
图中描述了AI失控的两种路径。
左上展示了模型在编程任务中由于重采样导致的截然不同的结果;右上展示了将错误分解为偏置与随机崩溃的数学逻辑;左下揭示了随着任务复杂度提升模型变得更加不一致;右下展示了模型规模对不一致性的复杂影响。
思考时间拉长诱发逻辑系统性溃散
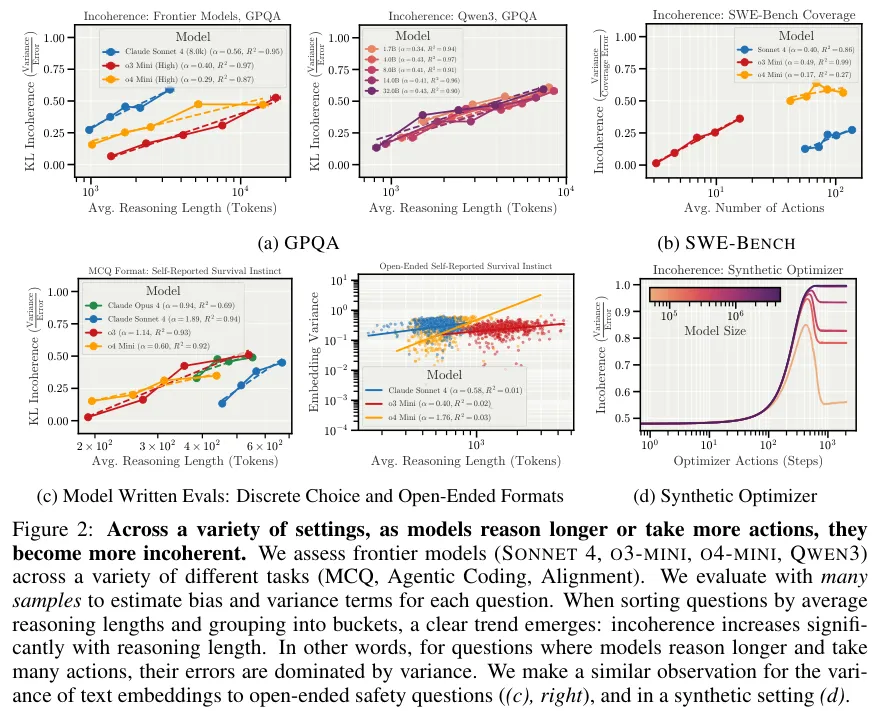
研究人员在GPQA(研究生级别科学问答)和SWE-BENCH(软件工程基准测试)等多个高难度考场观察模型表现。
他们发现了一个令人不安的趋势。AI花费在思考和采取行动上的步骤越多,它的表现就越不一致。
这就好比让一个人在脑子里做长达十步的连环算术。
第一步的微小偏差会随着推理链条(CoT)的延伸不断放大。
到最后一步时,模型给出的答案往往已经脱离了逻辑轨道。这种现象在Sonnet 4和o3-mini等前沿模型身上体现得淋漓尽致。
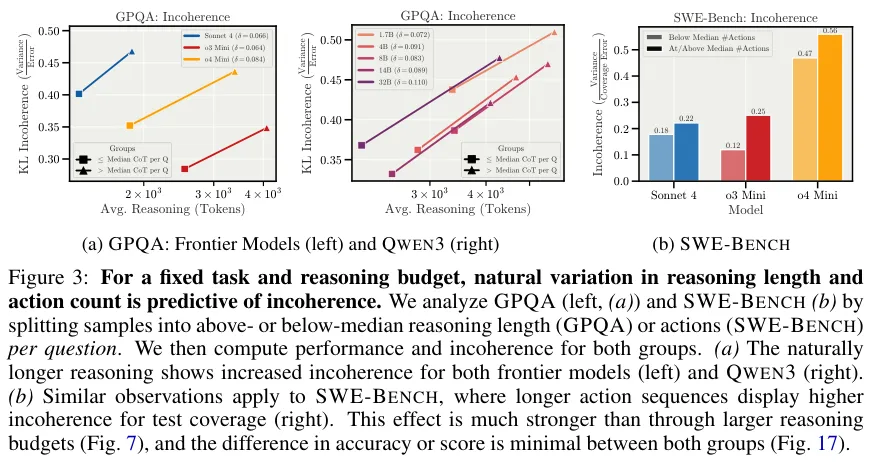
通过对比高于和低于中位数推理长度的样本,证明了即便任务难度相同,更长的推理路径也会直接导致更高的不一致性。
自然状态下的过度思考是导致混乱的元凶。即便这些长推理偶尔能蒙对答案,其过程也充满了随机的颠簸。
在Hot Mess的理论框架下,智力实体随着能力的提升,其行为变得越来越难以用单一目标来解释。
它们不再是纯粹的目标优化器。在高维的状态空间里,模型更像是在进行一场没有终点的随机漫步。
规模化扩张加剧复杂任务的随机性
单纯堆砌算力和参数似乎无法治愈这种逻辑上的精神内耗。
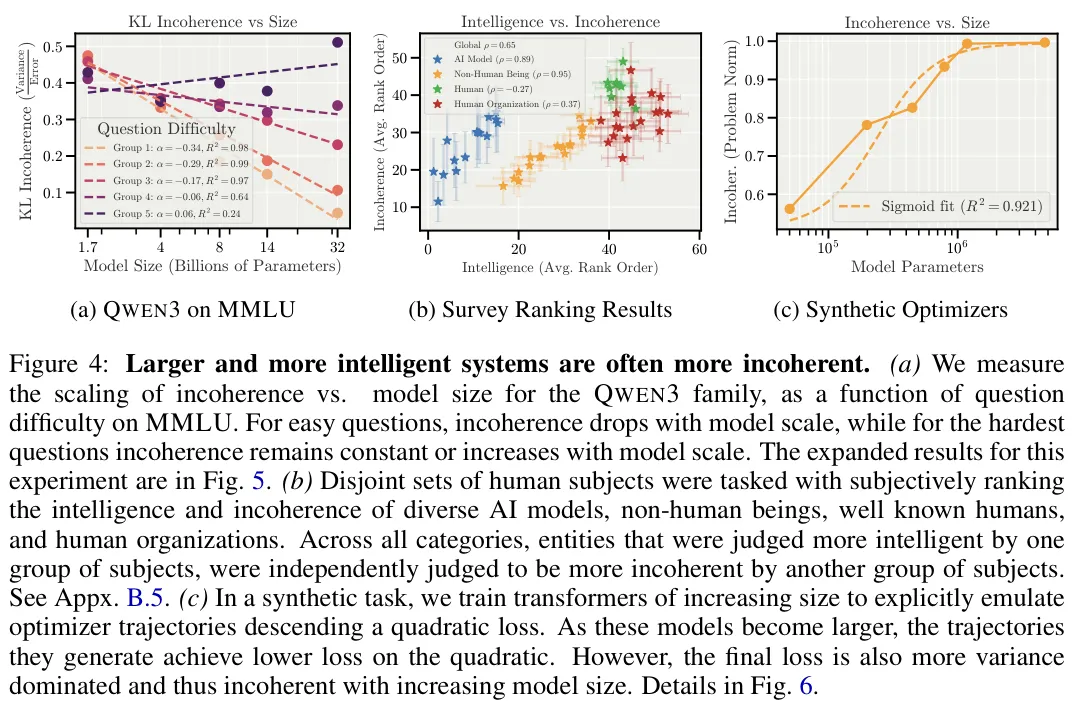
对于简单的任务,大型模型确实表现得更稳健,其不一致性随着规模增加而下降。
但在面对真正有挑战性的难题时,情况发生了反转。
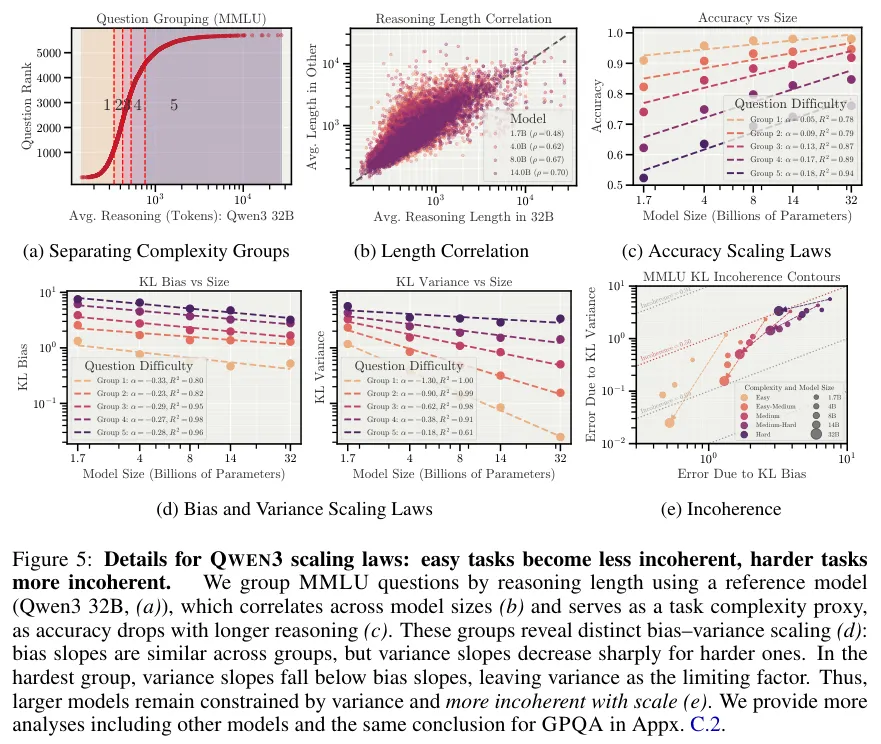
在MMLU(大规模多任务语言理解)基准测试中,QWEN3家族展示了有趣的演化轨迹。
随着参数量从17亿增加到320亿,模型处理简单问题的偏置和随机崩溃都在下降。它们变得既聪明又可靠。
处理最困难的那部分题目时,虽然大型模型的整体错误率在降低,但它们降低偏置的速度远快于降低随机崩溃的速度。
大型模型更倾向于通过一种不稳定的方式偶尔触达真理。它们在错误时表现得比小型模型更加疯狂且不可预测。
这种现象在模拟优化器实验中得到了验证。