AI编程真面目:完整项目通过率仅27%量子位
AI编程是一项非常有实用价值的能力,但网络上不时也能看到程序员抱怨AI“听不懂人话”、“难以找到根本问题”,更有直接建议“每次生成代码不要超过5行”的经验分享。
而近期又有很多AI工具声称可以从零快速构建完整代码项目。
所以AI编程智能体真的能从零构建完整软件项目吗?近日一多校联合研究团队针对这一问题进行了探索。
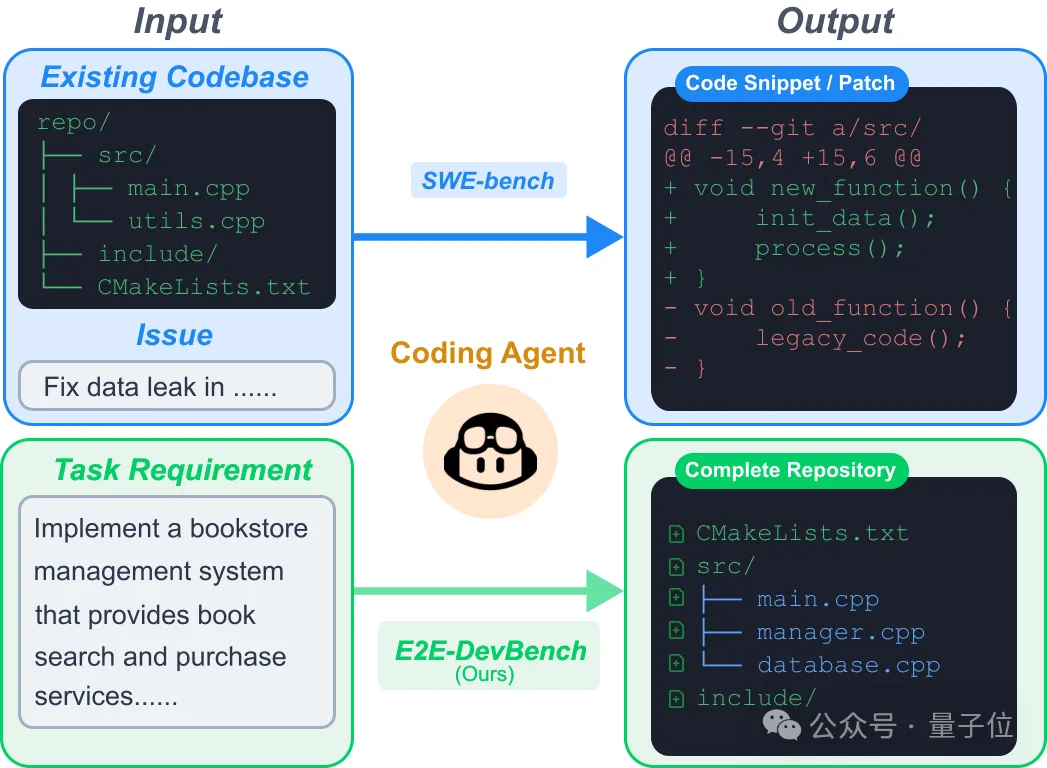
上海交通大学、上海创智学院、加州大学默塞德分校、北京理工大学(按论文作者顺序)联合发布ProjDevBench——首个通过OJ细粒度反馈评估AI编程智能体端到端项目开发能力的基准测试,要求智能体仅凭自然语言需求文档,从零开始构建完整、可运行的软件仓库。
当任务从“补全现有代码”变为“从零构建”时,性能出现断崖式下跌。
结果令人深思:所有智能体总体提交AC率仅27.38%。
该研究得出的结论摘要:
六种主流编程智能体(Cursor、GitHub Copilot、Claude Code等)的总体提交AC率仅为27.38%,在从零构建任务中性能大幅下滑。
OJ提供的细粒度诊断反馈(编译错误(CE)、运行时错误(RE)、超时(TLE)、内存超限(MLE)、答案错误(WA)等)是评估端到端开发能力的关键组成部分,远优于传统的pass/fail二元判定。
交互轮次与性能呈强负相关(-0.734),智能体在遇到困难时陷入低效试错循环,而非通过反思实现突破。
为什么需要端到端项目开发基准
现有基准测试如HumanEval、MBPP聚焦于函数级代码生成,SWE-bench关注issue修复,但真实软件工程需要的远不止这些。当开发者使用Cursor或GitHub Copilot进行“vibe coding”时,他们期望智能体能够:从零设计系统架构、创建和组织多个源文件、配置依赖和构建系统(如CMakeLists.txt)、最终交付一个可编译运行的完整项目。
这种端到端的项目构建能力此前从未被系统性评估过。ProjDevBench填补了这一空白。
与传统基准的本质区别在于:HumanEval等要求智能体补全代码片段,SWE-bench要求修复现有代码库中的bug,而ProjDevBench要求智能体像真正的软件工程师一样,在没有任何初始代码模板的情况下,自主完成从架构设计到多文件编码的全流程。
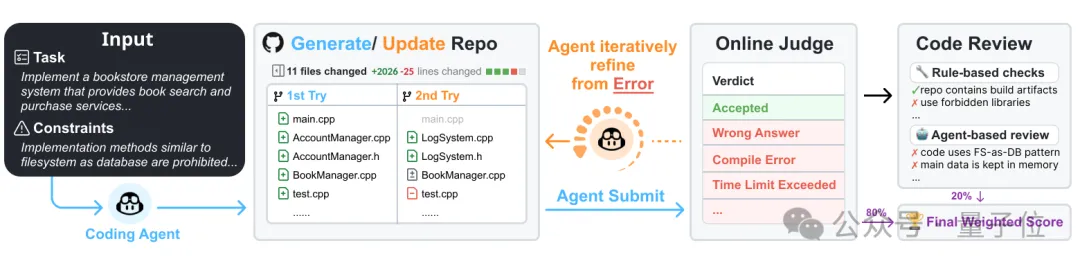
双重评估机制:OJ测试 + 代码审查
与以往仅返回pass/fail的测试不同,ProjDevBench采用双轨制评估:
OJ执行评分(80%):通过在线判题系统进行严格的黑盒测试,提供细粒度诊断信号——编译错误(CE)、运行时错误(RE)、超时(TLE)、内存超限(MLE)、答案错误(WA)等。这些信号支持智能体进行迭代调试,模拟真实开发中“编写代码-遇到报错-修改代码”的循环。
代码审查评分(20%):结合规则脚本和LLM模拟的代码审查,检测OJ测试无法捕捉的问题:是否违反显式规则(如使用禁止的库)、是否存在作弊解法、是否利用测试套件漏洞而非遵循实际约束。
这种设计的核心洞察是:仅靠测试用例无法全面评估代码质量。一个能通过所有测试的解法,可能采用了投机取巧的方式,而非真正理解并遵循问题规范。完整流程如下图所示:
任务设计与数据来源
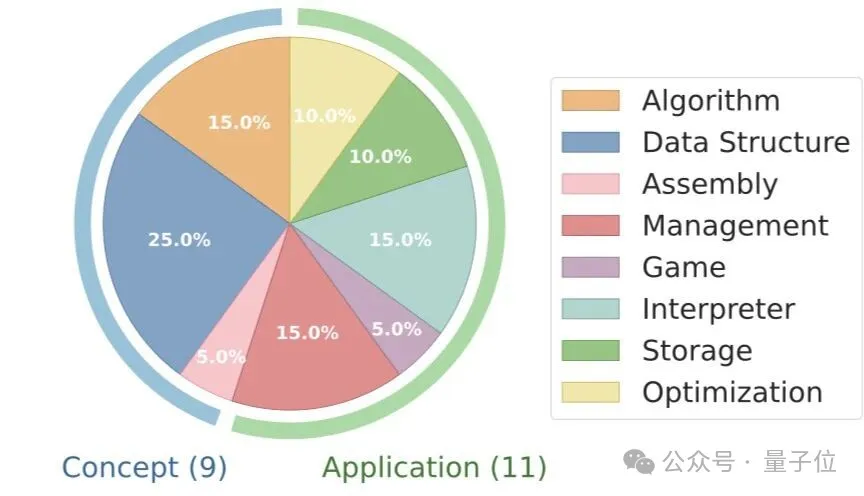
研究团队从上海交通大学ACM班(https://acm.sjtu.edu.cn/home)的在线判题平台精选20道高难度编程项目,涵盖算法、数据结构、解释器、管理系统、存储组件等8大类别。
这些题目经过三阶段筛选: