姚顺雨腾讯第一篇:AI为啥死活听不懂人话?字母AI
今天的大语言模型能解奥数题、通过专业考试、写复杂代码,但它们在真实世界的应用中却常常“翻车”。问题出在哪里?
在姚顺雨加入腾讯后发布的首篇论文里,他对于这个现象提出了一个观点:
“当前AI与真正智能之间的鸿沟,不在于知识的多少,而在于学习的能力。一个装满知识却不会学习的AI,就像一个背了整本字典却不会写作的人,看起来博学,实则僵化。”
这篇论文的标题叫做《CL-bench: A Benchmark for Context Learning》。
CL-bench是一个专门评测语言模型“上下文学习能力”的大规模基准测试集,它的全称是Context Learning Benchmark,即上下文学习测试集。
它包含500个复杂上下文场景、1899个任务和31607个评估标注点,所有内容均由各个领域资深专家精心挑选。
这个基准的核心设计理念,是挑选那些在模型的预训练数据中不存在的难题,让每个任务都必须要求模型从提供的上下文中学习全新的知识才能解决。
这篇论文不仅揭示了当前AI的根本性缺陷,还构建了一个专属于AI的评价体系,非常值得AI以及agent从业者学习。
一面照出AI“假学习”真相的镜子
从数据规模来看,CL-bench的每个上下文平均包含3.8个任务,最多可达12个任务。
更重要的是,500个复杂上下文场景中,包含序列依赖性任务的场景占51.1%。
这也就是说,你想要AI解决后面的任务,那就必须先从前面的任务中得到正确的答案,这种多轮交互设计极大增加了难度。
单任务标注平均需领域专家20小时,每个任务平均配备16.6个评估标注项,从事实正确性、计算准确性、程序正确性、内容完整性和格式合规性等多个维度进行严格验证。
CL-bench考的不是AI记住了多少知识,而是AI能不能像人类一样,拿到一份新材料后快速学会并正确使用。
这些任务有个共同点,AI必须靠临场发挥才能通过考试。
预训练时学到的知识在这里用处不大,因为CL-bench里的知识要么是专家们新编的,要么是现实世界中极其小众的内容。
那如何保证CL-bench里的新知识是模型原来就没有的呢?
论文通过消融实验验证了这一点。在不提供上下文的情况下,所有被测模型只能解决不到1%的任务。这充分证明了任务对上下文的依赖性。
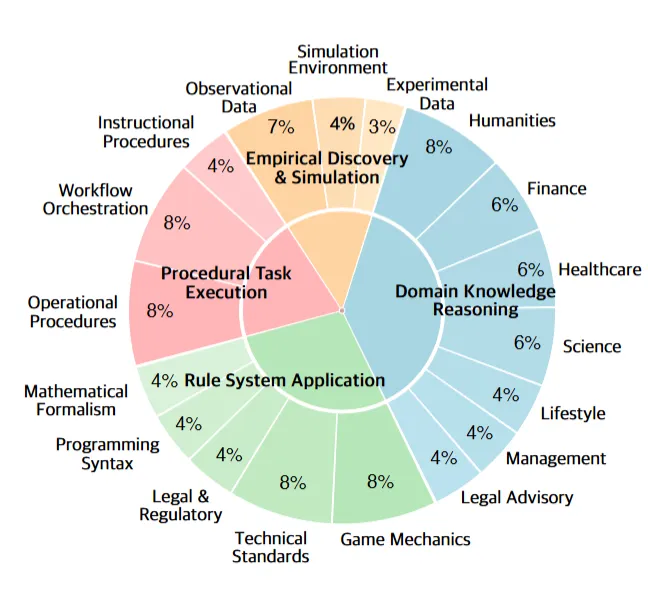
CL-bench将上下文学习场景分为四大类别,每类对应不同的认知要求:
领域知识推理(Domain Knowledge Reasoning):涵盖金融、医疗、人文、法律咨询、生活方式、管理和科学七个子领域。
上下文提供专业领域知识,如虚构的法律体系、创新的金融工具或小众专业知识,模型需要学习并应用这些知识进行推理。比如给AI一个虚构国家的完整法律条文和判例,让AI判罚一起复杂的民事纠纷。
规则系统应用(Rule System Application):包括游戏机制、数学形式体系、编程语法、法律法规和技术标准五个子类。
上下文提供明确定义的规则系统,模型必须理解并严格遵守这些规则。比如给定一门全新编程语言的语法规范,让模型编写符合规范的程序;或者给定一套新游戏的完整规则手册,让模型分析游戏状态并给出最优策略。
程序性任务执行(Procedural Task Execution):分为教学程序、操作程序和工作流编排三类。
上下文提供复杂的操作流程、产品手册或工作流程,模型需要学习并正确执行这些程序。例如给定一份无人机物流系统约7000字的API文档,让模型将自然语言指令转换为安全合规的伪代码。
经验发现与模拟(Empirical Discovery & Simulation):是最具挑战性的类别,包括实验数据、观测数据和模拟环境三个子类。
与前三类强调演绎推理不同,这一类要求归纳推理。从大量数据中发现潜在规律,或在虚拟环境中进行推理和决策。比如给定300份带电粒子在磁场中运动的实验日志,让模型推导出运动规律并计算特定参数。
这四类场景基本覆盖了人类在现实工作中遇到的主要学习情境,而CL-bench又把这些真实场景搬进了评测体系。
说得更直白些,领域知识推理考的是“能不能学会新概念”,规则系统应用考的是“能不能遵守新规则”,程序性任务执行考的是“能不能照着新流程做事”,经验发现与模拟考的是“能不能从数据里找规律”。
这四种能力,人类在日常工作中天天用,但AI显然还没学会。
为了确保测试的是真正的学习能力而非记忆,CL-bench采用了严格的“防污染”设计:
虚构创作:所有的测试内容都是由专家们完全原创的。
就拿刚才的虚拟国家为例,它包含一套完整的宪法、民法、刑法,甚至连判例都有。其中的法律原则和判例逻辑与现实世界任何国家都不同。
或者创造一门名为“EduScript”的教育编程语言,具有独特的语法规则和控制结构。
现有内容修改:CL-bench还对真实知识进行了系统性地改动,比如修改著名历史事件的因果关系、改变物理定律的数学表达、或调整技术标准的具体参数。
这确保了即使模型见过类似内容,也无法直接套用预训练知识。
小众新兴内容整合:CL-bench里面还纳入了预训练数据中极少出现的内容,就像2024年后发布的新产品技术文档、最新的科研论文发现、或极其专业的小众领域知识。
这三招组合拳,目的只有一个,让AI没法作弊。你不能靠背过的知识答题,必须现场学。这就像考试时老师突然换了一套从没见过的题型,你只能靠理解能力和学习能力来应对。
论文通过消融实验验证了这一设计的有效性:在不提供上下文的情况下,即使是最强的 GPT-5.1 模型也只能解决不到 1% 的任务,充分证明了任务对上下文的依赖性。
CL-bench给出的结果
让人们既开心又难过
CL-bench的这套评估体系的严格程度超出想象。
16.6个评估标注项意味着什么?意味着你不能只答对大方向,每个细节都要对。就像做数学题,你不仅要答案对,步骤也要对,格式还要对,引用的公式也要对。任何一个环节出错,整道题就算错。
这些标准会从六个角度检查AI的答案,每个标准要么对,要么错,没有中间地带。
事实对不对?比如AI说这个虚构国家的宪法第3条规定了什么,得和上下文里写的一模一样才算对。
计算对不对?如果任务要求计算带电粒子的运动轨迹,那每一步公式、每一个数字都得验证。